本文主要是介绍kaggle|泰坦尼克号生存预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
kaggle|泰坦尼克号生存预测
- 1.数据分析
- 初步分析
- 分类观察
- 可视化观察
- 2.数据处理
- 数据字符替换
- 缺失值填充
- 1.Age
- 2.port
- 3.fare
- 组合新特征
- 3.建立模型
- Random Forest
- Decision Tree
- KNN
- Support Vector Machines
- Logistic Regression
- Linear SVC
- Perceptron
- Stochastic Gradient Decent
- Naive Bayes
https://www.kaggle.com/c/titanic
1.数据分析
初步分析
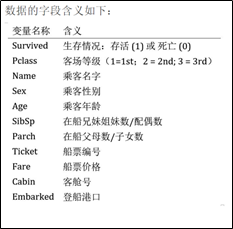
直观上来看,乘客姓名应该与问题关联不大,先假设它是无用数据。
乘客的年龄与性别、船票等级一定是重点数据。
家属数量的多少对生存率影响应该不能直接拿过来分析,需要和其他信息共同探讨,比如该乘客是否是船上所有家属中年龄最小的一个,这种信息会对生存率有影响。
至于船票编号、价格、客舱号,可能会和船票等级有一些联系,它们四者应该可以视为一类信息。
最后一个登船港口,没有想到和存活率有什么直接的关系,即使登船港口暗示了乘客来自的地区(同一地区的人可能会有近似的文化、身体素质)但是这应该需要非常多的数据来确定,仅仅几百条数据应该无法判断,暂时把它假设为无用数据。
分类观察
只看船票等级:
train_df[['Pclass', 'Survived']].groupby(['Pclass'],
as_index=False).mean().sort_values(by='Survived', ascending=False)
Pclass Survived
0 1 0.629630
1 2 0.472826
2 3 0.242363
只看性别:
train_df[["Sex", "Survived"]].groupby(['Sex'],
as_index=False).mean().sort_values(by='Survived', ascending=False)
Sex Survived
0 female 0.742038
1 male 0.188908
泰坦尼克号女士和孩子先走的故事
只看家属数:
train_df[["SibSp", "Survived"]].groupby(['SibSp'],
as_index=False).mean().sort_values(by='Survived', ascending=False)
SibSp Survived
1 1 0.535885
2 2 0.464286
0 0 0.345395
3 3 0.250000
4 4 0.166667
5 5 0.000000
6 8 0.000000
train_df[["Parch", "Survived"]].groupby(['Parch'],
as_index=False).mean().sort_values(by='Survived', ascending=False)
Parch Survived
3 3 0.600000
1 1 0.550847
2 2 0.500000
0 0 0.343658
5 5 0.200000
4 4 0.000000
6 6 0.000000
可视化观察
年龄:
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)#bins是柱数量
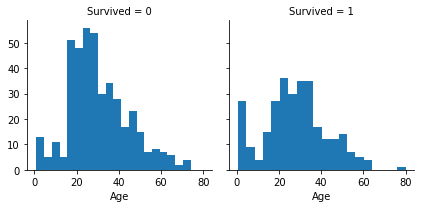
婴儿的存活率相当高
分不同船票等级后观察年龄分布:
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();
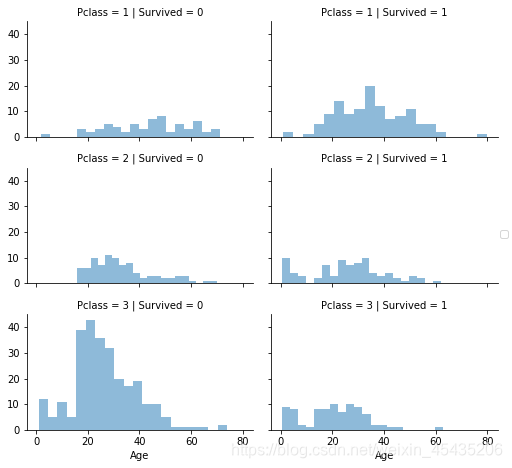
三级船票(最低等船票)的大部分没有活下来,一级船票(最高等船票)的大部分活下来了
上船的港口与船票等级:
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
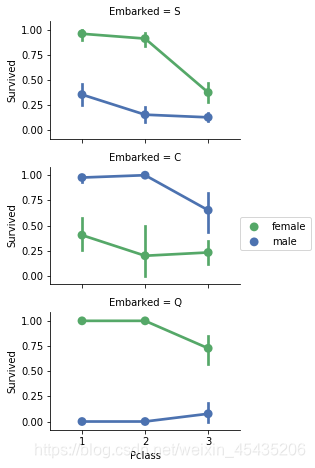
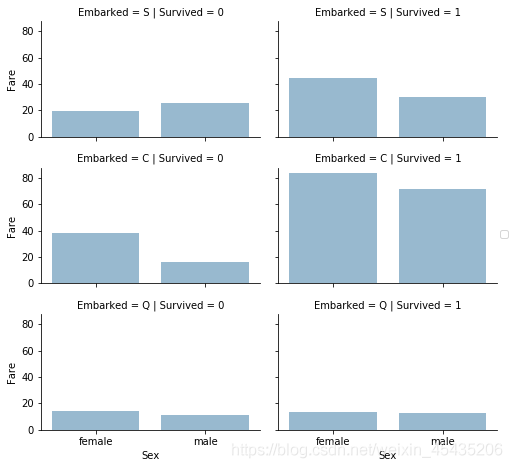
票价:
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()
2.数据处理
数据字符替换
去掉ticket、cabin
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
处理名字,(\w+\)匹配点字符结尾的第一个单词
for dataset in combine:dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])
Sex female male
Title
Capt 0 1
Col 0 2
Countess 1 0
Don 0 1
Dr 1 6
Jonkheer 0 1
Lady 1 0
Major 0 2
Master 0 40
Miss 182 0
Mlle 2 0
Mme 1 0
Mr 0 517
Mrs 125 0
Ms 1 0
Rev 0 6
Sir 0 1
然后将同义词替换
for dataset in combine:dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
Title Survived
0 Master 0.575000
1 Miss 0.702703
2 Mr 0.156673
3 Mrs 0.793651
4 Rare 0.347826
用数字表示上述不同种类的乘客
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:dataset['Title'] = dataset['Title'].map(title_mapping)dataset['Title'] = dataset['Title'].fillna(0)
去掉乘客序数
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
用数字表示性别
for dataset in combine:dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
port数值替换
for dataset in combine:dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
缺失值填充
1.Age
我们可以考虑两种方法来完成填充。
(1).在平均值和标准差之间生成随机数
在平均值和标准差之间生成随机数作为年龄,使整体样本数据不会产生很大的变动。
