正态专题

概率论(二)-随机变量及其分布:分布函数F(x)、离散型随机变量【分布律:(0-1)分布、二项分布、泊松分布】、连续型随机变量【概率密度:均匀分布、指数分布、正态/高斯分布】、3σ法则、偏度、峰度
1 随机变量 2 离散型随机变量及其分布律 3 随机变量的分布函数 4 连续型随机变量及其概率密度 5 随机变量的函数的分布

综合评价 | 基于层次-熵权-变异系数-正态云组合法的综合评价模型(Matlab)
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 综合评价 | 基于层次-熵权-变异系数-正态云组合法的综合评价模型(Matlab) AHP层次分析法是一种解决多目标复杂问题的定性和定量相结合进行计算决策权重的研究方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准

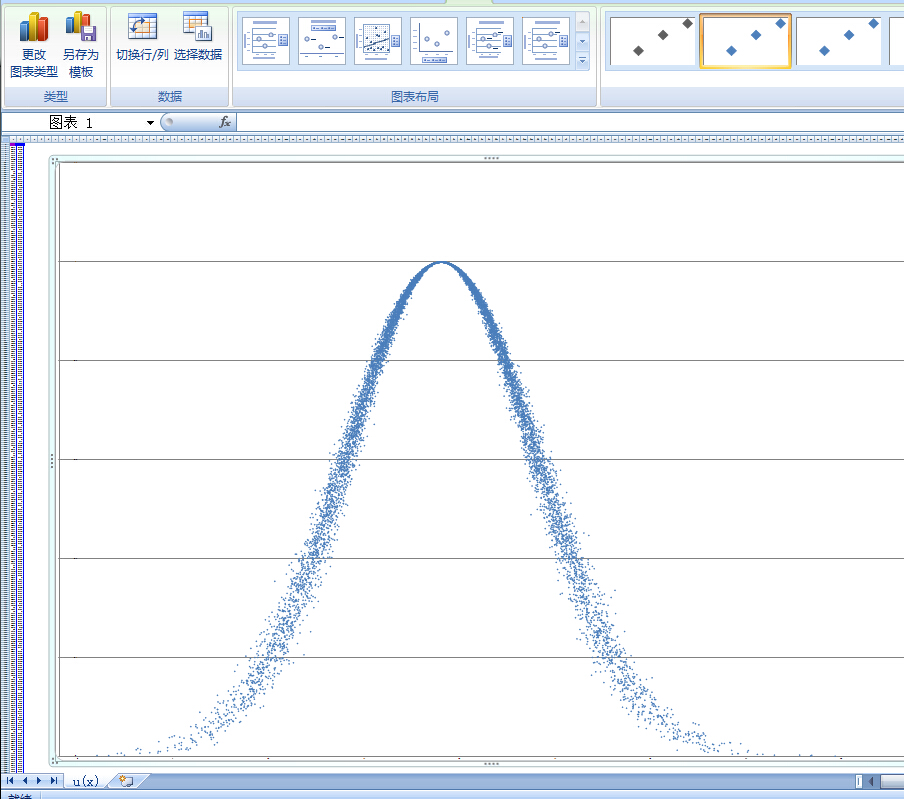
引入分布函数和概率密度函数解释:三种常见连续型随机变量的分布(均匀、指数、正态)
连续性随机变量及其分布 在概率论和统计学中,我们常常会接触到连续性随机变量及其分布。连续性随机变量的一个显著特征是其取值可以在一个连续的范围内变化,比如温度、身高、体重等。为了更好地理解和分析这些随机变量,我们需要使用分布函数和概率密度函数。 分布函数和概率密度函数 **分布函数(Cumulative Distribution Function, CDF)**是描述一个随机变量取值小于或等于
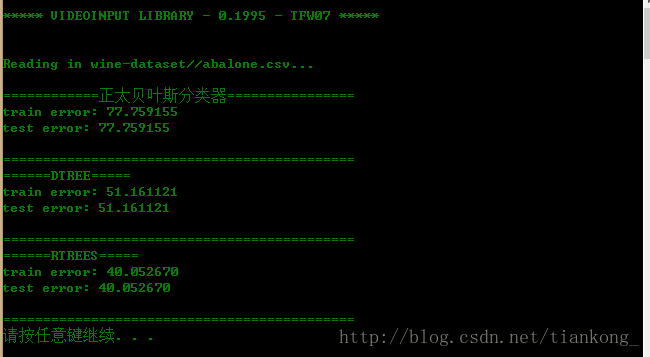
机器学习-采用正态贝叶斯分类器、决策树、随机森林对abalone数据集分类
1.abalone(鲍鱼)数据集描述 http://archive.ics.uci.edu/ml/datasets/Abalone 总共包含4177条数据,每条数据中包含8个特征值,一个分类(鲍鱼年龄,看看圈数),可以看做是分类问题或者回归问题 2.数据集预处理 数据的部分展示 Sex / nominal / -- / M, F, and I (infant) Length /

