本文主要是介绍SPSS|正负偏态的转换方法|限值1.96|反转后处理(对数法)|正态得分法|实战小练-SPSS学习(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 学习目的
- 软件版本
- 参考文档
- 基础数据
- 正负偏态的转换方法(引自《小白爱上SPSS》)
- 正偏态数据转换方法
- 负偏态数据转换
- 实战
- 数据准备
- 数据初探
- 输出结果分析
- 查看峰度、偏度
- 查看峰度标准误差、偏度标准误差
- 计算偏度系数和峰度系数
- Tips:为什么判断限值是1.96?
- 样本量过大的情形
- 正态性检验结果
- 结果解读
- 正负偏态的转换
- 选择检验方法和操作步骤
- Step1:反转
- Step2: 反转后处理(以对数转换为例)
- 反转后数据再探索
- 正态得分方法
- 正态得分法的缺点
- 重点回顾
学习目的
利用SPSS,将非正态分布数据转换为正态分布。
软件版本
IBM SPSS Statistics 26。
参考文档
《小白爱上SPSS》课程
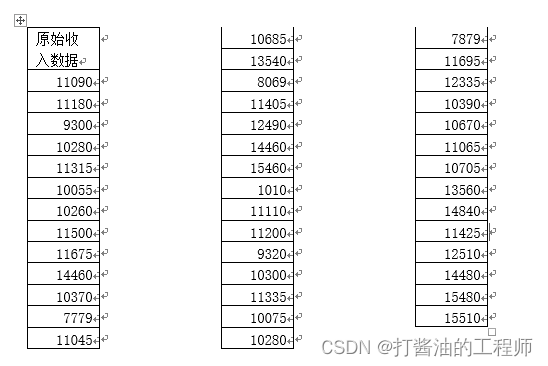
基础数据
《小白爱上SPSS》课程中的加餐原始数据。
正负偏态的转换方法(引自《小白爱上SPSS》)
正态分布转换方法有很多,比如:对数变换、平方根变换、平方根反正弦变换、平方变换、倒数变换、Box-Cox变换、正态得分法。
这里选择几种常用方法讲解,起示范作用。数据转换分成两种情况,一种是正偏态数据,另一种是负偏态数据,每种又分成轻度、中度和严重三种情况。
正偏态数据转换方法
- 1、轻度正偏态分布
当偏度值>0,偏度值为其标准误差的2-3倍,即Z-score=2~3,此时认为资料分布呈现轻度的正偏态分布,故考虑对变量x取根号开平方的方法来进行转换。
SPSS语句如下:
COMPUTE x_new = SQRT(x)
(SQRT为开平方根Square Root缩写) - 2、中度正偏态分布