(2).使用其他相关特性
年龄、性别和职业之间应该具有某种关联。使用不同类别和性别特征组合的年龄中值来猜测年龄值应该更符合实际情况。
对比二者,方法一不同次测试因为生成的随机数不同会造成准确率变动,从稳定性角度来说第二种更好。
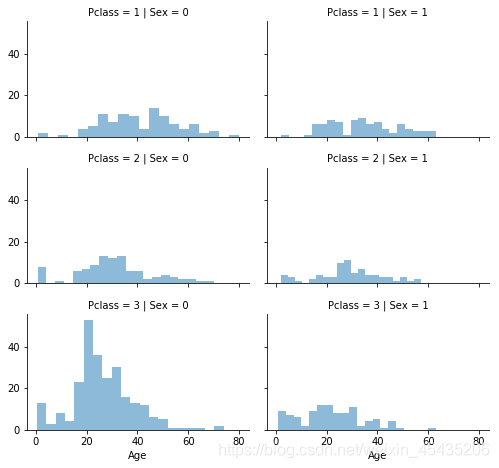
显示pclass、sex下的年龄:
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
迭代Sex(0或1)和Pclass(1,2,3)来计算这六个组合的年龄猜测值
for dataset in combine:for i in range(0, 2):for j in range(0, 3):guess_df = dataset[(dataset['Sex'] == i) & \(dataset['Pclass'] == j+1)]['Age'].dropna()# age_mean = guess_df.mean()# age_std = guess_df.std()# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)age_guess = guess_df.median()# Convert random age float to nearest .5 ageguess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5for i in range(0, 2):for j in range(0, 3):dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\'Age'] = guess_ages[i,j]dataset['Age'] = dataset['Age'].astype(int)train_df.head()
整理年龄段
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)for dataset in combine: dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3dataset.loc[ dataset['Age'] > 64, 'Age']train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
2.port
只缺了几个值,不需要详细分析
freq_port = train_df.Embarked.dropna().mode()[0]
for dataset in combine:dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
3.fare
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)for dataset in combine:dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3dataset['Fare'] = dataset['Fare'].astype(int)train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
组合新特征
FamilySize
for dataset in combine:dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)
IsAlong
for dataset in combine:dataset['IsAlone'] = 0dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()
只保留IsAlong
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]3.建立模型
Random Forest
Decision Tree
KNN
Support Vector Machines
Logistic Regression
Linear SVC
Perceptron
Stochastic Gradient Decent
Naive Bayes
共九种简单的直接调包方法可以选择
# Logistic Regression
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
#逻辑回归的同时,可以观察特征的相关度
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = ['Feature']
coeff_df["Correlation"] = pd.Series(logreg.coef_[0])
a=coeff_df.sort_values(by='Correlation', ascending=False)# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)# KNN
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)# Gaussian Naive Bayes
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)# Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)# Linear SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)# Stochastic Gradient Descent
sgd = SGDClassifier()
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)# Decision Tree
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)#Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
各种模型预测准确度
Model Score
3 Random Forest 86.76
8 Decision Tree 86.76
1 KNN 84.74
0 Support Vector Machines 83.84
2 Logistic Regression 80.36
7 Linear SVC 79.12
5 Perceptron 78.00
6 Stochastic Gradient Decent 76.21
4 Naive Bayes 72.28
投票决定一下最终预测结果,有0.8421的准确率,效果蛮不错


这篇关于kaggle|泰坦尼克号生存预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









