泰坦尼克号专题

计算机视觉实验二:基于支持向量机和随机森林的分类(Part two: 编程实现基于随机森林的泰坦尼克号人员生存与否分类)
目录 一、实验内容 二、实验目的 三、实验步骤 四、实验结果截图 五、实验完整代码 一、实验内容 编程实现基于随机森林的泰坦尼克号人员生存与否分类,基本功能包括:Titanic - Machine Learning from Disaster数据集的下载;数值型数据和文本型数据的筛查、舍弃、合并、补充;随机森林的人员生存与否分类。 二、实验目的
tensorflow泰坦尼克号沉船数据预测模型
首先下载数据 https://www.kaggle.com/c/titanic/data kaggle上面的数据 import pandas as pd import numpy as np import os,sys os.getcwd() data = pd.read_csv(’./tt/train.csv’) data.columns data = data[[‘Survived’, ‘P

泰坦尼克号数据集机器学习实战教程
泰坦尼克号数据集是一个公开可获取的数据集,源自1912年沉没的RMS泰坦尼克号事件。这个数据集被广泛用于教育和研究,特别是作为机器学习和数据分析的经典案例。数据集记录了船上乘客的一些信息,以及他们是否在灾难中幸存下来。以下是数据集中主要指标的详细介绍: 数据集来源: 数据集最初由Andrew Gelman等人收集整理,用于统计建模的教学。现在,它通常可以从Kaggle等平台获取。 数据集结构:
泰坦尼克号乘客生存情况预测分析2
泰坦尼克号乘客生存情况预测分析1 泰坦尼克号乘客生存情况预测分析2 泰坦尼克号乘客生存情况预测分析3 泰坦尼克号乘客生存情况预测分析总 背景描述 Titanic数据集在数据分析领域是十分经典的数据集,非常适合刚入门的小伙伴进行学习! 泰坦尼克号轮船的沉没是历史上最为人熟知的海难事件之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在船上的 2224 名乘客

kaggle 泰坦尼克号2 得分0.7799
流程 导入所要使用的包引入kaggle的数据集csv文件查看数据集有无空值填充这些空值提取特征分离训练集和测试集调用模型 导入需要的包 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarni

《阿凡达》《泰坦尼克号》
翻看以前的校内日志,愿意再看一遍的文章寥寥无几,下面这篇算是我之前写过的最喜欢的一篇文章了。还能从文中看到以前的率真,把话说的绝对时不知道脸红,表露对别人的崇拜时也不难为情。网络时代,3年前与3前后,能从文中看到一个人的哪些变化。如果想看更好的文字排版,可以访问我的Farbox个人博客网站。 2010年1月15号,怀着对詹姆斯-卡梅隆的极度推崇,我来到了北京三家拥有Imax屏幕
sklearn中决策树算法实例--泰坦尼克号人员生存预测
目录 数据集 题目 算法步骤 数据集 下载地址 titanic.csv · Yuyi Ye/ML-Decision-Tree - 码云 - 开源中国 (gitee.com) 题目 根据数据集中的数据,预测哪些乘客可以从泰坦尼克号沉船事故中幸免。 算法步骤 import pandas as pdimport numpy as npfrom sklearn.model_

kaggle 泰坦尼克号1(根据男女性存活率)
kaggle竞赛 泰坦尼克号 流程 下载kaggle数据集导入所要使用的包引入kaggle的数据集csv文件查看数据集的大小和长度去除冗余数据建立特征工程导出结果csv文件 1.下载kaggle数据集 2.导入所要使用的包 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seabo
泰坦尼克号预测如何做到Kaggle排名前2%
转载自:http://www.jasongj.com/ml/classification/ 做机器学习其实最重要的就是特征工程,对特征进行适当的分析处理、组合、扩充等等,将会带来远超过不同算法带来的提升。下面就来看一个通过合理调整特征,来达到泰坦尼克号较好预测的案例。 摘要 本文详述了如何通过数据预览,探索式数据分析,缺失数据填补,删除关联特征以及派生新特征等方法,在Kaggle的Titan

