本文主要是介绍机器学习——泰坦尼克号乘客生存预测(超详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🔥博客主页:是dream
🚀系列专栏:深度学习环境搭建、环境配置问题解决、自然语言处理、语音信号处理、项目开发
💘每日语录:人不是因为没有信念而失败,而是因为不能把信念化成行动,并且坚持到底。
🎉感谢大家点赞👍收藏⭐指正✍️

目录
前言
一、数据集收集
二、数据分析
1、基本数据分析
(1)数据类型观察
(2)数据分布情况
2、初步数据分析
3、各属性与获救情况的关联
(1)性别和获救情况分析
(2)仓位等级与获救情况分析
(3)年龄与获救情况散点图
(4)登港口Embarked与生存情况分析
(5)直系亲友个数与乘客获救情况
(6)旁系亲友个数和乘客获救情况
(7)有无Carbin获救情况
整段代码
三、数据预处理
1、cabin缺失值的处理
2、Age缺失值的处理
3、Embarked缺失值的处理
4、特征因子化
5、姓氏
整段代码
四、模型搭建
1、逻辑回归建模
交叉验证优化
Bagging优化
所有代码
2、SVM建模
3、KNN建模
4、深度学习模型
5、总结
欢迎大家点赞关注和收藏,有疑问可以私信我!
前言
本文章是我在完成机器学习课程设计写的总结,共计花费五天左右,在kaggle平台上测试,最高的一次准确率为0.78708,希望大家可以继续优化。
在使用机器学习相关知识去处理某个实际的问题的时候首先就是从需求理解和问题预处理开始,通过异常数据收集、数据整合、数据分析探索,到模型训练和调优,最后进行模型验证评估。
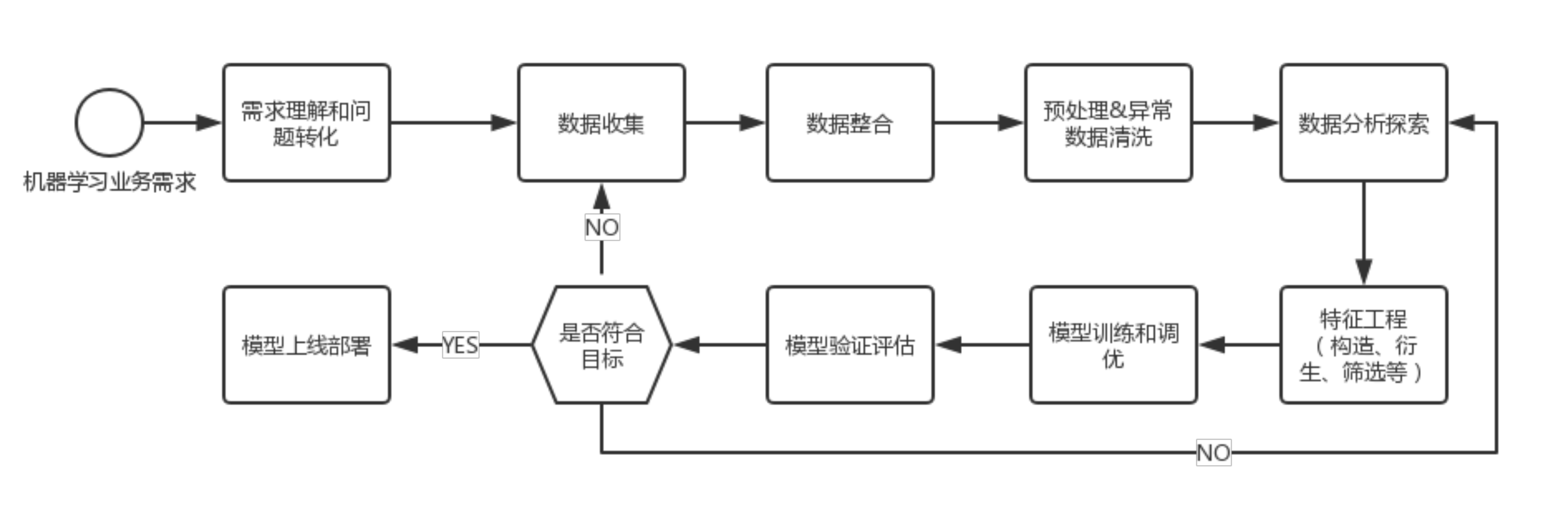
需求理解和问题预处理是整个流程的基础,在本次课程设计中,目标是判断乘客的生还率,怎样基于已有的特征来预测是否生还。
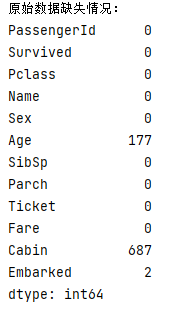
然后就是数据收集,这里我们用了kaggle平台上的数据集。但是这个数据集是不完整的这就需要我们对数据进行预处理和数据清洗。
需要数据进行清洗、整合和探索性分析,寻找数据的规律和特征,为模型的训练提供支持。在这里数据中存在缺失值,缺失值的填充方法有很多:
①如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
②如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
③如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
④有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
同时需要将数据进行因子化,这里我还将差值特别大的特征进行归一化,防止因为差值过大导致欠拟合。
接着就是模型构建,这里我选择了逻辑回归、KNN、SVM三种核函数、深度学习等算法,并进行了模型之间的对比,同时还使用了K折交叉验证,利用bagging算法进行模型融合,防止过拟合,输出预测错误的样本来进行模型调节等等。
一、数据集收集
数据集我是直接用kaggle上的数据集,大家可以自行获取。
链接:数据集![]() https://pan.baidu.com/s/1GjQwk9r6MXigFc8Op0xYdw?pwd=peng%C2%A0
https://pan.baidu.com/s/1GjQwk9r6MXigFc8Op0xYdw?pwd=peng%C2%A0
提取码:peng
二、数据分析
1、基本数据分析
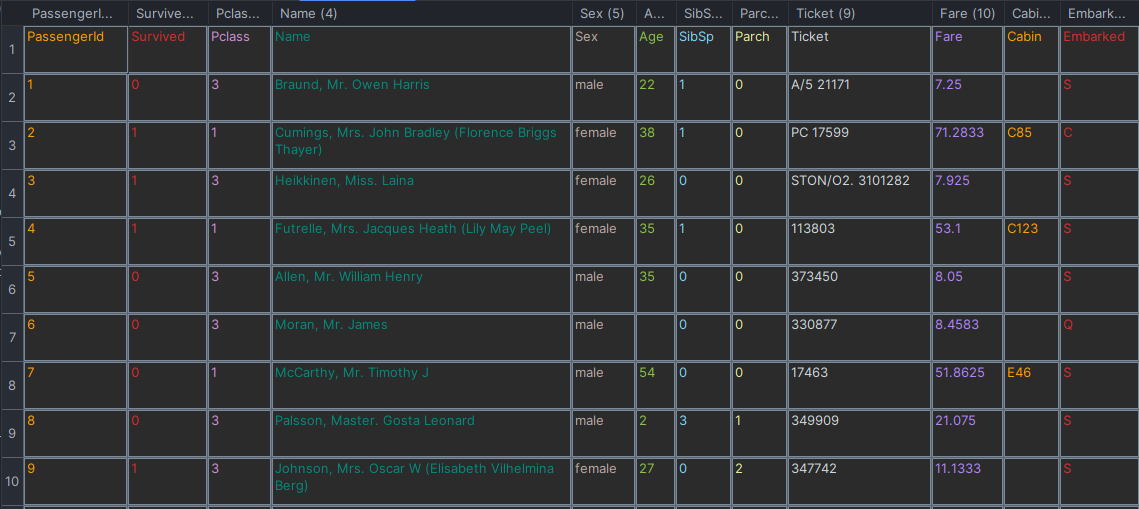
总共有12列,其中Survived字段表示的是该乘客是否获救,其余都是乘客的个人信息,包括:
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
(1)数据类型观察
print("数据类型观察:")
print(train_1.info())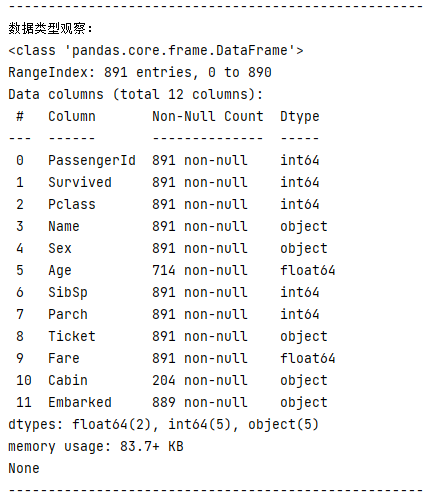
训练数据中总共有891名乘客,但是,我们有些属性的数据不全,比如说:
- Age(年龄)属性只有714名乘客有记录
- Cabin(客舱)属性只有204名乘客是已知的
(2)数据分布情况
print("数据分布情况:")print(train_1.describe()) 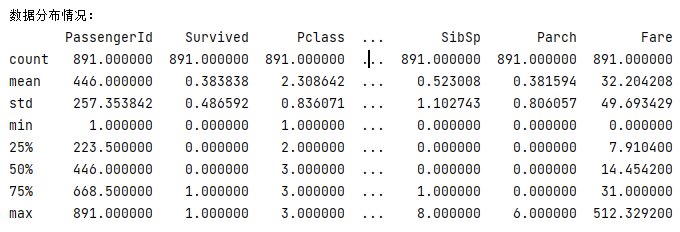
mean字段告诉我们,大概0.383838的人最后获救了,2/3等舱的人数比1等舱要多。
2、初步数据分析
仅仅最上面的对数据了解,依旧无法提供想法和思路。再深入一点来看看数据,看看每个/多个属性和最后的Survived之间有着什么样的关系。通过绘制统计并可视化来分析。
(1)各等级乘客年龄的分析
def age(train_1, path):# 设置中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 显示所有列pd.set_option('display.max_columns', None)# 显示所有行pd.set_option('display.max_rows', None)# 设置value的显示长度为100,默认为50pd.set_option('max_colwidth', 100)# 设置1000列的时候才换行pd.set_option('display.width', 1000)# print(train.describe())fig = plt.figure()fig.set(alpha=0.5)plt.subplot2grid((1, 1), (0, 0)) # Only one subplot for age distribution in each classtrain_1.Age[train_1.Pclass == 1].plot(kind='kde')train_1.Age[train_1.Pclass == 2].plot(kind='kde')train_1.Age[train_1.Pclass == 3].plot(kind='kde')plt.xlabel(u"年龄") # plots an axis lableplt.ylabel(u"密度")plt.title(u"各等级的乘客年龄分布")plt.legend((u'头等舱', u'2等舱', u'3等舱'), loc='best') # sets our legend for our graph.plt.savefig(path + '/age_distribution.jpg')plt.show()
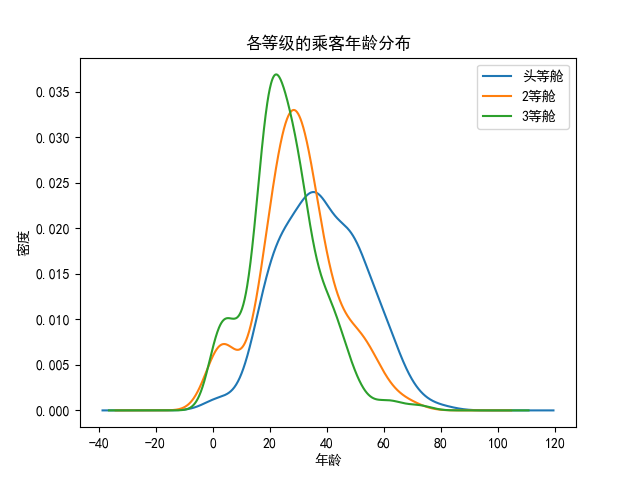
3个不同的舱年龄总体趋势似乎也一致,2/3等舱乘客20岁多点的人最多,1等舱40岁左右的最多,似乎符合财富和年龄的分配;
3、各属性与获救情况的关联
(1)性别和获救情况分析
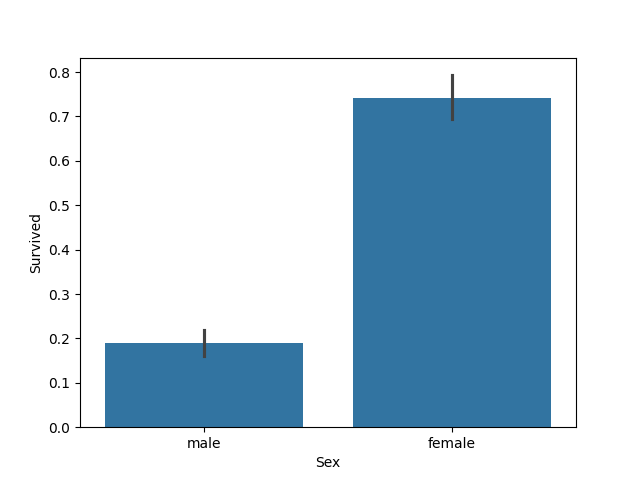
可以看出女生获救的概率比男生获救的概率高得多。性别无疑也要作为重要特征加入最后的模型之中。
(2)仓位等级与获救情况分析
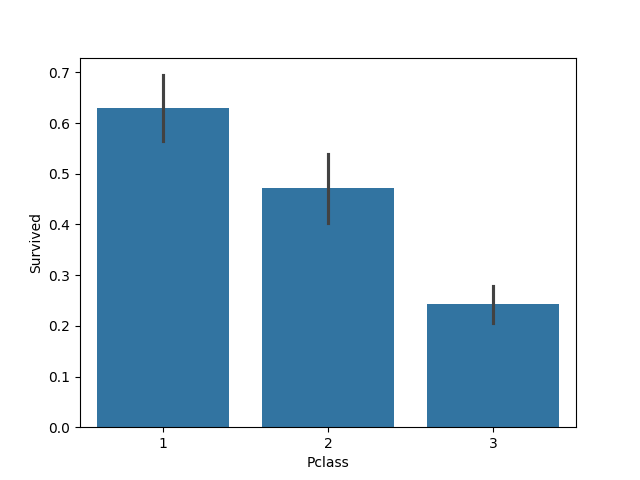
果然,钱和地位对舱位有影响,进而对获救的可能性也有影响,明显等级为1的乘客,获救的概率高很多。这个一定是影响最后获救结果的一个特征。
(3)年龄与获救情况散点图
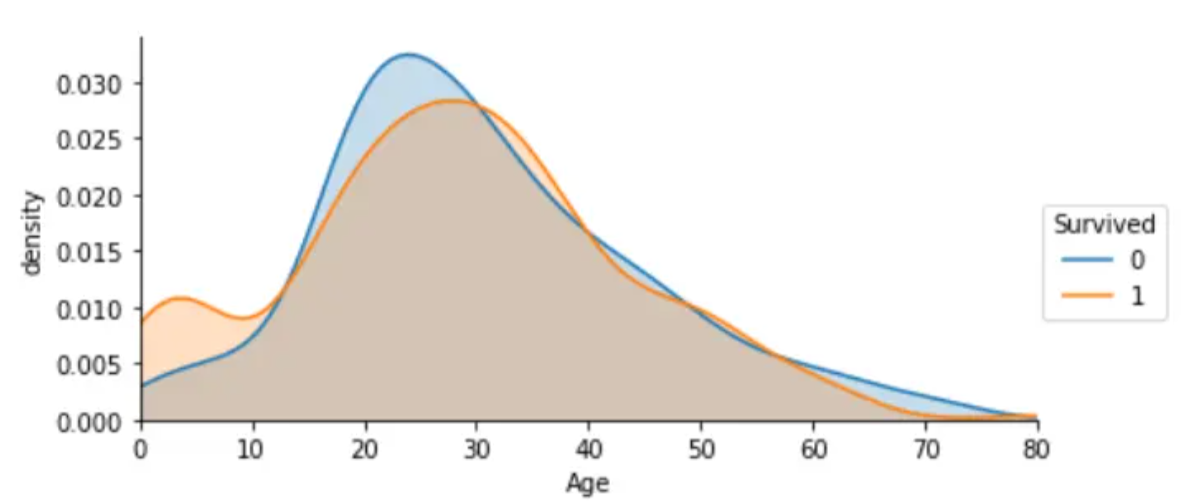
从不同生还情况的密度图可以看出,在年龄15岁的左侧,生还率有明显差别,密度图非交叉区域面积非常大,但在其他年龄段,则差别不是很明显,认为是随机所致,因此可以考虑将此年龄偏小的区域分离出来。
(4)登港口Embarked与生存情况分析
def carbin(full_1, path):full_1.loc[full_1.Cabin.notnull(), 'Cabin'] = 1 # loc 获取指定行索引的行,'Cabin' 只获取指定行的列、对这些满足条件的列赋值full_1.loc[full_1.Cabin.isnull(), 'Cabin'] = 0full_1.Cabin.isnull().sum() # 验证填充效果# 统计有无Cabin 死亡率的情况pd.pivot_table(full_1, index=['Cabin'], values=['Survived']).plot.bar(figsize=(8, 5))plt.title('Survival Rate')plt.savefig(path + '/survival_rate.jpg')plt.show()"""我们还可以绘制“Cabin”的数量来进行查看。 """cabin = pd.crosstab(full_1.Cabin, full_1.Survived)cabin.rename(index={0: 'no cabin', 1: 'have cabin'}, columns={0.0: 'Dead', 1.0: 'Survived'}, inplace=True)cabin.plot.bar(figsize=(8, 5))plt.xticks(rotation=0, size='xx-large')plt.title('Survived Count')plt.xlabel(' ')plt.legend()plt.savefig(path + '/carbin.jpg')plt.show()
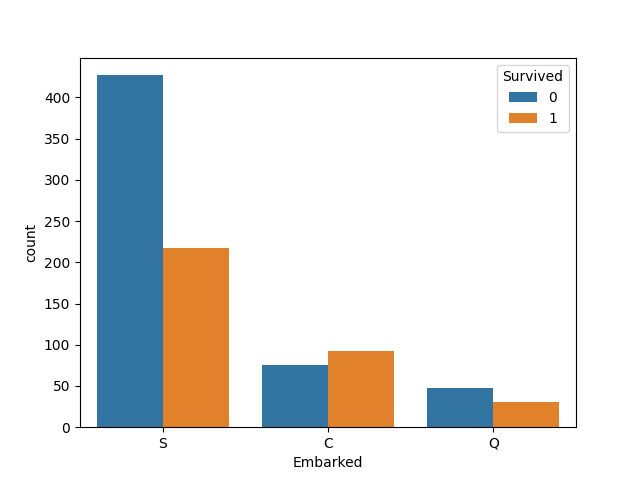
C地的生存率更高,这个也应该保留为模型特征。
(5)直系亲友个数与乘客获救情况
sns.barplot(x="Parch", y="Survived", data=df)plt.savefig(path + '/Parch.jpg')plt.show()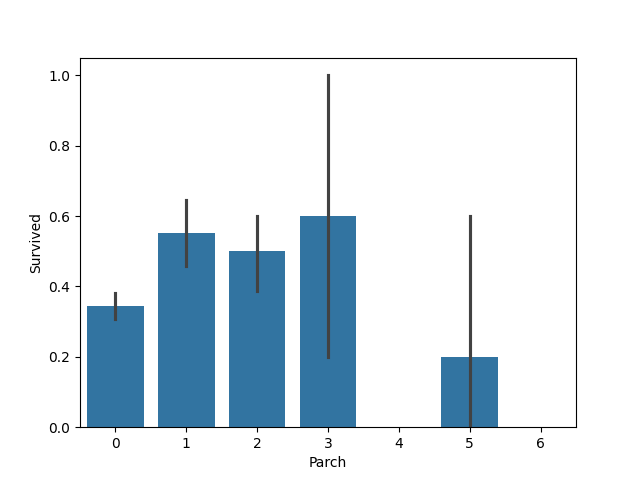