机器学习-采用正态贝叶斯分类器、决策树、随机森林对wine数据集分类
关于wine数据集描述:http://archive.ics.uci.edu/ml/datasets/Wine #include "opencv2/ml/ml.hpp"#include "opencv2/core/core.hpp"#include "opencv2/core/utility.hpp"#include <stdio.h>#include <string>#in

机器学习-采用正态贝叶斯分类器对wine分类
1.数据集的准备 我采用UCI中的Wine Data Set 下载地址:http://download.csdn.net/download/tiankong_/10120450 数据描述: 第一列为类属性 ,用1,2,3表示,后面13列为特征属性,分别为Alcohol,Malicacid,Ash,Alcalinity of ash,Magnesium,Total phenols,Flav


python实现区间估计,一个正态总体,均值已知,未知的区间估计,正态分布,t 分布
首先导入数据,这里使用的是一次数据竞赛的 train_label 的数据,即房租的价格 数据可在百度网盘中下载 链接:https://pan.baidu.com/s/1_4GI4_N3zWZGO9LgFP7RKA 提取码:yk5F import pandas as pdimport numpy as npfrom scipy import statsdata = pd.read_csv('

斯坦福机器学习 Lecture2 (假设函数、参数、样本等等术语,还有批量梯度下降法、随机梯度下降法 SGD 以及它们的相关推导,还有正态方程)
假设函数定义 假设函数,猜一个 x->y 的类型,比如 y = ax + b,随后监督学习的任务就是找到误差最低的 a 和 b 参数 有时候我们可以定义 x0 = 1,来让假设函数的整个表达式一致统一 如上图是机器学习中的一些术语 额外的符号,使用 (xi, yi) 表示第 i 个样本 n 表示特征数量 (在房屋价格预测问题中,属性/特征有两个:房子面积和卧室数量,因此这里 n =
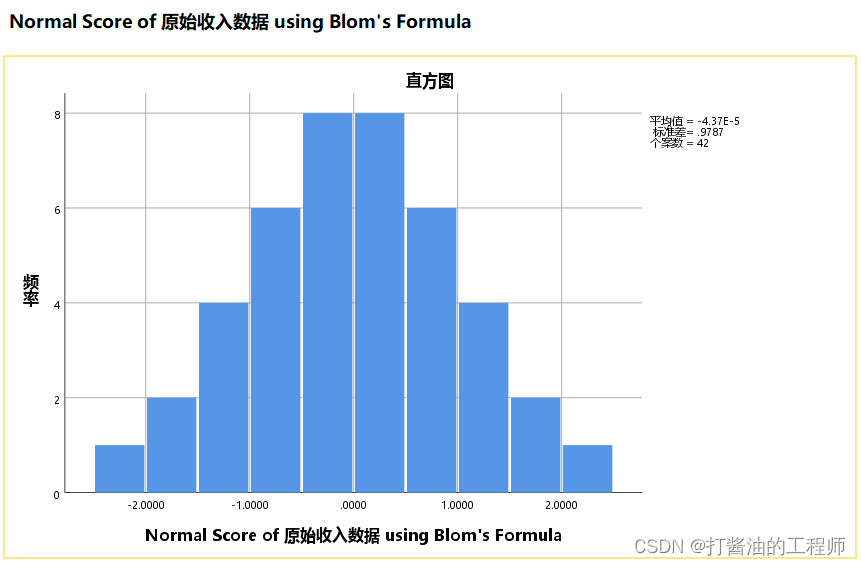
学习笔记|正负偏态的转换方法|对数转换|正态得分法|适用条件|《小白爱上SPSS》课程:加餐 | 如何将非正态分布数据转换为正态分布的?手把手教你SPSS操作
目录 学习目的软件版本原始文档将非正态分布数据转换为正态分布一、正负偏态的转换方法(一)正偏态数据转换方法(二)负偏态数据转换方法 三、正态性检验(一)操作如下(二)结果解读四、SPSS:对数转换法(一)选择检验方法和操作步骤(二)结果验证和解读 五、SPSS:正态得分法需要注意 六、划重点 学习目的 加餐 | 如何将非正态分布数据转换为正态分布的?手把手教你SPSS操作

概率论与数理统计学习笔记——6.4正态总体统计量的分布
标准正态分布函数Φ(x)很重要,所以用Φ(x)来代表这个函数,也就是说如果问你标准正态函数是多少,你就可以说是Φ(x)。 定理6.4.1 定理6.4.2 定理6.4.3 定理6.4.4 定理6.4.1: 定理6.4.2: 注意,样本方差不是均值方差。 定理6.4.3: 定理6.4.4: 定理6.4.5:

概率统计Python计算:单个正态总体均值单侧假设的T检验
正态总体的方差 σ 2 \sigma^2 σ2未知的情况下,对总体均值 μ ≤ μ 0 \mu\leq\mu_0 μ≤μ0(或 μ ≥ μ 0 \mu\geq\mu_0 μ≥μ0)进行显著水平 α \alpha α下的假设检验,检验统计量 X ‾ − μ 0 S / n \frac{\overline{X}-\mu_0}{S/\sqrt{n}} S/n X−μ0~ t ( n −

Python数据分析之假设检验:正态总体均值检验、配对样本t检验、总体比率检验、A/B测试
假设检验原理 反证法小概率事件在一次试验中是几乎不可能发生的(但在多次重复试验中是必然发生的) 假设检验的步骤 设置原假设与备择假设;设置显著性水平 α \alpha α(通常选择 α = 0.05 \alpha=0.05 α=0.05);根据问题选择假设检验方式;计算统计量,并通过统计量获取P值根据P值和显著性水平 α \alpha α值,决定接受原假设还是备择假设。 原假设备择假设的设
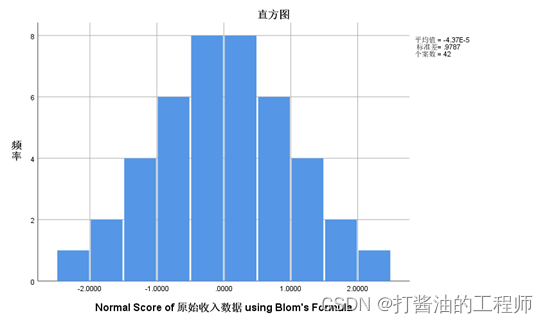
SPSS|正负偏态的转换方法|限值1.96|反转后处理(对数法)|正态得分法|实战小练-SPSS学习(2)
目录 学习目的软件版本参考文档基础数据正负偏态的转换方法(引自《小白爱上SPSS》)正偏态数据转换方法负偏态数据转换 实战数据准备数据初探输出结果分析查看峰度、偏度查看峰度标准误差、偏度标准误差计算偏度系数和峰度系数Tips:为什么判断限值是1.96?样本量过大的情形正态性检验结果结果解读 正负偏态的转换选择检验方法和操作步骤Step1:反转Step2: 反转后处理(以对数转换为例) 反
三大分布及正态总体下的抽样分布(待完善)
一、卡方分布 1、定义 都为平方,因此x大于0 2、图像 n趋近于无穷,为正态分布 3、性质 (1)自由度可加性 (2)均值与方差 二、t分布 分子服从正态分布,定义域为负无穷至正无穷。分子服从卡方分布,定义域为正。综上,t分布定义域为负无穷至正无穷。 三、F分布 四、一个正态总体下的抽样分布 1、公式1 2、公式2

小样本不符合正态_小空间,大学问,不一样的卫生间,符合居家的设计搭配
卫生间的面积不大,在很多户型中只有3-5平,我们也要做好设计,当然卫生间的设计也是每个家庭装修要考虑的问题。 今天,尚业装饰就来给大家分析一些装修卫生间的方法技巧,看看在做卫生间装修时要考虑那些细节问题。 1、要明白那些功能是必须的。 淋浴、如厕、洗漱台这三样是卫生间的必须功能。想浴缸,淋浴房这些刚看具体的空间和业主的要求来添加。 2、卫生间布局设计原则。 干湿分离,洗手盆外置。马桶和淋

揭秘PLNet:用泊松对数正态图网络分析助力单细胞RNA测序数据处理大突破
今天我们介绍一篇来自北京大学数学科学学院的肖飞轶、唐俊杰发表在NeurIPS 2022会议上的工作,该文章研究了用于计数数据的图形模型估计方法,应用于单细胞基因网络分析。文章介绍了PLN图形模型的概念及其在单细胞基因调控网络分析中的应用。研究表明,该图形模型能够较好地解释单细胞基因表达数据,有助于揭示基因网络的调控机制。文章还探讨了该模型的应用前景和改进方向。 背景介绍 高斯图模型已在许多不同
![利用norm.ppfnorm.interval分别计算正态置信区间[实例]](/front/images/it_default.gif)
利用norm.ppfnorm.interval分别计算正态置信区间[实例]
scipy.stats.norm.ppf用于计算正态分布的累积分布函数CDF的逆函数,也称为百分位点函数。它的作用是根据给定的概率值,计算对应的随机变量值。scipy.stats.norm.interval:用于计算正态分布的置信区间,可指定均值和标准差。scipy.stats.t.interval:用于计算t分布的置信区间,可选择使用不同的置信水平和自由度。 import scipy.stat