得分专题

3276. 选择矩阵中单元格的最大得分
Powered by:NEFU AB-IN Link 文章目录 3276. 选择矩阵中单元格的最大得分题意思路代码 3276. 选择矩阵中单元格的最大得分 题意 给你一个由正整数构成的二维矩阵 grid。 你需要从矩阵中选择 一个或多个 单元格,选中的单元格应满足以下条件: 所选单元格中的任意两个单元格都不会处于矩阵的 同一行。 所选单元格的值 互不相同。 你的得分为

新SAT官方范文得分的分段分析
· 本次官方给出了两道写作新样题,样题的材料文章分别是节选自Paul Bogard于2012.12.21发表在《洛杉矶时报》的“Let There Be Dark.”及Dana Gioia于2005.04.10发表在《纽约时报》的“Why Literature Matters” 。 · 张卉老师结合之前的新SAT改革的说明,认为写作部分的基本出题思路没有大的调整,样题的材料文章都是节选自

【动态规划】【hard】力扣1301. 最大得分的路径数目
给你一个正方形字符数组 board ,你从数组最右下方的字符 ‘S’ 出发。 你的目标是到达数组最左上角的字符 ‘E’ ,数组剩余的部分为数字字符 1, 2, …, 9 或者障碍 ‘X’。在每一步移动中,你可以向上、向左或者左上方移动,可以移动的前提是到达的格子没有障碍。 一条路径的 「得分」 定义为:路径上所有数字的和。 请你返回一个列表,包含两个整数:第一个整数是 「得分」 的最大值,第
通过改变boost值来改变文档的得分源码
在进行相关度排序的时候,如果想加某个文档的相关度,使其在搜索解雇中排名更加靠前的位置上,则使用boost。 代码: package change; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.do

2010-2022年 上市公司彭博ESG披露评分、分项得分(披露评分、ESG披露评分、环境披露评分、社会信息披露评分、治理披露)
彭博ESG披露评分是彭博公司推出的评估工具,用于衡量全球上市公司在环境(E)、社会(S)和公司治理(G)方面的信息公开程度。评分依据公司年报和可持续发展报告等公开文件,满分为100分。原始数据涵盖2010至2022年间的披露评分及其分项得分。 数据指标 股票代码、年份、 ESG 、 E 、 S 、 G、代码、简称、ESG披露评分、环境披露评分、社会信息披露评分、治理披露评分。 https:
C语言编程:青年歌手参加歌曲大奖赛,有10个评委打分(满分10分),去掉最高最低分后,试编程求选手的平均得分
C语言编程:青年歌手参加歌曲大奖赛,有10个评委打分(满分10分),去掉最高最低分后,试编程求选手的平均得分: 代码如下: #include<stdio.h>void main(){int sum = 0,i;double avg,b;int a[10];int max,min;for(i=0;i<10;i++){scanf("%d",&a[i]);if(i==0)//只有第一次赋值m
Score Matching(得分匹配)
Score Matching(得分匹配)是一种统计学习方法,用于估计概率密度函数的梯度(即得分函数),而无需知道密度函数的归一化常数。这种方法由Hyvärinen在2005年提出,主要用于无监督学习,特别是在密度估计和生成模型中。 基本原理 在概率论中,得分函数(Score Function)是概率密度函数关于其参数的梯度。对于一个随机变量 x x x 的概率密度函数 p ( x ) p(
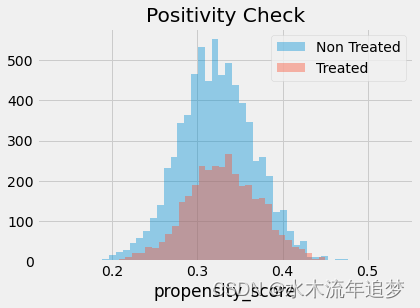
【因果推断python】24_倾向得分2
目录 倾向加权 倾向得分估计 倾向加权 好的,我们得到了倾向得分。怎么办?就像我说过的,我们需要做的就是以此为条件。例如,我们可以运行一个线性回归,它仅以倾向得分为条件,而不是所有的 X。现在,让我们看一下只使用倾向得分而不使用其他任何东西的技术。这个想法是用倾向得分写出均值的条件差 我们可以进一步简化这一点,但让我们这样看一下,因为它让我们对倾向得分的作用有了一些很