似乎看不出来有什么问题,暂时不考虑这个特征。
(6)旁系亲友个数和乘客获救情况
sns.barplot(x="SibSp", y="Survived", data=df)plt.savefig(path + '/SibSp.jpg')plt.show()
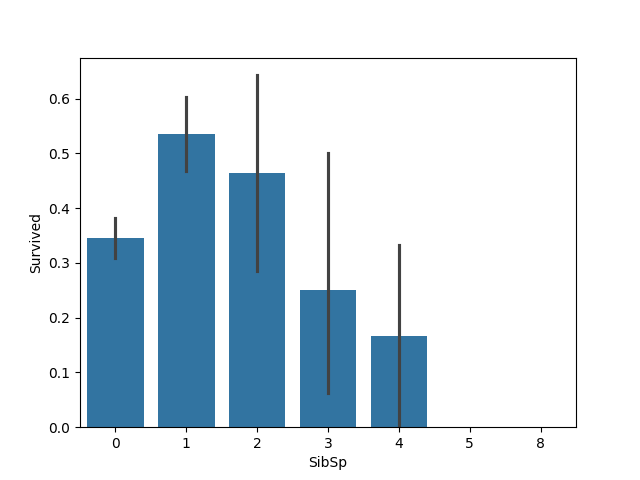
旁系亲友个数在1-2之间的获救概率最高,但似乎没有什么逻辑性。
(7)有无Carbin获救情况
def carbin(full_1, path):full_1.loc[full_1.Cabin.notnull(), 'Cabin'] = 1 # loc 获取指定行索引的行,'Cabin' 只获取指定行的列、对这些满足条件的列赋值full_1.loc[full_1.Cabin.isnull(), 'Cabin'] = 0full_1.Cabin.isnull().sum() # 验证填充效果# 统计有无Cabin 死亡率的情况pd.pivot_table(full_1, index=['Cabin'], values=['Survived']).plot.bar(figsize=(8, 5))plt.title('Survival Rate')plt.savefig(path + '/survival_rate.jpg')plt.show()"""我们还可以绘制“Cabin”的数量来进行查看。 """cabin = pd.crosstab(full_1.Cabin, full_1.Survived)cabin.rename(index={0: 'no cabin', 1: 'have cabin'}, columns={0.0: 'Dead', 1.0: 'Survived'}, inplace=True)cabin.plot.bar(figsize=(8, 5))plt.xticks(rotation=0, size='xx-large')plt.title('Survived Count')plt.xlabel(' ')plt.legend()plt.savefig(path + '/carbin.jpg')plt.show()
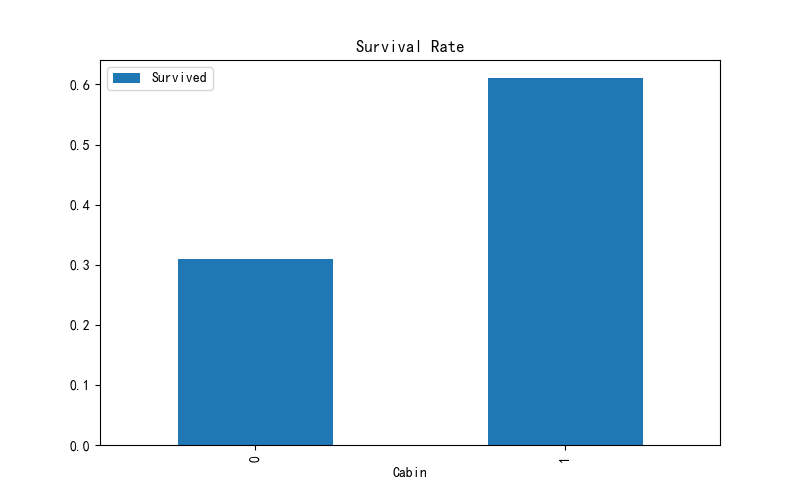
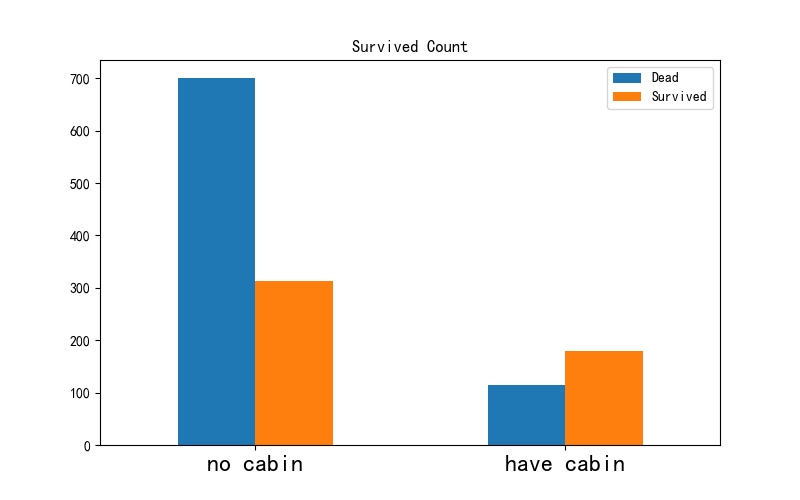
应该算作类目型的,本来缺失值就多,还如此不集中,注定是个棘手货…第一感觉,这玩意儿如果直接按照类目特征处理的话,太散了,估计每个因子化后的特征都拿不到什么权重。加上有那么多缺失值,可以先把Cabin缺失与否作为条件(虽然这部分信息缺失可能并非未登记,maybe只是丢失了而已,所以这样做未必妥当)。
所以我们在图上可以看出来,遇难和获救的人年龄似乎跨度都很广;3个不同的舱年龄总体趋势似乎也一致,2/3等舱乘客20岁多点的人最多,1等舱40岁左右的最多,似乎符合财富和年龄的分配;登船港口人数按照S、C、Q递减,而且S远多于另外俩港口。
这个时候我们可能会有一些想法了:
不同舱位/乘客等级可能和财富/地位有关系,最后获救概率可能会不一样 年龄对获救概率也一定是有影响的,毕竟前面说了,副船长还说“小孩和女士先走” 和登船港口是不是有关系呢?也许登船港口不同,人的出身地位不同?
整段代码
# -*-coding:utf-8-*-
import argparse
import os.pathimport matplotlib.pyplot as plt
import pandas as pd
import seaborn as snsdef set_outputfloader(output_path):if not os.path.exists(output_path):os.makedirs(output_path)"""基本数据分析:param train_1::return: NULL"""def basic_show(train_1):print('----------------------------------------------------')print("数据分布情况:")print(train_1.describe())# 基本类型观察print('----------------------------------------------------')print("数据类型观察:")print(train_1.info())print('----------------------------------------------------')print("数据内容:")print(train_1.head()) # 默认显示5行print('----------------------------------------------------')print("原始数据缺失情况:")print(train_1.isnull().sum()) # 查看数据的缺失情况def basic_show1(df, path):# 性别对于生还的影响sns.barplot(x="Sex", y="Survived", data=df)plt.savefig(path + '/sex.jpg')plt.show()# 船舱等级对生还的影响sns.barplot(x="Pclass", y="Survived", data=df)plt.savefig(path + '/Pclass.jpg')plt.show()# 配偶及兄弟姐妹数适中的乘客幸存率更高sns.barplot(x="SibSp", y="Survived", data=df)plt.savefig(path + '/SibSp.jpg')plt.show()# 父母与子女数适中的乘客幸存率更高sns.barplot(x="Parch", y="Survived", data=df)plt.savefig(path + '/Parch.jpg')plt.show()# Embarked登港港口与生存情况的分析# sns.countplot(x='Embarked', hue='Survived', data=df, fill=True)# plt.savefig(path + '/Embarked.jpg')# plt.show()"""舱位等级和性别对获救影响的详细分析:param train_1: 训练集:return: NULL"""def p_class_sex(train_1, path):# 设置中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 显示所有列pd.set_option('display.max_columns', None)# 显示所有行pd.set_option('display.max_rows', None)# 设置value的显示长度为100,默认为50pd.set_option('max_colwidth', 100)# 设置1000列的时候才换行pd.set_option('display.width', 1000)# print(train.describe())fig = plt.figure()fig.set(alpha=0.5)fig = plt.figure()fig.set(alpha=0.65) # 设置图像透明度,无所谓plt.title(u"根据舱等级和性别的获救情况")ax1 = fig.add_subplot(141)train_1.Survived[train_1.Sex == 'female'][train_1.Pclass != 3].value_counts().plot(kind='bar',label="female highclass",color='#FA2479')ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)ax1.legend([u"女性/高级舱"], loc='best')ax2 = fig.add_subplot(142, sharey=ax1)train_1.Survived[train_1.Sex == 'female'][train_1.Pclass == 3].value_counts().plot(kind='bar',label='female, low class',color='pink')ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)plt.legend([u"女性/低级舱"], loc='best')ax3 = fig.add_subplot(143, sharey=ax1)train_1.Survived[train_1.Sex == 'male'][train_1.Pclass != 3].value_counts().plot(kind='bar',label='male, high class',color='lightblue')ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)plt.legend([u"男性/高级舱"], loc='best')ax4 = fig.add_subplot(144, sharey=ax1)train_1.Survived[train_1.Sex == 'male'][train_1.Pclass == 3].value_counts().plot(kind='bar', label='male low class',color='steelblue')ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)plt.legend([u"男性/低级舱"], loc='best')plt.savefig(path + '/p_class_set.jpg')plt.show()"""age分析