泰坦尼克号幸存者数据分析
泰坦尼克号幸存者数据分析 1、泰坦尼克号数据集2、数据集加载与概览3、泰坦尼克号幸存者数据分析4、哪些人可能成为幸存者? 1、泰坦尼克号数据集 泰坦尼克号的沉没是世界上最严重的海难事故之一,造成了大量的人员伤亡。这是一艘号称当时世界上最大的邮轮,船上的人年龄各异,背景不同,有贵族豪门,也有平民旅人,邮轮撞击冰山后,船上的人马上采取措施安排救生艇转移人员,从本次
scikit-learn 决策树预测泰坦尼克号幸存者
决策树的使用手册 http://sklearn.apachecn.org/cn/0.19.0/modules/tree.html 决策树预测结果容易理解,易于解释,预测速度快。 基于Entropy的分类: ID3, C4.5, C5.0,运算效率更高,使用内存更小,创建出来的决策树更小,准确性高,适合大数据集的决策树创建; 基于gini不纯度: CART,分类回归树。 sklear

机器学习——泰坦尼克号乘客生存预测(超详细)
🔥博客主页:是dream 🚀系列专栏:深度学习环境搭建、环境配置问题解决、自然语言处理、语音信号处理、项目开发 💘每日语录:人不是因为没有信念而失败,而是因为不能把信念化成行动,并且坚持到底。 🎉感谢大家点赞👍收藏⭐指正✍️ 目录 前言 一、数据集收集 二、数据分析 1、基本数据分析 (1)数据类型观察 (2)数据分布情况 2、初步数据分析 3

项目:泰坦尼克号数据集项目
概述 我们都熟悉泰坦尼克号,这艘不沉的船,它于 1912 年进行了第一次也是最后一次航行。尽管泰坦尼克号是为了不沉没而设计的,但没有足够的救生艇供每个人使用。最终导致2224名乘客和机组人员中的1502人死亡。 泰坦尼克号数据集 根据泰坦尼克号乘客整理的数据集,例如他们的年龄、阶级、性别等来预测他们是否会幸存。虽然生存有一定的运气成分,但似乎某些群体比其他群体更有可能生存。 我们正在建设

【机器学习实战1】泰坦尼克号:灾难中的机器学习(一)数据预处理
🌸博主主页:@釉色清风🌸文章专栏:机器学习实战🌸今日语录:不要一直责怪过去的自己,她曾经站在雾里也很迷茫。 🌼实战项目简介 本次项目是kaggle上的一个入门比赛 :Titanic——Machine Learning from Disaster(泰坦尼克号——灾难中的机器学习),比赛选择了泰坦尼克号作为背景,并提供了样本数据以及测试数据,要求我们使用机器学习创建一个模型,预测哪些
机器学习——泰坦尼克号乘客生存预测(超详细)
🔥博客主页:是dream 🚀系列专栏:深度学习环境搭建、环境配置问题解决、自然语言处理、语音信号处理、项目开发 💘每日语录:人不是因为没有信念而失败,而是因为不能把信念化成行动,并且坚持到底。 🎉感谢大家点赞👍收藏⭐指正✍️ 目录 前言 一、数据集收集 二、数据分析 1、基本数据分析 (1)数据类型观察 (2)数据分布情况 2、初步数据分析 3、
Kaggle--泰坦尼克号失踪者生死情况预测源码(附Titanic数据集)
数据可视化分析 import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as nptitanic=pd.read_csv('train.csv')#print(titanic.head())#设置某一列为索引#print(titanic.set_index('Passe
案例系列:泰坦尼克号_预测幸存者_TensorFlow决策森林
文章目录 1. 导入依赖库2. 加载数据集3. 准备数据集4. 将Pandas数据集转换为TensorFlow数据集5. 使用默认参数训练模型6. 使用改进的默认参数训练模型7. 进行预测8. 使用超参数调优训练模型9. 创建一个集成模型 TensorFlow决策森林在表格数据上表现较好。本笔记将带您完成使用TensorFlow决策森林训练基线梯度提升树模型并在泰坦尼克号竞赛中提交的
HTML5期末大作业:电影介绍网站设计——电影泰坦尼克号带特效带音乐(4页) HTML+CSS+JavaScript...
常见网页设计作业题材有 个人、 美食、 公司、 学校、 旅游、 电商、 宠物、 电器、 茶叶、 家居、 酒店、 舞蹈、 动漫、 明星、 服装、 体育、 化妆品、 物流、 环保、 书籍、 婚纱、 军事、 游戏、 节日、 戒烟、 电影、 摄影、 文化、 家乡、 鲜花、 礼品、 汽车、 其他 等网页设计题目, A+水平作业, 可满足大学生网页大作业网页设计需求, 喜欢的可以下载
基于决策树的泰坦尼克号数据集回归预测
目录 1、作者介绍2、决策树算法2.1 决策树原理2.1.1 基本原理2.1.2 节点的概念 2.2 构建决策树2.3 决策树优缺点 3、实验设计3.1 数据集简介3.2 代码实现3.3 运行结果 4、参考链接 1、作者介绍 任正福,男,西安工程大学电子信息学院,2022级研究生 研究方向:混响背景下目标回波检测 电子邮件:1214061716@qq.com 陈梦丹,女,西安工
sklearn教程:titanic泰坦尼克号数据集
文章目录 数据集介绍导入数据集info()显示数据类型和是否缺失describe()数据描述性统计 数据可视化-探索性分析EDA填充缺失值之后的可视化类别变量的相关关系 数据集介绍 这个数据集是基于泰坦尼克号中乘客逃生的,泰坦尼克号出事故,船上的乘客的一些信息被记录在这张表中。现在要根据这个数据预测这个人能否获救。共有891个样本。 数据集属性 属性含义Passen
深度学习之构建MPL神经网络——泰坦尼克号乘客的生存分析
大家好,我是带我去滑雪! 本期使用泰坦尼克号数据集,该数据集的响应变量为乘客是生存还是死亡(survived,其中1表示生存,0表示死亡),特征变量有乘客舱位等级(pclass)、乘客姓名(name)、乘客性别(sex,其中male为男性,female为女性)、乘客年龄(age)、兄弟姊妹或者配偶在船上的人数(sibsp)、父母或子女在船上的人数(parch)、船票号码(