每日练习之字符串——得分
得分 题目描述 运行代码 #include <iostream>using namespace std;int main(){int n;cin>>n;while(n--){string s;cin>>s;int l=s.length();int a=0;int t=1;for(int i=0;i<l;++i){if(s[i]=='O'){a+=t;t++;}else if(s[i
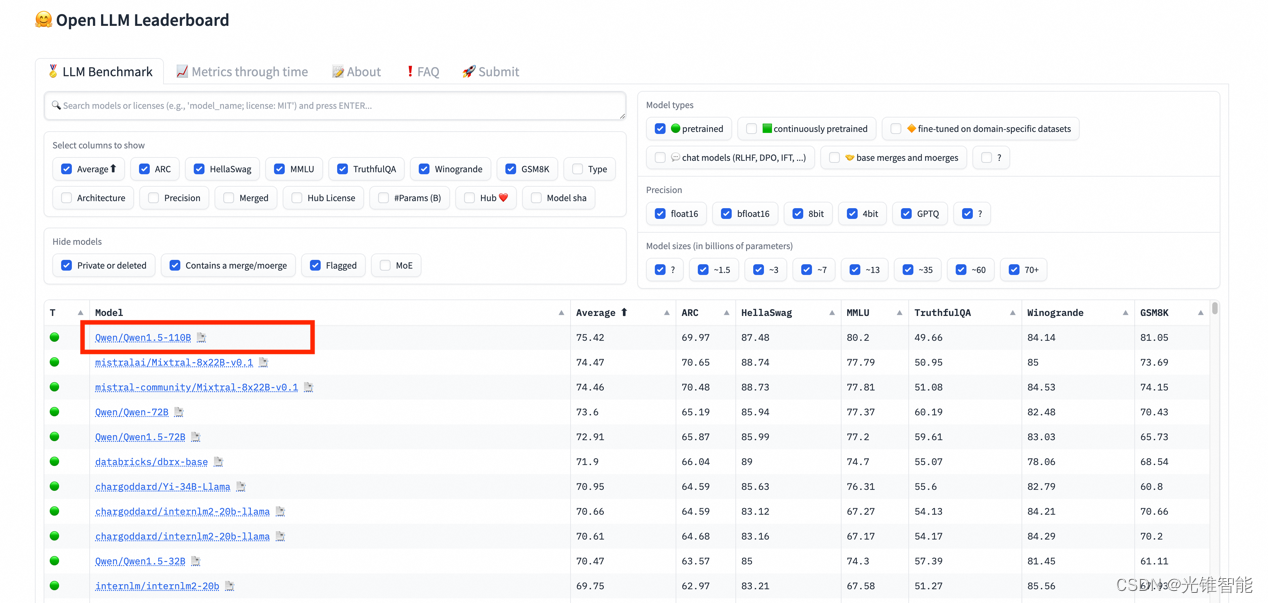
阿里云发布通义千问2.5,OpenCompass上得分追平GPT-4 Turbo
5月9日消息,阿里云正式发布通义千问2.5,模型性能全面赶超GPT-4 Turbo,成为地表最强中文大模型。同时,通义千问最新开源的1100亿参数模型在多个基准测评收获最佳成绩,超越Meta的Llama-3-70B,成为开源领域最强大模型。 相比通义千问2.1版本,通义千问2.5的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%,中文能力更是持续领先业界。在权威
【006期】游戏的开始和结束界面,得分和生命值及其游戏逻辑。
核心代码 int score;int lives;boolean gameOver;void draw() {background(255);if (!gameOver) {/*游戏中的其他所有逻辑写在此处*/displayScoreAndLives(); // 显示得分和生命值} else {displayGameOverScreen(); // 显示游戏结束画面}}void dis

kaggle 泰坦尼克号2 得分0.7799
流程 导入所要使用的包引入kaggle的数据集csv文件查看数据集有无空值填充这些空值提取特征分离训练集和测试集调用模型 导入需要的包 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarni

kaggle 纽约预测出租车价格 得分 5.34072
流程 导入所要使用的包引入kaggle的数据集csv文件查看数据集有无空值填充这些空值提取特征分离训练集和测试集调用模型 数据资源获取 数据资源获取 导入需要的包 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns 引入kaggle的数据集csv文件
kaggle 房价预测 得分0.53492
流程 导入需要的包引入文件,查看内容数据处理调用模型准备训练输出结果 导入需要的包 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom skle
![[SPSS]因子分析和因子得分的SPSS实现——学生成绩因子构成和分科建议实例](https://img-blog.csdnimg.cn/2018121211272012.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RPTU9DQVQ=,size_16,color_FFFFFF,t_70)
[SPSS]因子分析和因子得分的SPSS实现——学生成绩因子构成和分科建议实例
学生成绩因子构成和分科建议 数据概况: 因子分析: 将除序号外的变量都移入变量框中: 打开“描述”选项卡,勾选原始分析结果,这个结果会给出各因子的特征值、各因子特征值占总方差的百分比以及累计百分比。 选中“抽取”选项卡,方法选择主成分法;因子分析输出选择未旋转的因子解,输出因子载荷矩阵;因子抽取原则是基于特征值大于1的因子。 点击“旋转”选项卡,选择“最大方差
编写苹果游戏中心应用程序(翻译 1.10 向排行榜提交得分)
1.10 向排行榜提交得分 问题 你已经在iTunes Connect中创建了至少一个排行榜,现在你想将玩家的成绩保存到排行榜。 解决方案 使用GKScore类的实例方法reportScoreWithCompletionHandler:。 讨论 如果已经创建了排行榜,则遵循以下的步骤,以向排行榜提交成绩: 1. 验证本地玩家(条款1.5)。
Codeforces Contest 1089 problem A Alice the Fan —— dp求已知两人最终得分推每次得分
