本文主要是介绍[B3]泰坦尼克号数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是我做的第一个半完整的数据分析项目,里面包含数据获取,数据清洗,描述性统计,数据可视化,机器学习建模等内容。花了我两天时间,中间出了很多bug,而且原始数据也有问题,因此存在较多缺陷,还请各位大佬多多指教!
目录:
1.数据获取
2.数据预处理
3.描述性统计
4.变量分布统计
5.探索变量间的关系
6.特征处理
7.机器学习建模
8.模型准确性评估
第一步:数据获取
直接从互联网获取数据
import pandas as pd
#利用pandas的read_csv模块直接从互联网搜集泰坦尼克号乘客数据
titanic= pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
观察前几行数据,可以发现数据种类各异。
第二步:数据预处理
#查看数据集的行列数
titanic.shape
#查看前3行数据
titanic.head(3)

第三步:汇总及描述性统计
#查看数据缺失值,数据类型等情况
titanic.info()

借以上输出,设计如下几个数据处理任务
(1)age这个数据列,只有633个,需要补完
(2)sex与pclass都是类别型的,需要转化为数值特征,用0/1替代
#首先补充age里的数据,使用平均数或者中位数都是对模型偏离造成最小影响的策略
titanic['age'].fillna(titanic['age'].mean(), inplace=True)#对补充完整的数据进行重新探查
titanic.info()

此时缺失值被我们补全
#统计每一列的均值。最大值,最小值,分位数等
titanic.describe(include='all')

以上输出可得知:约有34%的人获救了,乘客年龄平均31.1岁
第四步:变量分布统计
#1.获救情况分布,共1313位乘客,仅446人幸免遇难,占比34%
titanic['survived'].value_counts().plot(kind='bar',color='yellow',title='Rescue situation', rot=360)

#2.性别分布,共1313位乘客,男性乘客就有573位,占比43.64%
titanic['sex'].value_counts().plot(kind='bar',color='pink',title='Gender distrbution', rot=360)

#3.船舱分布,其中三等舱人数最多,一等舱人口次之
titanic['pclass'].value_counts().plot(kind='bar',color='green',title='GePclass distrbution', rot=360)

#接下来探索连续性变量age
#4.年龄分布,主要集中在20-40岁之间
titanic['age'].plot(kind='hist',color='pink',title='Age distrbution')

第五步:探索变量之间的关系
1.探索单个变量与survived的关系
由于地位高的人可能最先获得救助,表明age,sex与pclass可能是影响生存的关键因素
#首先通过分组和聚合两种机器学习函数来实现
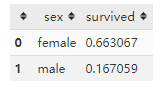
titanic[['sex','survived']].groupby(['sex'], as_index=False).mean().sort_values(by='survived', ascending=False)
#也可以通过透视表的方式来实现
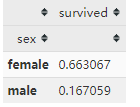
sex_pivot = titanic.pivot_table(index='sex',values='survived')
sex_pivot
import matplotlib.pyplot as plt
#构造sex与survived均值的条形图
sex_pivot.plot.bar(rot=360)

很显然女性的幸存比例明显高于男性
现在再来看pclass与survived的关系:
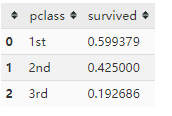
titanic[['pclass','survived']].groupby(['pclass'], as_index=False).mean().sort_values(by='survived', ascending=False)
class_pivot = titanic.pivot_table(index='pclass', values='survived')
class_pivot
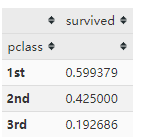
class_pivot.plot.bar(rot=360)

可见,一等舱幸存比例的确最高,表现出地位不平等关系
2.探索多个变量与survived之间的关系
import seaborn as sns
g= sns.FacetGrid(titanic, col='survived')
g.map(plt.hist, 'age', bins=20)