"""def age(train_1, path):# 设置中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 显示所有列pd.set_option('display.max_columns', None)# 显示所有行pd.set_option('display.max_rows', None)# 设置value的显示长度为100,默认为50pd.set_option('max_colwidth', 100)# 设置1000列的时候才换行pd.set_option('display.width', 1000)# print(train.describe())fig = plt.figure()fig.set(alpha=0.5)plt.subplot2grid((1, 1), (0, 0)) # Only one subplot for age distribution in each classtrain_1.Age[train_1.Pclass == 1].plot(kind='kde')train_1.Age[train_1.Pclass == 2].plot(kind='kde')train_1.Age[train_1.Pclass == 3].plot(kind='kde')plt.xlabel(u"年龄") # plots an axis lableplt.ylabel(u"密度")plt.title(u"各等级的乘客年龄分布")plt.legend((u'头等舱', u'2等舱', u'3等舱'), loc='best') # sets our legend for our graph.plt.savefig(path + '/age_distribution.jpg')plt.show()"""有无carbin的生存概率
"""def carbin(full_1, path):full_1.loc[full_1.Cabin.notnull(), 'Cabin'] = 1 # loc 获取指定行索引的行,'Cabin' 只获取指定行的列、对这些满足条件的列赋值full_1.loc[full_1.Cabin.isnull(), 'Cabin'] = 0full_1.Cabin.isnull().sum() # 验证填充效果# 统计有无Cabin 死亡率的情况pd.pivot_table(full_1, index=['Cabin'], values=['Survived']).plot.bar(figsize=(8, 5))plt.title('Survival Rate')plt.savefig(path + '/survival_rate.jpg')plt.show()"""我们还可以绘制“Cabin”的数量来进行查看。 """cabin = pd.crosstab(full_1.Cabin, full_1.Survived)cabin.rename(index={0: 'no cabin', 1: 'have cabin'}, columns={0.0: 'Dead', 1.0: 'Survived'}, inplace=True)cabin.plot.bar(figsize=(8, 5))plt.xticks(rotation=0, size='xx-large')plt.title('Survived Count')plt.xlabel(' ')plt.legend()plt.savefig(path + '/carbin.jpg')plt.show()"""年龄获救散点图
"""def age_scatter_plot(train_1, path):# 设置中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 显示所有列pd.set_option('display.max_columns', None)# 显示所有行pd.set_option('display.max_rows', None)# 设置value的显示长度为100,默认为50pd.set_option('max_colwidth', 100)# 设置1000列的时候才换行pd.set_option('display.width', 1000)fig = plt.figure()fig.set(alpha=0.5)plt.scatter(train_1.Age, train_1.Survived)plt.ylabel(u"获救情况 (1为获救)")plt.xlabel(u"年龄")plt.title(u"年龄与获救情况散点图")plt.savefig(path + '/age_scatter_plot.jpg')plt.show()if __name__ == '__main__':parser = argparse.ArgumentParser()# 参数default值为素材地址与文件保存地址parser.add_argument("--dest_path", default='D:/my_homework/machinelearning/Titannik', help="files save path")parser.add_argument('--train', default='train.csv', help="train data")parser.add_argument('--test', default='test.csv', help="test data")args = parser.parse_args()# 建立文件输出目录output_path = args.dest_path + '/data_output/'set_outputfloader(output_path)# 拿到测试集和训练集train = pd.read_csv(args.train)test = pd.read_csv(args.test)# 将训练数据与测试数据连接起来,以便一起进行数据清洗。# 这里需要注意的是,如果没有后面的ignore_index=True,那么index的值在连接后的这个新数据中是不连续的 继续从 0开始,如果要按照index删除一行数据,可能会发现多删一条。full = pd.concat([train, test], ignore_index=True)# 基本数据分析basic_show(train)# 性别,船舱等级,兄弟姐妹,配偶,登港口basic_show1(train, output_path)# 年龄分析age(train, output_path)# 舱位等级和性别对获救影响的详细分析p_class_sex(train, output_path)# 观测有无carbincarbin(full, output_path)age_scatter_plot(train, output_path)
三、数据预处理
首先明确一点:特征工程非常重要!
先从最突出的数据属性开始吧,Cabin和Age,有丢失数据对下一步工作影响太大。
1、cabin缺失值的处理
Cabin,按照前面的分析,先按Cabin有无数据,将这个属性处理成Yes和No两种类型。
def set_carbin(df):df.loc[df.Cabin.notnull(), 'Cabin'] = 1 # loc 获取指定行索引的行,'Cabin' 只获取指定行的列、对这些满足条件的列赋值df.loc[df.Cabin.isnull(), 'Cabin'] = 0df.Cabin.isnull().sum() # 验证填充效果return df
2、Age缺失值的处理
通常遇到缺值的情况,会有几种常见的处理方式:
①如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
②如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
③如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
④有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
本例中,后两种处理方式应该都是可行的,我们先试试拟合补全吧
我们这里用scikit-learn中的RandomForest来拟合一下缺失的年龄数据(注:RandomForest是一个用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法。
随机森林填充数据的基本步骤:
随机森林(Random Forest)是一种基于集成学习的机器学习算法,它通过构建多个决策树来解决问题。在填充缺失值的场景中,使用随机森林可以有效地利用已有的数据来拟合缺失的值。以下是随机森林填充缺失值的原理:
数据准备: 将数据集分为两部分,一部分包含缺失值的样本,另一部分则没有缺失值。
构建随机森林: 随机森林由多个决策树组成,每个决策树都使用数据的随机子集进行训练。这种随机性有助于减小过拟合的风险。
特征选择: 在每个决策树的节点处,算法随机选择一部分特征来进行划分。这样可以确保每个决策树都是独特的。
训练决策树: 针对每个决策树,使用已有的数据进行训练,其中包括没有缺失值的部分。这样,每个决策树都能够学习数据的模式和关系。
填充缺失值: 对于包含缺失值的样本,通过遍历随机森林的每棵决策树,根据已有的特征信息,
预测缺失值:最终,可以采用这些预测值的平均或投票来得到最终的填充结果。
综合结果: 随机森林中的每棵决策树都提供了一种对缺失值的预测,通过整合这些预测结果,可以得到更为稳健和准确的填充值。
def set_age(df):# 把已有的数值型特征取出来丢进RandomForgestRegressorage_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]known_age = age_df[age_df.Age.notnull()].valuesunknown_age = age_df[age_df.Age.isnull()].valuesy = known_age[:, 0]x = known_age[:, 1:]rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)rfr.fit(x, y)# 用得到的模型来进行未知年龄结果预测predictedAges = rfr.predict(unknown_age[:, 1::])df.loc[(df.Age.isnull()), 'Age'] = predictedAgesreturn df