Alice is a big fan of volleyball and especially of the very strong “Team A”. Volleyball match consists of up to five sets. During each set teams score one point for winning a ball. The first four set
【Python】【难度:简单】Leetcode 1422. 分割字符串的最大得分
给你一个由若干 0 和 1 组成的字符串 s ,请你计算并返回将该字符串分割成两个 非空 子字符串(即 左 子字符串和 右 子字符串)所能获得的最大得分。 「分割字符串的得分」为 左 子字符串中 0 的数量加上 右 子字符串中 1 的数量。 示例 1: 输入:s = "011101" 输出:5 解释: 将字符串 s 划分为两个非空子字符串的可行方案有: 左子字符串 = "0" 且 右
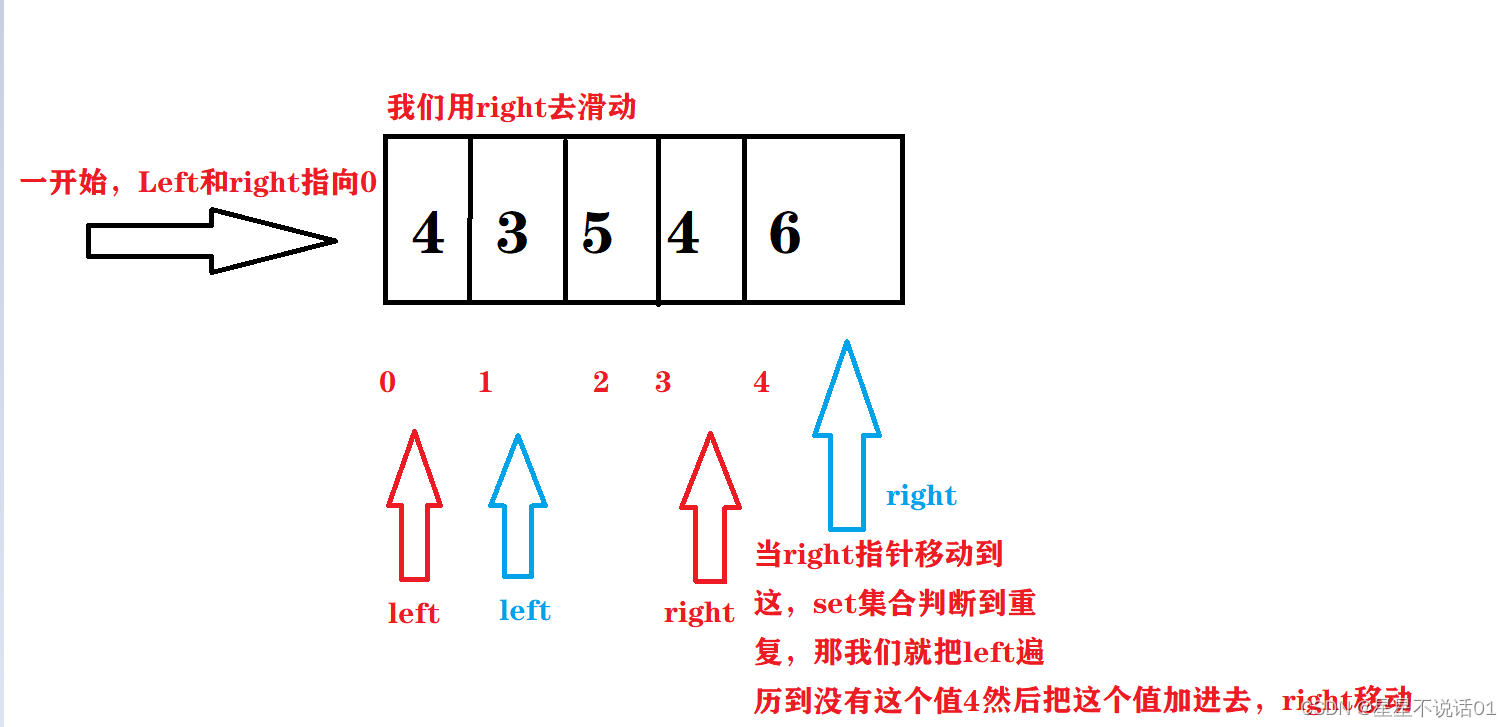
1695. 删除子数组的最大得分-力扣(滑动窗口)
给你一个正整数数组 nums ,请你从中删除一个含有 若干不同元素 的子数组。删除子数组的 得分 就是子数组各元素之 和 。 返回 只删除一个 子数组可获得的 最大得分 。 如果数组 b 是数组 a 的一个连续子序列,即如果它等于 a[l],a[l+1],…,a[r] ,那么它就是 a 的一个子数组。 示例 1: 输入:nums = [4,2,4,5,6] 输出:17 解释:最优子数组是 [2,
【牛客】SQL146 0级用户高难度试卷的平均用时和平均得分
描述 现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间),数据如下: iduidnick_nameachievementleveljobregister_time11001牛客1号100算法2020-01-01 10:00:0021002牛客2号21006算法202
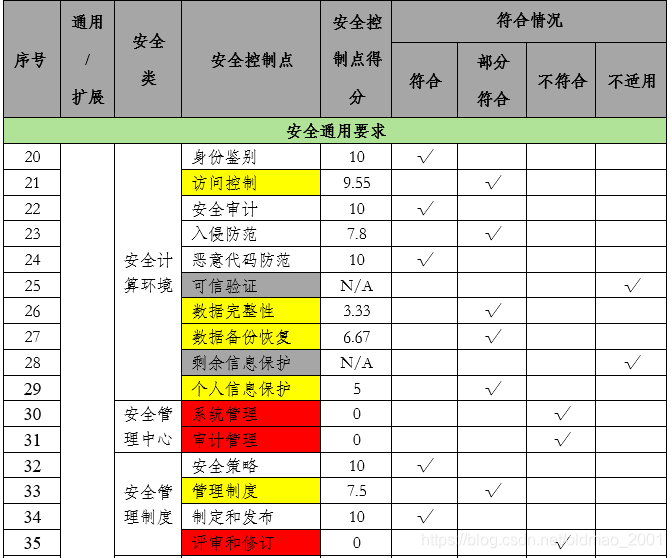
等保2.0.测评项控制点得分计算
文章目录 前言测评项控制点得分计算多个对象第一步第二步第三步第四步 单个对象第一步第二步第三步第四步 控制点符合情况汇总表 未经许可,请勿转载 前言 上篇写了测评综合得分计算,本来单项测评项控制点得分计算比较简单,不用写,但是涉及到整体的测评结果分析,就顺便写一下,算是一个完结。 测评项控制点得分计算 先给出新版测评报告中的描述与公式: 根据附录D中测评项的符合程度得分