当偏度值>0,偏度值为其标准误差的3倍以上时,即Z-score>3,此时认为资料分布呈现中度的正偏态分布,可以考虑对变量x取对数来进行转换。可以取自然对数(ln)或以10为底的对数(log10)。
SPSS语句如下:
COMPUTE x_new = LN(x)
COMPUTE x_new = LG10(x)
注意:LG10的纠正力度较强,有时甚至会矫枉过正,将正偏态转换为负偏态,因此在进行正态转换后一定要对该变量再次进行正态性检验。 - 3、重度正偏态分布
对于两端波动比较大的数据资料,极端值可能产生较大的影响,此时可以考虑取倒数的方法来进行转换。
SPSS语句如下:
COMPUTE x_new = 1/x
若你不太熟悉SPSS语法编辑窗口,则可通过SPSS中“转换”—“计算变量”实现,找到sqrt, ln, lg10等函数。
注意:根号下要求数据均为非负数(即≥0),对数要求数据均为正数(即>0);取倒数要求分母不为0, 如果变量x中出现上述情况,则需要先将其进行一定的转换,如x+K或K-x,再对其取根号、对数或倒数。其中K为一个常数,可以根据需要进行赋值,例如赋值为1,或取数据的最小值、最大值等。
负偏态数据转换
对于负偏态分布的数据资料,首先需要将负偏态资料进行反转,转换为正偏态,然后再参考正偏态分布资料的转换方法进行转换。
反转的方法:首先找出该数据系列的最大值max,用最大值+1,再减去每个数值。
- 1、轻度负偏态分布
SPSS语句如下:
COMPUTE x_new = SQRT(max+1-x) - 2、中度负偏态分布
SPSS语句如下:
COMPUTE x_new = LN(max+1-x)
COMPUTE x_new = LG10(max+1-x) - 3、重度负偏态分布
SPSS语句如下:
COMPUTE x_new = 1/(max+1-x)
实战
42名员工的月收入,试检验其正态性。若不服从正态性,请将其转化为正态分布。
数据准备
输入SPSS中,可选择excel文件导入,导入后数据如下:
数据初探
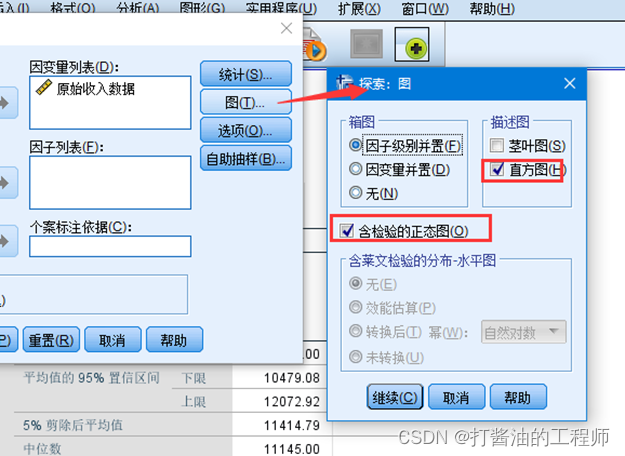
完成数据输入后,在主界面依次点击:分析-描述统计-探索:
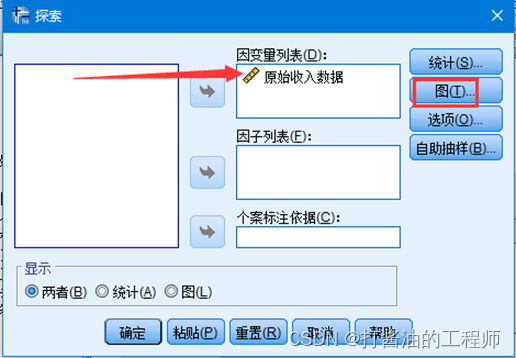
将“原始收入数据”选入因变量列表,点击 图 --勾选直方图–勾选含检验的正态图–继续–确定。
输出结果分析
查看峰度、偏度
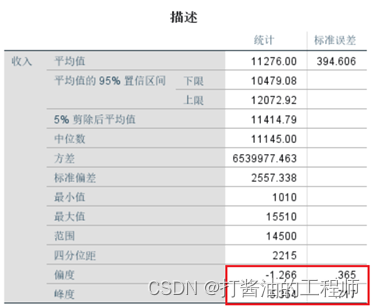
查看峰度标准误差、偏度标准误差
这里要通过频率选项:
频率中,将原始收入数据加入“变量”,选择“统计”,显示频率表选项可按需勾选:
统计中的选项:
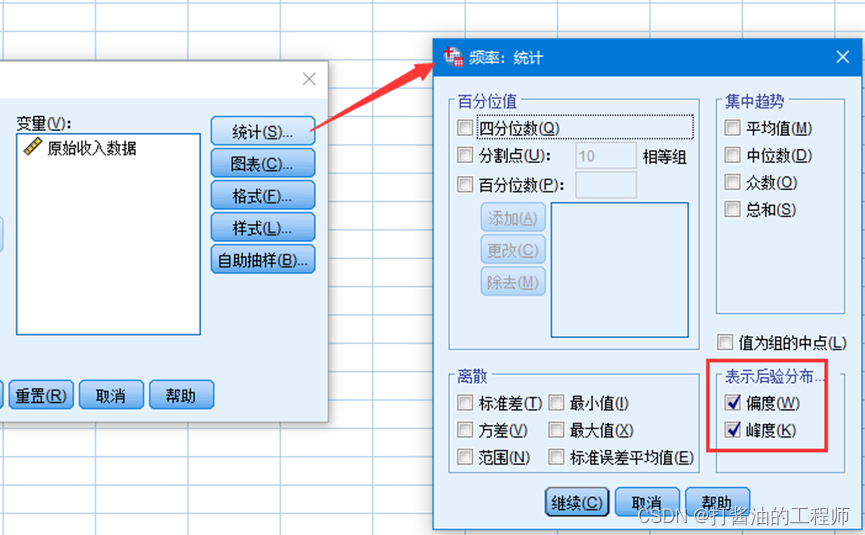
选中后验分布中的偏度,峰度,按继续-确定,输出频率统计表:
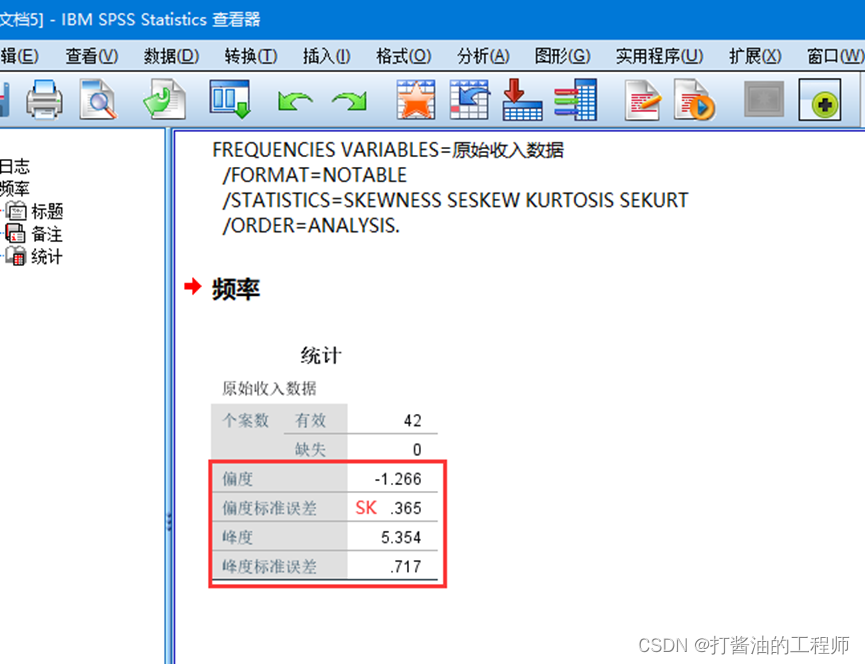
计算偏度系数和峰度系数
偏度系数:

峰度系数:

由计算结果,偏度系数和峰度系数的绝对值均大于1.96,可以认为该组样本数据不服从符合正态分布。
Tips:为什么判断限值是1.96?
概念引自百度百科:标准正态分布。
标准正态分布(英语:standard normal distribution, 德语Standardnormalverteilung),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。期望值μ=0,即曲线图象对称轴为Y轴,标准差σ=1条件下的正态分布,记为N(0,1)。
标准正态分布又称为u分布,是以0为均数、以1为标准差的正态分布,记为N(0,1)。
标准正态分布曲线下面积分布规律是:在-1.96~+1.96范围内曲线下的面积等于0.9500,在-2.58~+2.58范围内曲线下面积为0.9900。统计学家还制定了一张统计用表(自由度为∞时),借助该表就可以估计出某些特殊u1和u2值范围内的曲线下面积。