3、Embarked缺失值的处理
就缺失了两个,这里直接使用了众数进行填充。
print(df.Embarked.mode())df['Embarked'].fillna('S', inplace=True)
4、特征因子化
逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,‘no’],而将其平展开为’Cabin_yes’,'Cabin_no’两个属性
原本Cabin取值为yes的,在此处的"Cabin_yes"下取值为1,在"Cabin_no"下取值为0
原本Cabin取值为no的,在此处的"Cabin_yes"下取值为0,在"Cabin_no"下取值为1
我们使用pandas的"get_dummies"来完成这个工作,并拼接在原来的"train"之上。
def age_fare_scaler(df):# 特征因子化dummies_Cabin = pd.get_dummies(df['Cabin'], prefix='Cabin')dummies_Embarked = pd.get_dummies(df['Embarked'], prefix='Embarked')dummies_Sex = pd.get_dummies(df['Sex'], prefix='Sex')dummies_Pclass = pd.get_dummies(df['Pclass'], prefix='Pclass')df = pd.concat([df, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)# print(df)"""Age和Fare两个属性,乘客的数值幅度变化,太大,逻辑回归与梯度下降各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛!我们先用scikit-learn里面的preprocessing模块对这俩做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。"""scaler = preprocessing.StandardScaler()df['Age_scaled'] = scaler.fit_transform(df[['Age']])df['Fare_scaled'] = scaler.fit_transform(df[['Fare']])return df5、姓氏
姓氏也可以作为一个特征,姓氏显示了一个人的身份地位、婚姻状态等。将每个分类变量映射到一个由 0 和 1 组成的向量,其中每个元素表示变量是否具有对应的类别。这里可以用独热编码将姓氏转化为可以被理解的特征。(慎用,处理后的模型准确率降低了,可能是我的方式不对,大家可以尝试)
def set_name(df):titleDf = pd.DataFrame()# map函数:对Series每个数据应用自定义的函数计算titleDf['Title'] = df['Name'].map(getTitle)title_mapDict = {"Capt": "Officer","Col": "Officer","Major": "Officer","Jonkheer": "Royalty","Don": "Royalty","Sir": "Royalty","Dr": "Officer","Rev": "Officer","the Countess": "Royalty","Dona": "Royalty","Mme": "Mrs","Mlle": "Miss","Ms": "Mrs","Mr": "Mr","Mrs": "Mrs","Miss": "Miss","Master": "Master","Lady": "Royalty"}# map函数:对Series每个数据应用自定义的函数计算titleDf['Title'] = titleDf['Title'].map(title_mapDict)# 使用get_dummies进行one-hot编码titleDf = pd.get_dummies(titleDf['Title'])# 添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集fulldf = pd.concat([df, titleDf], axis=1)return df
整段代码
# -*-coding:utf-8-*-
import argparseimport pandas as pd
from sklearn import preprocessing"""•PassengerID(ID)•Survived(存活与否)•Pclass(客舱等级,较为重要)•Name(姓名,可提取出更多信息)•Sex(性别,较为重要)•Age(年龄,较为重要)•Parch(直系亲友)•SibSp(旁系)•Ticket(票编号)•Fare(票价)•Cabin(客舱编号)•Embarked(上船的港口编号)
"""
# 随机森林算法
from sklearn.ensemble import RandomForestRegressordef set_age(df):# 把已有的数值型特征取出来丢进RandomForgestRegressorage_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]known_age = age_df[age_df.Age.notnull()].valuesunknown_age = age_df[age_df.Age.isnull()].valuesy = known_age[:, 0]x = known_age[:, 1:]rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)rfr.fit(x, y)# 用得到的模型来进行未知年龄结果预测predictedAges = rfr.predict(unknown_age[:, 1::])df.loc[(df.Age.isnull()), 'Age'] = predictedAgesreturn dfdef set_carbin(df):df.loc[df.Cabin.notnull(), 'Cabin'] = 1 # loc 获取指定行索引的行,'Cabin' 只获取指定行的列、对这些满足条件的列赋值df.loc[df.Cabin.isnull(), 'Cabin'] = 0df.Cabin.isnull().sum() # 验证填充效果return dfdef set_fare(df):"""填充Fare的缺失值fare主要和Pclass有关该人的Pclass等级为几,选择客舱等级为几的票价中位数填充"""df.loc[df.Pclass == 1, 'Fare'] = df[df.Pclass == 1]['Fare'].fillna(df[df.Pclass == 1]['Fare'].median())df.loc[df.Pclass == 2, 'Fare'] = df[df.Pclass == 2]['Fare'].fillna(df[df.Pclass == 2]['Fare'].median())df.loc[df.Pclass == 3, 'Fare'] = df[df.Pclass == 3]['Fare'].fillna(df[df.Pclass == 3]['Fare'].median())print(df[df.Fare.isnull()])return dfdef age_fare_scaler(df):# 特征因子化dummies_Cabin = pd.get_dummies(df['Cabin'], prefix='Cabin')dummies_Embarked = pd.get_dummies(df['Embarked'], prefix='Embarked')dummies_Sex = pd.get_dummies(df['Sex'], prefix='Sex')dummies_Pclass = pd.get_dummies(df['Pclass'], prefix='Pclass')df = pd.concat([df, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)# print(df)"""Age和Fare两个属性,乘客的数值幅度变化,太大,逻辑回归与梯度下降各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛!我们先用scikit-learn里面的preprocessing模块对这俩做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。"""scaler = preprocessing.StandardScaler()df['Age_scaled'] = scaler.fit_transform(df[['Age']])df['Fare_scaled'] = scaler.fit_transform(df[['Fare']])return dfdef set_data(df):"""填充Embarked的值选择众数"""print(df.Embarked.mode())df['Embarked'].fillna('S', inplace=True)"""填充Fare的缺失值"""df = set_fare(df)"""填充carbin的值,缺失了1014个值,有无carbin值作为参考。"""