首先探索年龄与获救人数的关系:
获救人群中20-40岁的占比最多;遇难人群中18-30的占比最多
grid=sns.FacetGrid(titanic, col='survived',row='pclass', height=2.2, aspect=1.6)
grid.map(plt.hist, 'age',alpha=0.5,bins=20)
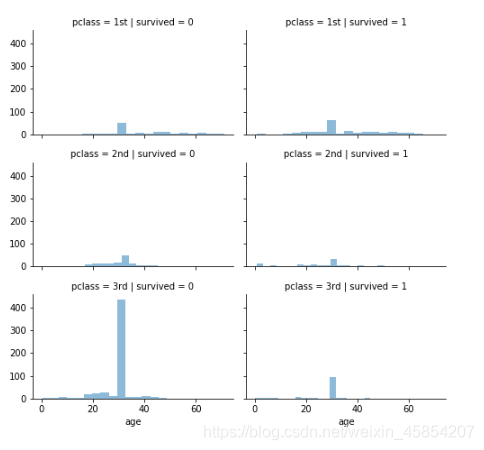
#探索年龄,舱位与获救人数的关系:
#一等舱获救人数最多
grid=sns.FacetGrid(titanic,row='embarked', height=2.2, aspect=1.6)
grid.map(sns.pointplot,'pclass','survived',palette='deep',order=[1,2,3], hue_order=['male','female'])
grid.add_legend()
这里图没有加载出来,出了个bug
由图可以看出:一等舱中从港口Q和港口S登船的女性基本都获救了,从C口登船的男性获救比例很高
第六步:特征处理
1.头衔转换
由于name列表中有不同的称呼如Mr,Dr等,代表了不同地位,因此我们单独把这一属性摘出来列成一列
titanic['Title'] = titanic['name'].str.extract('([A-Za-z]+)\.', expand=False)
#交叉表
pd.crosstab(titanic['Title'],titanic['sex'])
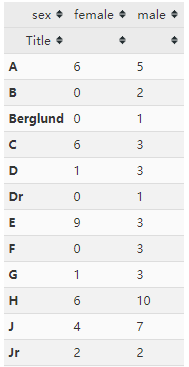
由于数据存在缺陷无法进一步分析;跳到下一步
2.年龄转换
通过Series.descibe()查看age列的概况
titanic['age'].describe()
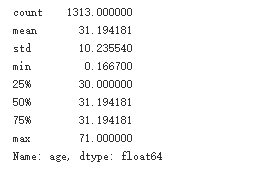
乘客年龄分布在0.16-71之间
由于年龄字段是一个连续变量,可以通过直方图查看其分布情况
使用布尔索引分别得到获救与未获救DataFrame
survived = titanic[titanic['survived']==1]
died = titanic[titanic['survived']==0]
#建立直方图查看不同年龄获救对比情况
survived['age'].plot.hist(alpha=0.5,color='red',bins=50)
died['age'].plot.hist(alpha=0.5,color='blue',bins=50)
plt.legend(['survived','died'])

可以看到幸存乘客年龄集中分布在30岁左右,遇难乘客也集中分布在这个年龄层次,当然不排除原始数据缺陷
接下来使用pandas.cut()函数将年龄字段进行分段,转换成类别变量:
先创建一个函数,使用pandas.fillna()方法用-0.5填充所有缺失值
将age变成六段
Missing, from -1 to 0
Infant,from 0 to 5
Child,from 5 to 12
Teenager, from 12 to 18
Young Aault,from 18 to 35
Adult, from 35 to 60
Senior, from 60 to 100
#定义年龄分段处理函数
def process_age(df, cut_points, label_names):df['age'] = df['age'].fillna(-0.5)df['age_categories'] = pd.cut(df['age'], cut_points, label_names)return dfcut_points = [-1,0,5,12,18,35,60,100]
label_names=['Missing','Infant','Child','Teenager','Young Aault','Adult','Senior']#在训练集上调用 process_age函数
titanic =process_age(titanic, cut_points, label_names)#查看分段后的年龄与生还的关系
pivot=titanic.pivot_table(index="age_categories", values='survived')
pivot.plot.bar(rot=360)
plt.show()
我这里又报错了,大佬们可以帮我看看啥原因

第八步:机器学习建模分析
1.分割训练数据
将训练集分成两个部分,20%的数据用来预测,80%的数据用来训练
通过sklearn中的model_selection.train_test_split()函数进行数据切割
包含两个参数,X指的是特征变量,y值得是目标变量,返回四个对象:train_X train_y test_X test_y
from sklearn.model_selection import train_test_split
#将要放入模型进行训练的特征变量:
columns = ['pclass_1', 'pclass_2', 'pclass_3', 'sex_female', 'sex_male','age_categories_Missing', 'age_categories_Infant', 'age_categories_Child','age_categories_Teenager', 'age_categories_Young Aault','age_categories_Adult', 'age_categories_Senior'
]
all_X =titanic[columns]#训练集的目标变量
all_y = titanic['survived']
train_X,test_X,train_y,test_y = train_test_split(all_X,all_y, test_size=0.20, random_state=0)
2.使用LogisticRegression建模
#导入sklearn里的LogisticRegression模型
from sklearn.linear_model import LogisticRegression
#创建LogisticRegression对象
lr = LogisticRegression()#使用LogisticRegression.fit()方法来训练模型
lr.fit(titanic[columns],titanic['survived'])
第九步:模型准确度评估
lr = LogisticRegression()
lr.fit(train_X,train_y)
predictions = lr.predict(test_X)
#使用metrics.accuracy_score()函数进行准确性评估
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(test_y,predictions)
print('The accuracy of LogisticRegression is:')
最后精确度应该在79%左右,说明模型预测还是比较准确的。
好了,今天的案例就给大家分享到这里了,做完一整个流程下来才发现自己要学习的东西太多了,希望以后能够不断进步,与君共勉!
这篇关于[B3]泰坦尼克号数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!