本文主要是介绍【机器学习实战1】泰坦尼克号:灾难中的机器学习(一)数据预处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 🌸博主主页:@釉色清风
- 🌸文章专栏:机器学习实战
- 🌸今日语录:不要一直责怪过去的自己,她曾经站在雾里也很迷茫。
🌼实战项目简介
本次项目是kaggle上的一个入门比赛 :Titanic——Machine Learning from Disaster(泰坦尼克号——灾难中的机器学习),比赛选择了泰坦尼克号作为背景,并提供了样本数据以及测试数据,要求我们使用机器学习创建一个模型,预测哪些乘客在泰坦尼克号沉船中幸存下来。
🌼数据文件说明
🌻泰坦尼克号项目页面:Titanic——Machine Learning from Disaster
🌻可下载的Data页面:

可下载包括三个文件:
- train.csv:训练数据
- test.csv:测试数据
- gender_submission.csv :提交结果案例
🌻数据变量说明
下载好文件,可知,每个乘客有12个属性。

- Passengerld :乘客唯一识别ID
- Survived:是否存活,0为否,1为是
- Pclass :客舱等级,分为1、2、3等级,与英国的阶级分层有关
- Name:姓名
- Sex:性别
- Age:年龄
- SibSp:泰坦尼克号上的兄弟姐妹/配偶数量(与该乘客一起旅行的)
- Parch:泰坦尼克号上的父母/孩子数量(与该乘客一起旅行的)
- Ticket:船票号
- Fare:船票价格
- Cabin:客舱编号
- Embarked:上船的港口编号(S=Southampton,英国南安普顿[启航点];C=Cherbourg,法国瑟堡市[途径点];Q=Quenstown,爱尔兰昆市[途径点])
🌼数据预处理
数据的质量直接决定模型预测的结果。所以,在进行训练模型之前,我们必须要进行数据清洗。
接下来我们使用Jupyter Notebook来进行接下来的数据描述和预处理。
🌻读入数据
首先,我们导入pandas库,它是python中进行数据分析和处理的一个库。然后我们读入我们的训练数据集。
🌾导入数据

🌾打印数据的前几行

默认是打印前五行,如下:

🌻做简单的统计分析

统计特性如下:
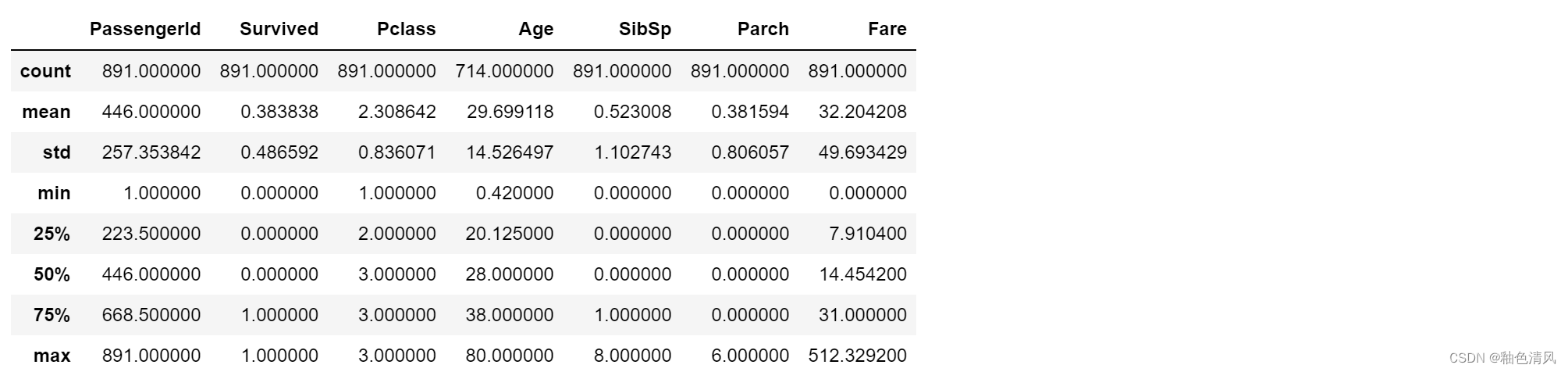
统计有
- count: 这一列的数量(只要不是缺失值就被统计)
- mean:平均值
- std : 方差
- min:最小值
- 25%:下四分位数
- 50%:中位数
- 75%:上四分位数
- max: 最大值
通过大致的浏览,我们可以看到,Age列含有缺失值。
🌻对[Age]列缺失值进行填充
一般对于缺失值的填充用到均值、中位数等。在这里,我们采用均值对Age列的缺失值进行填充。在填充缺失值这里我们用到了fillna函数。
🌾fillna函数
- fillna是一个用于填充缺失值的函数,它是pandas库中的一个方法。
- fillna函数的基本语法如下:
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)