df = set_carbin(df)""" Age缺失值的处理"""df = set_age(df)# df = set_name(df)df = age_fare_scaler(df)return dfdef getTitle(name):str1 = name.split(',')[1] # Mr. Owen Harrisstr2 = str1.split('.')[0] # Mr# strip() 方法用于移除字符串头尾指定的字符(默认为空格)str3 = str2.strip()return str3def set_name(df):titleDf = pd.DataFrame()# map函数:对Series每个数据应用自定义的函数计算titleDf['Title'] = df['Name'].map(getTitle)title_mapDict = {"Capt": "Officer","Col": "Officer","Major": "Officer","Jonkheer": "Royalty","Don": "Royalty","Sir": "Royalty","Dr": "Officer","Rev": "Officer","the Countess": "Royalty","Dona": "Royalty","Mme": "Mrs","Mlle": "Miss","Ms": "Mrs","Mr": "Mr","Mrs": "Mrs","Miss": "Miss","Master": "Master","Lady": "Royalty"}# map函数:对Series每个数据应用自定义的函数计算titleDf['Title'] = titleDf['Title'].map(title_mapDict)# 使用get_dummies进行one-hot编码titleDf = pd.get_dummies(titleDf['Title'])# 添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集fulldf = pd.concat([df, titleDf], axis=1)return dfdef pre_data(path):train_data = pd.read_csv('Data/train.csv')test_data = pd.read_csv('Data/test.csv')print("\n原始数据缺失情况:")print(train_data.isnull().sum()) # 查看数据的缺失情况# 数据处理train_datapath = path + '/Data/new_train.csv'train_data = set_data(train_data)train_data.to_csv(train_datapath, index=False)# 测试集处理test_datapath = path + '/Data/new_test.csv'test_data = set_data(test_data)test_data.to_csv(test_datapath, index=False)pd.set_option('display.max_columns', None)print(train_data)print("\n数据处理后情况:")print(train_data.isnull().sum()) # 查看数据的缺失情况return train_data, test_dataif __name__ == '__main__':parser = argparse.ArgumentParser()# 参数default值为素材地址与文件保存地址parser.add_argument("--dest_path", default='D:/my_homework/machinelearning/Titannik', help="files save path")parser.add_argument('--train', default='Data/train.csv', help="train data")parser.add_argument('--test', default='Data/test.csv', help="test data")parser.add_argument("--testoutput", default="D:/my_homework/machinelearning/Titannik/Data/new_test.csv",help="new test data output path")parser.add_argument("--trainoutput", default="D:/my_homework/machinelearning/Titannik/Data/new_train.csv",help="new train data output path")args = parser.parse_args()train = pd.read_csv(args.train)test = pd.read_csv(args.test)print("\n原始数据缺失情况:")print(train.isnull().sum()) # 查看数据的缺失情况# 数据处理train_data_path = args.dest_path + '/Data/new_train.csv'train = set_data(train)train.to_csv(train_data_path, index=False)# 测试集处理test_data_path = args.dest_path + '/Data/new_test.csv'test = set_data(test)test.to_csv(test_data_path, index=False)pd.set_option('display.max_columns', None)print(train)print("\n原始数据处理后情况:")print(train.isnull().sum()) # 查看数据的缺失情况
四、模型搭建
1、逻辑回归建模
def logist(x, Y, test):# fit到RandomForestRegressor之中clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')clf.fit(x, Y.astype('int'))print(clf)test_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("logist.csv", index=False)print('预测完成')print("---------------------------------------------")print("模型系数:")print(pd.DataFrame({"columns": list(train_df.columns)[1:], "coef": list(clf.coef_.T)}))return result
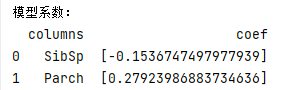

这里很明显出现了欠拟合,那么多的特征,最后的模型只用到了两个特征。并且正确率特别低,所以需要再优化。
对数据进行分析:
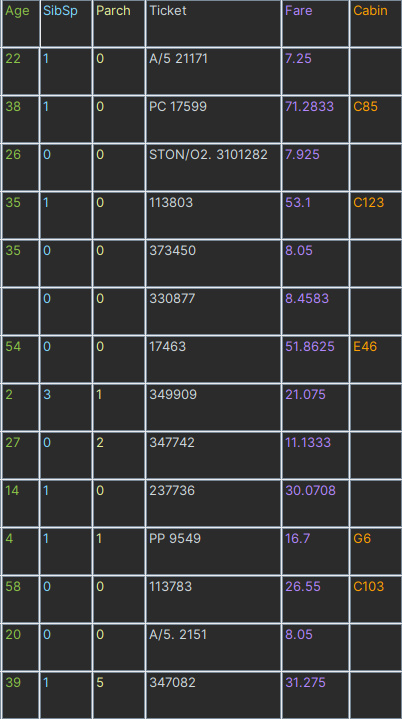
仔细看看Age和Fare两个属性,乘客的数值幅度变化,也忒大了吧!!如果大家了解逻辑回归与梯度下降的话,会知道,各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛!所以先用scikit-learn里面的preprocessing模块对这俩货做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。 (我给的代码已经在函数age_fare_scaler(df)
中处理过了,所以大家不会遇到这样的问题。
"""Age和Fare两个属性,乘客的数值幅度变化,太大,逻辑回归与梯度下降各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛!我们先用scikit-learn里面的preprocessing模块对这俩做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。"""scaler = preprocessing.StandardScaler()df['Age_scaled'] = scaler.fit_transform(df[['Age']])df['Fare_scaled'] = scaler.fit_transform(df[['Fare']])
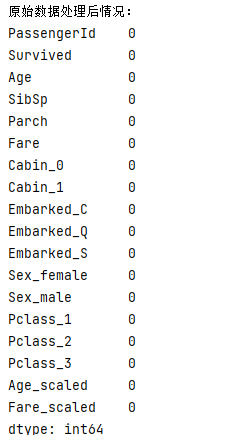
再进行建模查看:
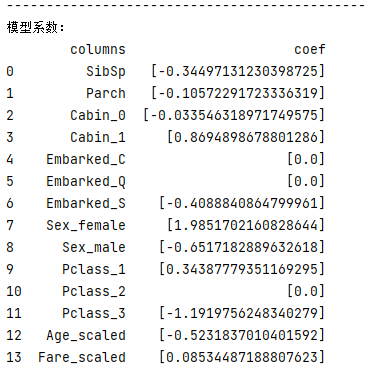

果然提高了不少,应该还有提升的空间。
再次分析:
这些系数为正的特征,和最后结果是一个正相关,反之为负相关。
先看那些权重绝对值非常大的feature,在我们的模型上:
Sex属性:如果是female会极大提高最后获救的概率,而male会很大程度拉低这个概率。
Pclass属性:1等舱乘客最后获救的概率会上升,而乘客等级为3会极大地拉低这个概率。
Cabin属性:有Cabin值会很大程度拉升最后获救概率(这里似乎能看到了一点端倪,事实上从最上面的有无Cabin记录的Survived分布图上看出,即使有Cabin记录的乘客也有一部分遇难了,估计这个属性上我们挖掘还不够)
Age:Age是一个负相关,意味着在我们的模型里,年龄越小,越有获救的优先权(还得回原数据看看这个是否合理)
登港口Embaked:有一个登船港口S会很大程度拉低获救的概率,另外俩港口压根就没啥作用(这个实际上非常奇怪,因为我们从之前的统计图上并没有看到S港口的获救率非常低,所以也许可以考虑把登船港口这个feature去掉试试)。
Fare属性:船票Fare有小幅度的正相关(并不意味着这个feature作用不大,有可能是我们细化的程度还不够,举个例子,说不定我们得对它离散化,再分至各个乘客等级上?)