查标准正态分布表,当α=0.05时,进行区间估计,两侧分别是0.05/2=0.025,查标准正态分布表时找到0.975,对应的Z值就是1.96。所以偏度系数和峰度系数的绝对值的判断限值是1.96。
样本量过大的情形
注意:当样本量过大(超过100)时,采用峰度和偏度系数会对正态性的情况有所偏误,此时,可以直接尝试采用图示法(直方图、P-P、Q-Q)的方法进行检验会更直观。
正态性检验结果
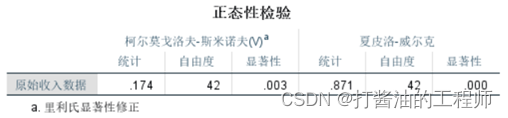
结果解读
当数据量≤50时,倾向于以夏皮洛-威尔克(S-W)检验结果为准;
当数据量>50时,倾向以柯尔莫戈洛夫-斯米诺夫(K-S)检验结果为准;
当数据量>5000时,SPSS只会显示K-S检验结果。
本例中,我们检验42名员工收入的正态分布情况,由上表显示,样本量(可参考自由度那一列数值)小于50,故以夏皮洛-威尔克(S-W)检验结果为准。检验的p值(即显著性那一列)为0.000,小于0.05,说明42名员工收入不符合正态分布,故认为收入不满足正态性。
正负偏态的转换
选择检验方法和操作步骤
由上可知,因本案例中偏度值(-1.266)<0,为负偏态,偏度值为其标准误差的3倍以上(偏度系数Z=3.468>3),故考虑对变量x取对数来进行转换。
对于负偏态分布的数据资料,首先需要将负偏态资料进行反转,转换为正偏态,然后再参考正偏态分布资料的转换方法进行转换。
Step1:反转
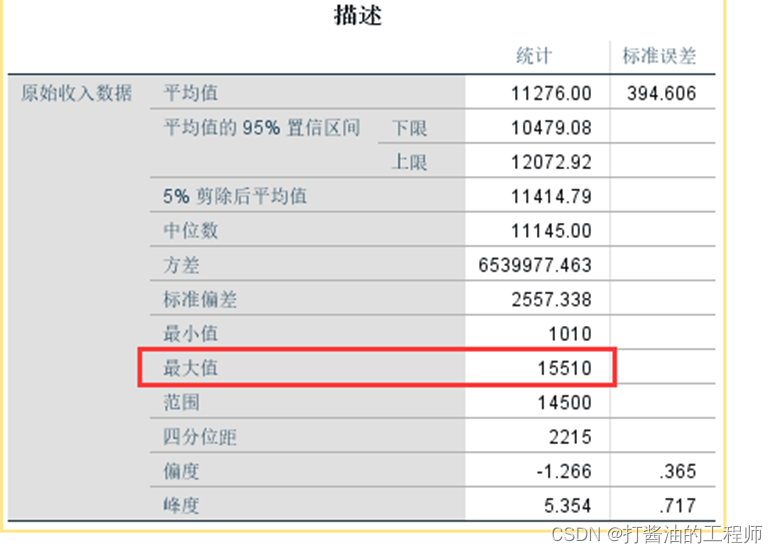
方法为:首先找出该数据系列的最大值max,用最大值+1,再减去每个数值,本例子中最大值为15510,处理后数据名称为“反转后数据”,数据处理如下:
在描述表格中找到最大值:
添加计算变量,生成新的列:
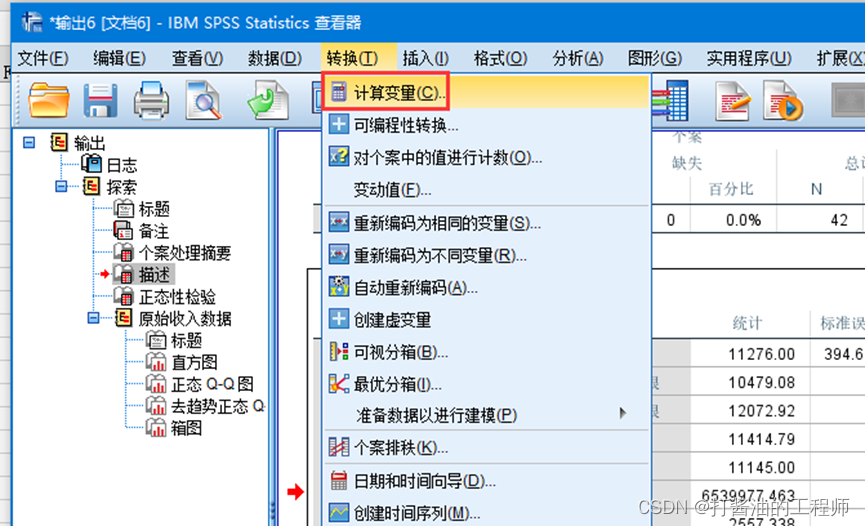
新列命名为“反转的列”:
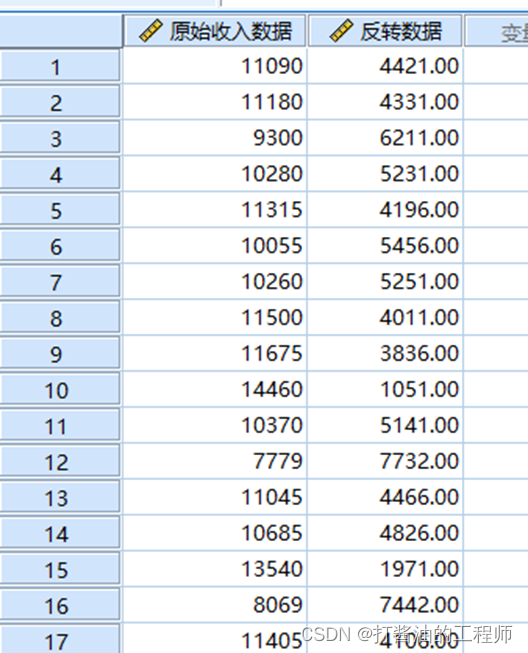
生成结果如下:
Step2: 反转后处理(以对数转换为例)
根据前述说明,数据按中度正偏态(对数转换)处理。
对反转后数据进行对数转换,以Log10为例,步骤如下:
(1) 选择转换→ 计算变量;
(2) 在目标变量(T)框中输入一个新的变量名,作为数据转换后的变量名,此处设定为新收入数据;
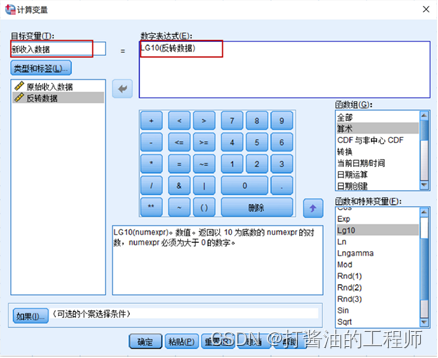
(3) 在函数组中选择算数,在函数和特殊变量中双击Lg10,此时在数字表达式框中显示LG10(?);
(4) 从变量列表中双击反转后数据,此时在数字表达式框中显示LG10(反转数据)。
(5) 点击确定完成操作,操作完成,出现新收入数据列。

重新执行数据探索。
反转后数据再探索
输出描述:
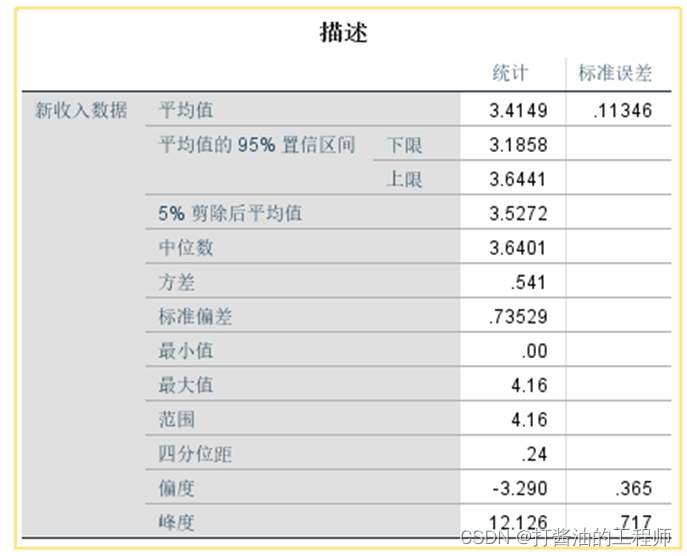
正态性检验:
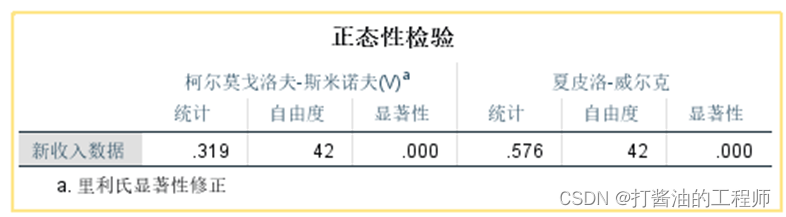
在结果输出的描述表格中显示,计算偏度系数(.329/.365=9.014)和峰度系数(12.126/.717=16.912)均大于1.96,正态性检验p(0.000)<0.001,故说明转换后数据仍不服从正态分布(读者可以采用【倒数】转换方法尝试下,结果仍然不服从正态分布)。
至此,原作者建议不再进行正态分布数据转换尝试,而采用非参数检验方法。
因为,一般而言,收入这个变量的总体数据是不服从正态分布的。
正态得分方法
当然,我们也可采用正态得分方法操作,使其转换为正态分布。
选择转换→个案排秩检验:
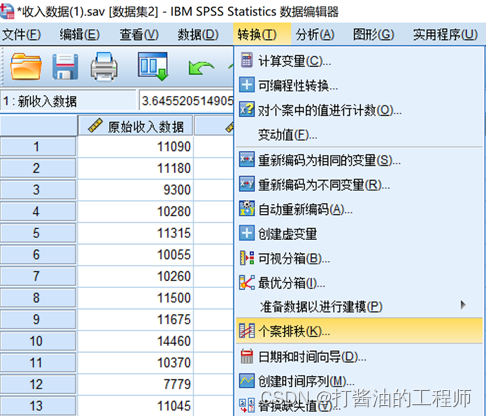
将收入选入变量(V)框中点击类型排秩选项框,取消默认勾选的秩,勾选正态得分选项。在比例估算公式下有4种方法可供选择,默认Blom方法,其他方法也可以进行尝试,点击继续再点击确定完成操作。
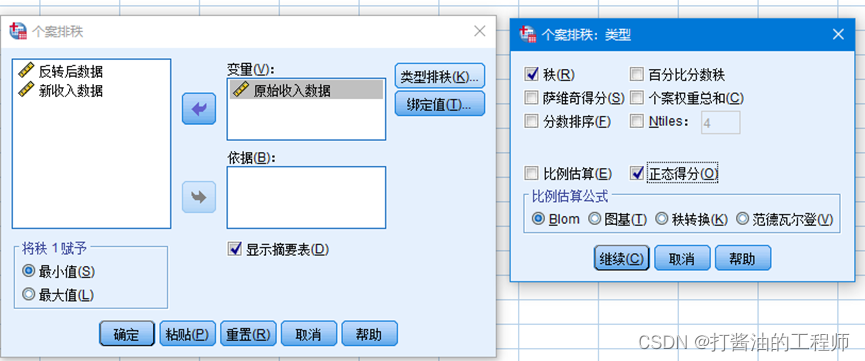
我们可以看到在程序运行后在变量列表中多出了一个名为N原始的新变量,即为计算的正态得分。