🌾对[Age]列的缺失值采用均值填充法填充

填充完之后,我们再次describe。

如下图:
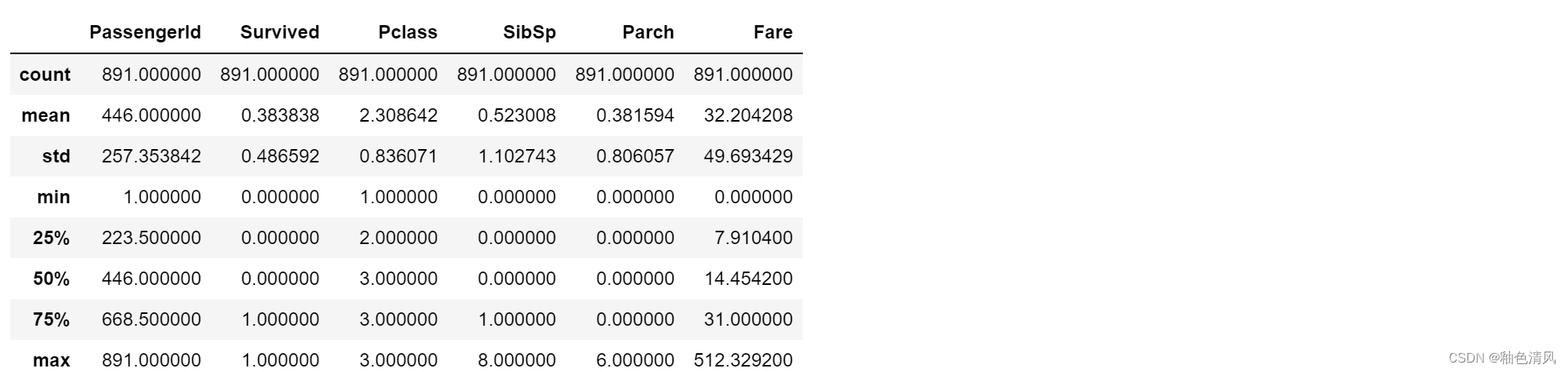
🌻将字符型转化为数值型数据
我们知道,计算机是可以处理数字的,但是无法处理字符。为了方便统计,我们将性别[Sex]和上船港口编号[Embarked]这两列列进行处理。
🌾对[Age]列进行替换

我们在这里用到DataFrame的loc属性:
- 在Python中,loc是一个用于数据框(DataFrame)的属性,它用于选择满足特定条件的行。loc可以通过标签或布尔数组来选择行。
- 常见的用法有:
- 使用标签选择行:
df.loc[label]
2.使用布尔数组选择行:
df.loc[bool_array]
3.使用标签和列选择行和列:
df.loc[start_label:end_label, start_column:end_column]
- 使用标签选择行:
这里我们则采用3进行替换:

🌾对[Embarked]列进行替换

替换:

然后我们进行统计新描述,发现中的数量889,存在从缺失值。

这时,我们对三个登船地点进行统计计数。发现0是最多的,即在S处登船的人最多。

所以对于缺失值,我们将用0进行填充。

这篇关于【机器学习实战1】泰坦尼克号:灾难中的机器学习(一)数据预处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