交叉验证优化
我们通常情况下,这么做cross validation:把train.csv分成两部分,一部分用于训练我们需要的模型,另外一部分数据上看我们预测算法的效果。
我们用scikit-learn的cross_validation来帮我们完成小数据集上的这个工作。
def k_fold(X, y):'''c:正则化强度的倒数。较小的值表示更强的正则化。'''clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')train_sizes, train_scores, test_scores = learning_curve(clf, X, y.astype('int'), cv=5, scoring='accuracy',n_jobs=-1)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.figure(figsize=(10, 6))plt.title("Learning Curve")plt.xlabel("Training examples")plt.ylabel("Score")plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1,color="g")plt.legend(loc="best")plt.show()# Print cross-validation scoresprint("交叉验证得分:", cross_val_score(clf, X, y.astype('int'), cv=5))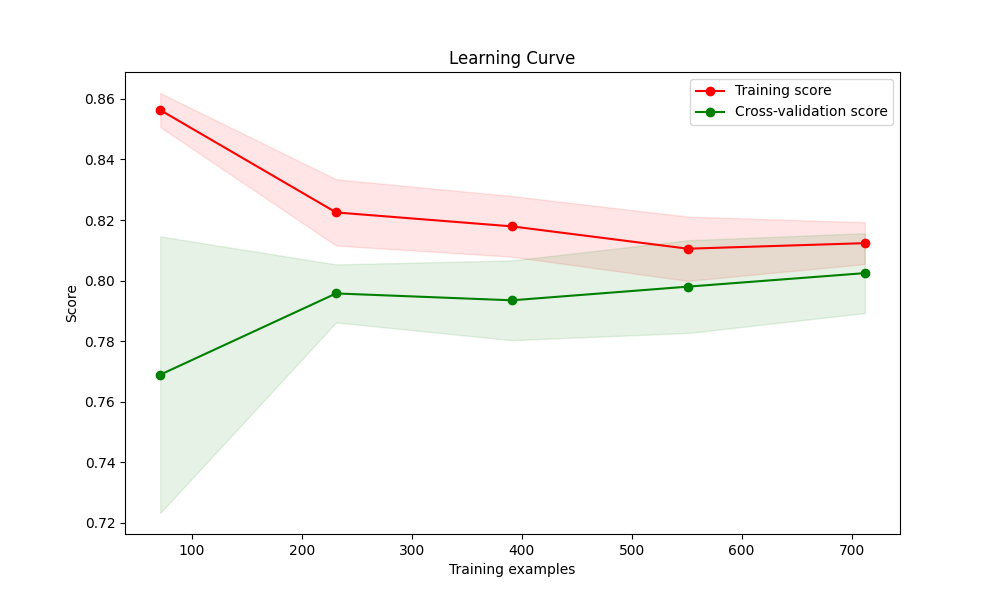

似乎比Kaggle上的测试要高,曲线拟合也属于正常变化。
为了能够能清楚我们的模型有哪些不足,这里直接将错误的例子输出。
def k_foldfalsecase(x, y, df, origin_train_path):# 分割数据,按照 训练数据:cv数据 = 7:3的比例split_train, split_cv = train_test_split(df, test_size=0.3, random_state=0)train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# 生成模型clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')clf.fit(x, y.astype('int'))# 对cross validation数据进行预测cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(cv_df.values[:, 1:])origin_data_train = pd.read_csv(origin_train_path)bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.values[:, 0]]['PassengerId'].values)]print("预测错误的例子:")bad_cases.to_csv("false_case.csv")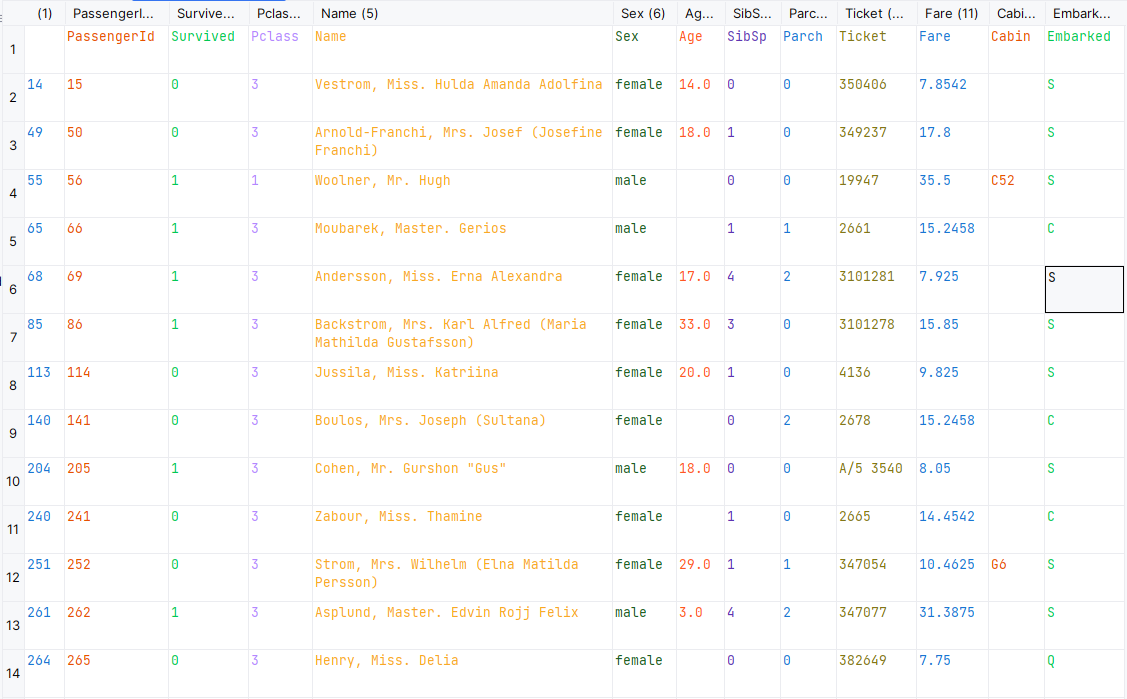
可以看到,大部分错误的数据很大程度上属于个例如265乘客女性,无Carbin,这俩值在模型中起到的作用很大,正常来说她生还的概率非常大,但是却没有生还,说明我们对数据的挖掘还不够,特别是cabin这个属性,另外还有姓氏?根据姓氏可以看出一个人的身份,贵族?已婚?成年?等等
并且预测错误的大部分是三等舱的人,对于一等舱二等舱预测概率非常高,但是对于三等舱的预测效果很差,这么来说,我们是不是可以单独把三等舱的人拿出来进行训练?然后将模型进行融合?这样概率会不会提高?我认为这样做绝对可以。
先不考虑这些,单在模型上我认为还有优化的空间,既然考虑到了模型融合,我们是不是可以用多个模型如KNN、SVM、深度学习?来和逻辑回归进行拟合,然后在预测的时候进行投票?这种思路其实也可以。
还有一种方法,那我们干脆就不要用全部的训练集,每次取训练集的一个subset,做训练,这样,我们虽然用的是同一个机器学习算法,但是得到的模型却是不一样的;同时,因为我们没有任何一份子数据集是全的,因此即使出现过拟合,也是在子训练集上出现过拟合,而不是全体数据上,这样做一个融合,可能对最后的结果有一定的帮助。对,这就是常用的Bagging。
Bagging优化
def bagging(X, y, test_end, standard_path):# fit到RandomForestRegressor之中clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')# n_estimators 要集成的基估计器个数,max_samples决定抽取去训练基估计器的样本数量,max_features决定去训练基估计器的特征数量# bootstrap : boolean, optional (default=True) 决定样本子集的抽样方式(有放回和不放回)# bootstrap_features : boolean, optional (default=False)决定特征子集的抽样方式(有放回和不放回)bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True,bootstrap_features=False, n_jobs=-1)bagging_clf.fit(X, y.astype("int"))# print(clf)predictions = bagging_clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})path = "logistic_regression_bagging_predictions_end.csv"result.to_csv(path, index=False)accuracy(path, standard_path)
在kaggle上测试果然有提升,排名排到了2000多名。
所有代码
import argparseimport numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn import linear_model
from sklearn.ensemble import BaggingRegressor
from sklearn.model_selection import cross_val_score, train_test_split, learning_curvefrom dataset_pre import pre_data
import sklearn.metrics as metricsdef accuracy(my_data, standard_file_path):# 1. 加载标准答案的 CSV 文件standard_data = pd.read_csv(standard_file_path)my_data = pd.read_csv(my_data)# 3. 合并数据merged_data = pd.merge(standard_data, my_data, on='PassengerId', how='inner')# 4. 计算准确率accuracy = (merged_data['Survived_x'] == merged_data['Survived_y']).mean()print(f'Accuracy: {accuracy * 100:.2f}%')def logist(x, Y, test):# fit到RandomForestRegressor之中clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')clf.fit(x, Y.astype('int'))print(clf)test_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("logist.csv", index=False)print('预测完成')print("---------------------------------------------")print("模型系数:")print(pd.DataFrame({"columns": list(train_df.columns)[1:], "coef": list(clf.coef_.T)}))return resultdef k_fold(X, y):'''c:正则化强度的倒数。较小的值表示更强的正则化。'''clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')train_sizes, train_scores, test_scores = learning_curve(clf, X, y.astype('int'), cv=5, scoring='accuracy',n_jobs=-1)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.figure(figsize=(10, 6))plt.title("Learning Curve")plt.xlabel("Training examples")plt.ylabel("Score")plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1,color="g")plt.legend(loc="best")plt.show()# Print cross-validation scoresprint("交叉验证得分:", cross_val_score(clf, X, y.astype('int'), cv=5))def k_foldfalsecase(x, y, df, origin_train_path):# 分割数据,按照 训练数据:cv数据 = 7:3的比例split_train, split_cv = train_test_split(df, test_size=0.3, random_state=0)train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# 生成模型clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')clf.fit(x, y.astype('int'))# 对cross validation数据进行预测cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(cv_df.values[:, 1:])origin_data_train = pd.read_csv(origin_train_path)bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.values[:, 0]]['PassengerId'].values)]print("预测错误的例子:")bad_cases.to_csv("false_case.csv")# print(bad_cases)def bagging(X, y, test_end, standard_path):# fit到RandomForestRegressor之中clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear')# n_estimators 要集成的基估计器个数,max_samples决定抽取去训练基估计器的样本数量,max_features决定去训练基估计器的特征数量# bootstrap : boolean, optional (default=True) 决定样本子集的抽样方式(有放回和不放回)# bootstrap_features : boolean, optional (default=False)决定特征子集的抽样方式(有放回和不放回)bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True,bootstrap_features=False, n_jobs=-1)bagging_clf.fit(X, y.astype("int"))# print(clf)predictions = bagging_clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})path = "logistic_regression_bagging_predictions_end.csv"result.to_csv(path, index=False)accuracy(path, standard_path)if __name__ == '__main__':parser = argparse.ArgumentParser()# 参数default值为素材地址与文件保存地址parser.add_argument("--dest_path", default='D:/my_homework/machinelearning/Titannik', help="files save path")parser.add_argument('--train', default='Data/train.csv', help="train data")parser.add_argument('--test', default='Data/test.csv', help="test data")parser.add_argument('--standard_path', default='gender_submission.csv', help="standard path")args = parser.parse_args()train_df = train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')train_np = train_df.valuestest_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# y即Survival结果y = train_np[:, 0]# X即特征属性值X = train_np[:, 1:]# 先选择4个csv文件的路径# 给下面的每个函数调用都设置一个按钮# 要求按钮要自适应大小,可以显示输出结果# 逻辑回归预测# result = logist(X, y, test)# # K折交叉# print('K折交叉验证测试模型:')k_fold(X, y)# # 预测错误的# k_foldfalsecase(X, y, train, args.train)# # bagging# bagging(X, y, test_end, args.standard_path)2、SVM建模