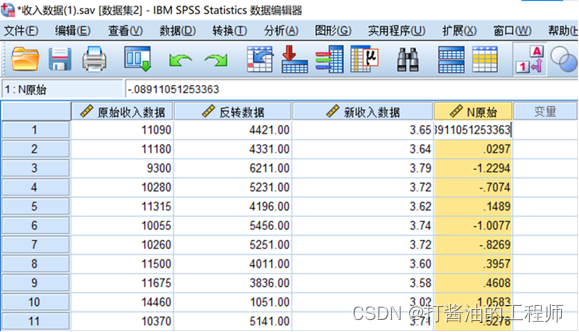
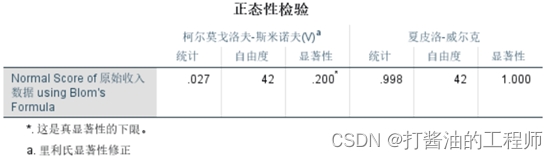
下图为采用探索方法对N原始收入数据正态性检验以验证转化效果。
在结果输出的描述表格中显示,偏度系数和峰度系数均小于1.96,正态性检验p=1.000>0.05,故说明转换后数据服从正态分布。
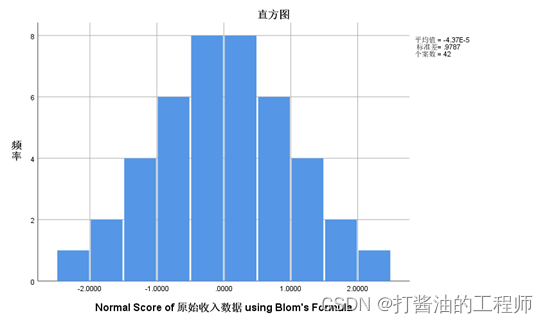
图示也能看到比较明显的正态分布特征:
正态得分法的缺点
需要注意:基于正态得分法得到的数据,在编秩过程中额外地加入原本不属于数据本身的分布特征,因此在一般统计方法中,并不能直接当做正态数据使用,其标准差、方差等信息与原始数据的计算结果也并不一样。这种转换,仅能用作在构建复杂模型时的探索。
重点回顾
(1)正态分布转换方法有很多,包括:对数变换、平方根变换、平方根反正弦变换、平方变换、倒数变换、Box-Cox变换(SPSS软件实现不了)和正态得分法等。
(2)不是任何非正态数据都可以进行正态转换,只有把握认为数据的总体分布是正态的时候才可做正态转换。
(3)如果一种正态分布转换方法没成功,则需要多次其他转换方法,甚至要创造性提出转换方法,从中选择效果较好者。
(4)如果通过多次变量转换的方法依然无法转换成功,就不再适用于T检验、方差分析等方法了,这时可采用前期介绍过的非参数检验的方法来进行分析,例如Wilcoxon检验和Mann-Whitney U检验方法等。
(5)在对线性回归模型进行解释时,如果使用函数转换的方法对变量进行转换,则应对转换后的变量给予解释,或者可以根据转换时使用的函数关系,倒推原始自变量对原始因变量的效应大小。
这篇关于SPSS|正负偏态的转换方法|限值1.96|反转后处理(对数法)|正态得分法|实战小练-SPSS学习(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