kaggle|泰坦尼克号生存预测
kaggle|泰坦尼克号生存预测 1.数据分析初步分析分类观察可视化观察 2.数据处理数据字符替换缺失值填充1.Age2.port3.fare 组合新特征 3.建立模型Random ForestDecision TreeKNNSupport Vector MachinesLogistic RegressionLinear SVCPerceptronStochastic Gradient De
![[B3]泰坦尼克号数据分析](https://img-blog.csdnimg.cn/20191120002101566.png)
[B3]泰坦尼克号数据分析
这是我做的第一个半完整的数据分析项目,里面包含数据获取,数据清洗,描述性统计,数据可视化,机器学习建模等内容。花了我两天时间,中间出了很多bug,而且原始数据也有问题,因此存在较多缺陷,还请各位大佬多多指教! 目录: 1.数据获取 2.数据预处理 3.描述性统计 4.变量分布统计 5.探索变量间的关系 6.特征处理 7.机器学习建模 8.模型准确性评估 第一步:数据获取 直接从互联网获取数据

学习记录|泰坦尼克号生存预测
【学习记录】 1.导入包,数据集 import numpy as np import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsplt.style.use('fivethirtyeight')import warningswarnings.filterwarnings('ignore')%mat
![[小白系列]通过pydot+GraphViz实现泰坦尼克号生存预测模型的决策树可视化](https://img-blog.csdnimg.cn/20200402091220406.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0thZWxDdWk=,size_16,color_FFFFFF,t_70#pic_center)
[小白系列]通过pydot+GraphViz实现泰坦尼克号生存预测模型的决策树可视化
具体GraphViz安装,请点击链接 import numpy as npimport pandas as pdfrom sklearn.tree import DecisionTreeClassifier # 从sklearn中导入决策树分类器模型from sklearn.feature_extraction import DictVectorizer # 特征抽取:将特征与值的映射
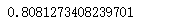
Kaggle实战入门(一)之泰坦尼克号
博主最近开始在Kaggle上做项目,第一个项目就是最经典的项目泰坦尼克号。在尝试了几种模型,调整了很多次之后,终于将模型调到0.8的得分,给大家分享一下我的做法。 Part1.数据导入和初步观察 导入泰坦尼克号训练集和测试集的数据,这次我选择同时处理两份数据,所以直接将他们拼接起来 import pandas as pdimport numpy as npimport matplotl