思路和逻辑回归一样这里直接附上代码和结果。
import argparseimport numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import cross_val_score, train_test_split, learning_curve
from sklearn.svm import SVCfrom dataset_pre import pre_datadef svm_model(x, Y, test):# fit到SVC之中clf = SVC(C=1.0, kernel='linear', tol=1e-6)clf.fit(x, Y.astype('int'))print(clf)test_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("age_fared_svm.csv", index=False)print('预测完成')print("---------------------------------------------")print("支持向量机模型信息:")print("超参数:", clf.get_params())return resultdef k_fold_svm(X, y):clf = SVC(C=1.0, kernel='linear', tol=1e-6)# Plot learning curvetrain_sizes, train_scores, test_scores = learning_curve(clf, X, y.astype('int'), cv=5, scoring='accuracy',n_jobs=-1)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.figure(figsize=(10, 6))plt.title("Learning Curve")plt.xlabel("Training examples")plt.ylabel("Score")plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1,color="g")plt.legend(loc="best")plt.show()# Print cross-validation scoresprint("交叉验证得分:", cross_val_score(clf, X, y.astype('int'), cv=5))def k_fold_false_case_svm(df, origin_train_path):# 分割数据,按照 训练数据:cv数据 = 7:3的比例split_train, split_cv = train_test_split(df, test_size=0.3, random_state=0)train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# 生成模型clf = SVC(C=1.0, kernel='linear', tol=1e-6)clf.fit(train_df.values[:, 1:], train_df.values[:, 0].astype('int'))# 对cross validation数据进行预测cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(cv_df.values[:, 1:])origin_data_train = pd.read_csv(origin_train_path)bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.values[:, 0]]['PassengerId'].values)]print("预测错误的例子:")bad_cases.to_csv("svm_false_case.csv", index=False)def svm_bagging(X, y, test_end):# 设置中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 将数据拆分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建一个SVM分类器clf = SVC(C=1.0, kernel='rbf', tol=1e-6)# 创建一个BaggingClassifier,以SVM为基础估计器bagging_clf = BaggingClassifier(base_estimator=clf, n_estimators=20, max_samples=0.8, max_features=1.0,bootstrap=True,bootstrap_features=False, n_jobs=-1)bagging_clf.fit(X_train, y_train)# 打印在测试集上的准确性accuracy = bagging_clf.score(X_test, y_test)print("测试集准确性:", accuracy)# 在test_end数据上进行预测predictions = bagging_clf.predict(test_end)# 将预测保存到CSV文件result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("svm_bagging_predictions_end(rbf).csv", index=False)if __name__ == '__main__':parser = argparse.ArgumentParser()# 参数default值为素材地址与文件保存地址parser.add_argument("--dest_path", default='D:/my_homework/machinelearning/Titannik', help="files save path")parser.add_argument('--train', default='Data/train.csv', help="train data")parser.add_argument('--test', default='Data/test.csv', help="test data")parser.add_argument('--standard_path', default='gender_submission.csv', help="standard path")args = parser.parse_args()# 特征工程train, test = pre_data(args.dest_path)# 用正则取出我们要的属性值# •PassengerID(ID)# •Survived(存活与否)# •Pclass(客舱等级,较为重要)# •Name(姓名,可提取出更多信息)# •Sex(性别,较为重要)# •Age(年龄,较为重要)# •Parch(直系亲友)# •SibSp(旁系)# •Ticket(票编号)# •Fare(票价)# •Cabin(客舱编号)# •Embarked(上船的港口编号)train_df = train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')train_np = train_df.valuestest_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# y即Survival结果y = train_np[:, 0]# X即特征属性值X = train_np[:, 1:]# svm预测result = svm_model(X, y, test)# print('K折交叉验证测试模型:')# k折交叉验证学习曲线k_fold_svm(X, y)# k折交叉验证预测错误的样本k_fold_false_case_svm(train, args.train)# 模型融合svm_bagging(X, y.astype('int'), test_end)


对SVM的三种拟合方式进行了尝试,效果依旧不如逻辑回归。
同样,错误的样本大多出现在了船舱等级为三的乘客。
3、KNN建模
import argparseimport numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import cross_val_score, train_test_split, learning_curvefrom dataset_pre import pre_datadef accuracy(my_data, standard_file_path):# 1. 加载标准答案的 CSV 文件standard_data = pd.read_csv(standard_file_path)# 3. 合并数据merged_data = pd.merge(standard_data, my_data, on='PassengerId', how='inner')# 4. 计算准确率accuracy = (merged_data['Survived_x'] == merged_data['Survived_y']).mean()print(f'Accuracy: {accuracy * 100:.2f}%')from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import BaggingClassifierdef knn(x, Y, test):# fit到KNeighborsClassifier之中clf = KNeighborsClassifier(n_neighbors=5)clf.fit(x, Y.astype('int'))print(clf)test_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("age_fared_knn.csv", index=False)print('预测完成')return resultdef k_fold(X, y):clf = KNeighborsClassifier(n_neighbors=5)# Plot learning curvetrain_sizes, train_scores, test_scores = learning_curve(clf, X, y.astype('int'), cv=5, scoring='accuracy',n_jobs=-1)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.figure(figsize=(10, 6))plt.title("Learning Curve")plt.xlabel("Training examples")plt.ylabel("Score")plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1,color="g")plt.legend(loc="best")plt.show()# Print cross-validation scoresprint("交叉验证得分:", cross_val_score(clf, X, y.astype('int'), cv=5))def k_fold_false_case(df, origin_train_path):# 分割数据,按照 训练数据:cv数据 = 7:3的比例split_train, split_cv = train_test_split(df, test_size=0.3, random_state=0)train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# 生成模型clf = KNeighborsClassifier(n_neighbors=5)clf.fit(train_df.values[:, 1:], train_df.values[:, 0].astype('int'))# 对cross validation数据进行预测cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')predictions = clf.predict(cv_df.values[:, 1:])origin_data_train = pd.read_csv(origin_train_path)bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.values[:, 0]]['PassengerId'].values)]print("预测错误的例子:")bad_cases.to_csv("false_case_knn.csv", index=False)# print(bad_cases)def bagging_knn(X, y, test_end):# fit到KNeighborsClassifier之中clf = KNeighborsClassifier(n_neighbors=5)# 创建一个BaggingClassifier,以KNN为基础估计器bagging_clf = BaggingClassifier(base_estimator=clf, n_estimators=20, max_samples=0.8, max_features=1.0,bootstrap=True,bootstrap_features=False, n_jobs=-1)bagging_clf.fit(X, y)predictions = bagging_clf.predict(test_end)result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("knn_bagging_predictions_end.csv", index=False)def knn_bagging(X, y, test_end):# 设置中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 将数据拆分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y.astype('int'), test_size=0.2, random_state=42)# 创建一个KNN分类器clf = KNeighborsClassifier(n_neighbors=5)# 创建一个BaggingClassifier,以KNN为基础估计器bagging_clf = BaggingClassifier(base_estimator=clf, n_estimators=20, max_samples=0.8, max_features=1.0,bootstrap=True,bootstrap_features=False, n_jobs=-1)bagging_clf.fit(X_train, y_train)# 打印在测试集上的准确性accuracy = bagging_clf.score(X_test, y_test)print("测试集准确性:", accuracy)# 在test_end数据上进行预测predictions = bagging_clf.predict(test_end)# 将预测保存到CSV文件result = pd.DataFrame({'PassengerId': test['PassengerId'].values, 'Survived': predictions.astype(np.int32)})result.to_csv("knn_bagging_predictions_end.csv", index=False)if __name__ == '__main__':parser = argparse.ArgumentParser()# 参数default值为素材地址与文件保存地址parser.add_argument("--dest_path", default='D:/my_homework/machinelearning/Titannik', help="files save path")parser.add_argument('--train', default='Data/train.csv', help="train data")parser.add_argument('--test', default='Data/test.csv', help="test data")parser.add_argument('--standard_path', default='gender_submission.csv', help="standard path")args = parser.parse_args()# 特征工程train, test = pre_data(args.dest_path)train_df = train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')train_np = train_df.valuestest_end = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')# y即Survival结果y = train_np[:, 0]# X即特征属性值X = train_np[:, 1:]# KNN预测result = knn(X, y, test)print('K折交叉验证测试模型:')k_fold(X, y)print("k折交叉验证预测错误的")# k折交叉验证预测错误的样本k_fold_false_case(train, args.train)# 模型融合knn_bagging(X, y, test_end)
 4、深度学习模型
4、深度学习模型
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from dataset_pre import pre_data# Define the neural network model"""包含一个输入层,一个包含ReLU激活函数的隐藏层,
"""class TitanicModel(nn.Module):def __init__(self, input_size):super(TitanicModel, self).__init__()self.fc1 = nn.Linear(input_size, 64)self.relu = nn.ReLU()self.fc2 = nn.Linear(64, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)x = self.sigmoid(x)return x"""
这训练神经网络模型的函数。
一个简单的梯度下降优化算法(Adam)和二元交叉熵损失函数来优化模型的权重。
"""def train_model(model, criterion, optimizer, train_loader, epochs=10):for epoch in range(epochs):for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs.float())loss = criterion(outputs.squeeze(), labels.float())loss.backward()optimizer.step()def predict(model, test_loader):predictions = []with torch.no_grad():for inputs in test_loader:outputs = model(inputs.float())predictions.extend(outputs.cpu().numpy())return np.array(predictions)def accuracy(my_data, standard_file_path):standard_data = pd.read_csv(standard_file_path)my_data = pd.read_csv(my_data)merged_data = pd.merge(standard_data, my_data, on='PassengerId', how='inner')accuracy = (merged_data['Survived_x'] == merged_data['Survived_y']).mean()print(f'Accuracy: {accuracy * 100:.2f}%')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument("--dest_path", default='D:/my_homework/machinelearning/Titannik', help="files save path")parser.add_argument('--train', default='Data/train.csv', help="train data")parser.add_argument('--test', default='Data/test.csv', help="test data")parser.add_argument('--standard_path', default='gender_submission.csv', help="standard path")args = parser.parse_args()train, test = pre_data(args.dest_path)train_df = train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')train_np = train_df.valuesy = train_np[:, 0]X = train_np[:, 1:]y = y.astype(np.float32)X = X.astype(np.float32)# Split the data into training and validation setsX_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)# Create DataLoader for training and validationtrain_dataset = TensorDataset(torch.FloatTensor(X_train), torch.FloatTensor(y_train))train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)val_dataset = TensorDataset(torch.FloatTensor(X_val), torch.FloatTensor(y_val))val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)# Initialize the model, criterion, and optimizermodel = TitanicModel(input_size=X.shape[1])criterion = nn.BCELoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# Train the modeltrain_model(model, criterion, optimizer, train_loader, epochs=10)# Evaluate the model on the validation setwith torch.no_grad():model.eval()val_inputs, val_labels = next(iter(val_loader))val_outputs = model(val_inputs.float())val_predictions = (val_outputs.squeeze().numpy() > 0.5).astype(int)accuracy = np.mean(val_predictions == val_labels.numpy())print(f"Validation Accuracy: {accuracy * 100:.2f}%")

深度学习相对于传统的机器学习算法有一些优势,尤其在处理复杂、大规模数据以及特征学习方面。以下是深度学习相对于传统机器学习算法的一些优势:
深度学习模型能够通过多个层次进行特征学习,从而自动学习数据中的抽象和复杂特征。这使得模型能够更好地捕捉数据中的非线性关系和层次结构。
大规模数据处理: 深度学习在大规模数据集上表现出色,它可以更好地利用大量数据来训练复杂的模型,从而提高模型的泛化能力。
端到端学习: 深度学习允许端到端的学习,直接从原始数据中学习任务相关的表示,而不需要手工设计特征。
图像和文本处理: 在处理图像和文本等非结构化数据方面,深度学习通常比传统机器学习算法表现更好。卷积神经网络(CNN)在图像处理中取得显著成功,而循环神经网络(RNN)和变体(如长短时记忆网络,LSTM)在序列数据(例如文本)中表现出色。
复杂模型结构: 深度学习模型可以包含大量参数和复杂的结构,从而更好地适应复杂的任务。例如,深度神经网络可以包含数十甚至数百层,而传统机器学习模型通常较为简单。
端到端学习: 无需手动特征工程,深度学习可以通过端到端学习的方式,直接从原始数据中学习任务相关的表示,减少了对手动特征工程的依赖。这有助于简化建模过程,尤其是在处理大量数据时。
适应多任务学习: 深度学习模型通常更适合进行多任务学习,可以共享底层表示学习,从而更好地适应多个相关任务。
虽然深度学习有这些优势,但在某些情况下,传统的机器学习算法仍然可以表现得很好,特别是在数据量较小、特征明确或解释性要求高的情况下。选择使用深度学习还是传统机器学习算法通常取决于具体的问题、数据特点以及计算资源等因素。
5、总结
在进行实际的任务分析的时候,最关键的就是数据预处理、特征工程,在数据预处理的过程中缺失值不能随便填,通常遇到缺值的情况,会有几种常见的处理方式:
①如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
②如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
③如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
④有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
特征工程也非常重要,我们需要首先得到每个特征和数据之间的联系,来确定该数据究竟要不要作为一个特征,否则只会对模型产生副作用,选择最相关和最具信息量的特征,以降低维度并减少噪声的影响。特征选择有助于简化模型并提高泛化性能。
对原始特征进行转换,使其更适合模型的需求。例如,对数变换、标准化、归一化等可以使特征的分布更符合模型的假设。在本次课程设计中,age和fared值如果不进行归一化,会导致模型无法拟合,效果非常差。
姓名属性也有很大的操作空间,姓氏显示了一个人的身份地位、婚姻状态等。将每个分类变量映射到一个由 0 和 1 组成的向量,其中每个元素表示变量是否具有对应的类别。这里可以用独热编码将姓氏转化为可以被理解的特征。
在构建模型的过程中,可以输出预测错的人,来观测并对模型进行优化。
为了防止过拟合,我们也可以使用模型融合。在本例中,预测错误的大部分是三等舱的人,对于一等舱二等舱预测概率非常高,但是对于三等舱的预测效果很差,这么来说,我们是不是可以单独把三等舱的人拿出来进行训练?然后将模型进行融合?这样概率会不会提高?我认为这样做绝对可以。
先不考虑这些,单在模型上我认为还有优化的空间,既然考虑到了模型融合,我们是不是可以用多个模型如KNN、SVM、深度学习?来和逻辑回归进行拟合,然后在预测的时候进行投票?这种思路其实也可以。
还有一种方法,那我们干脆就不要用全部的训练集,每次取训练集的一个subset,做训练,这样,我们虽然用的是同一个机器学习算法,但是得到的模型却是不一样的;同时,因为我们没有任何一份子数据集是全的,因此即使出现过拟合,也是在子训练集上出现过拟合,而不是全体数据上,这样做一个融合,可能对最后的结果有一定的帮助。对,这就是常用的Bagging。
在本例中对比SVM、KNN等,逻辑回归的效果更好,逻辑回归是一个线性分类器,参数的数量较少。在相对较小的数据集上,模型很难过度拟合,避免了过拟合的问题。在处理稀疏特征(特征中有很多零值)的情况下表现较好。这对于文本分类等任务来说是非常重要的,因为文本数据通常以稀疏的方式表示。
深度学习最大的优势,深度学习允许端到端的学习,直接从原始数据中学习任务相关的表示,无需手动特征工程,深度学习可以通过端到端学习的方式,直接从原始数据中学习任务相关的表示,减少了对手动特征工程的依赖。这有助于简化建模过程,尤其是在处理大量数据时。
虽然深度学习有这些优势,但在某些情况下,传统的机器学习算法仍然可以表现得很好,特别是在数据量较小、特征明确或解释性要求高的情况下。选择使用深度学习还是传统机器学习算法通常取决于具体的问题、数据特点以及计算资源等因素。

欢迎大家点赞关注和收藏,有疑问可以私信我!
这篇关于机器学习——泰坦尼克号乘客生存预测(超详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