直通车优化 提分 关键词 展现位置 相关性 买家体验 优化秘术:提升质量得分,打爆自然流量!
话不多说直奔主题。 一个店铺想要长久良好的生存下去,那么店铺必须要有足够的流量作来维持,但也并不意味着什么流量都是来者不拒的。 流量可以分为付费和免费这两流量。一个店铺光靠付费流量肯定是不行的,做推广引流的目的,就是去通过付费去获取免费流量,这才是我们的初衷。 如何通过付费去带动自然流量呢? 账户权重一定处于优质水平,是店铺付费带动自然流量的前提条件,而你的权重好坏,首先体现在质量分上,权重低,那
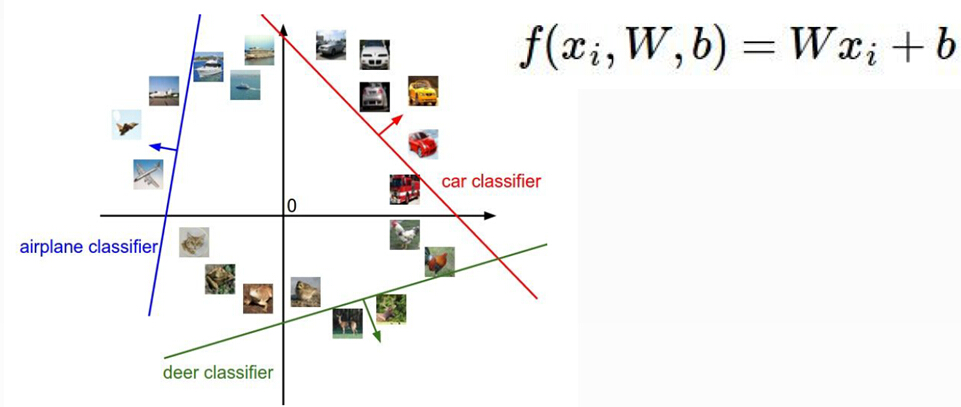
深度学习入门课程学习笔记02 得分函数
本篇学习笔记对应深度学习入门课程 第三课 得分函数 前向传播之-得分函数 剧透:深度学习必备的两个大知识点分别是前向传播和反向传播啦,这里节课我们会先着手把前方传播的所涉及的所有知识点搞定!我相信这部分对于咱们即便没有什么基础的同学来说也是很容易理解的。 得分函数:这个就是咱们这节课最核心的一个问题啦。什么叫得分函数呢?下面这个图就给了我们一个最直接的答案! 得分函数的目的:
【牛客】SQL136 每类试卷得分前3名-窗口函数
描述 现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间): idexam_idtagdifficultydurationrelease_time19001SQLhard602021-09-01 06:00:0029002SQLhard602021-09-01
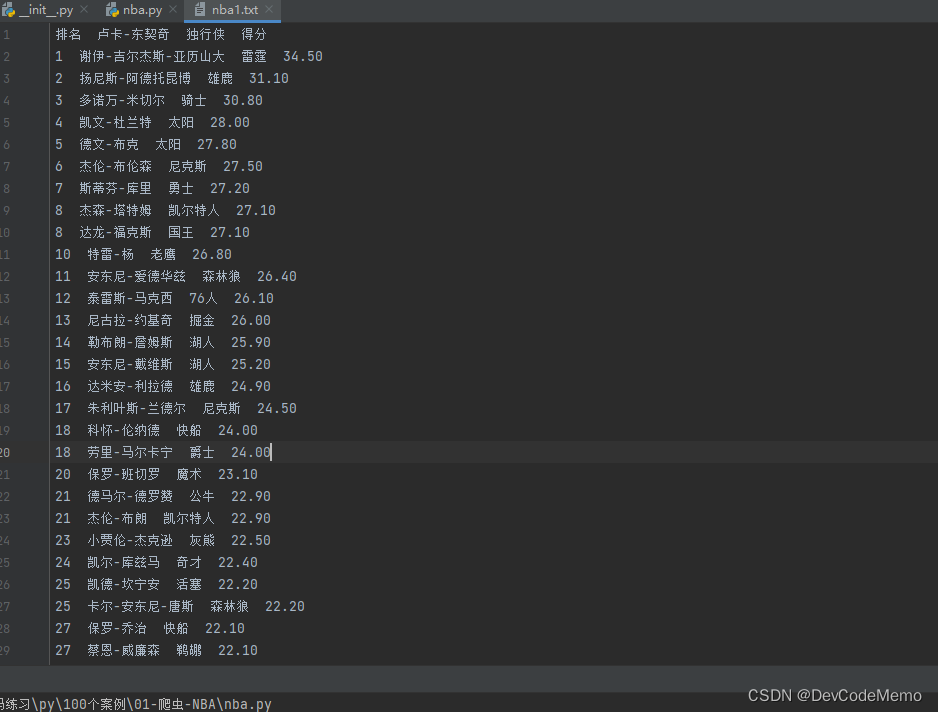
爬虫学习笔记-requests爬取NBA得分榜
1.导入requests库,用于请求获取URL位置的资源 import requests 2.导入lxml库,解析及生成xml和html文件 from lxml import etree 3.定义发送请求的地址 url = 'https://nba.hupu.com/stats/players' 4.定义请求头 headers = {'User-Agent':'Mozilla/5.0

启过网:一级建造师考试科目和各题型得分标准
一级建造师考试包括四个科目,分别是《建设工程经济》、《建设工程法规及相关知识》、《建设工程项目管理》和《专业工程管理与实务》。其中,《专业工程管理与实务》是专业科目,而其他三个科目是公共科目。 公共科目的试题题型包括单项选择题和多项选择题。对于单项选择题,考生需要从四个备选项中选出最符合题意的一个选项作为答案。而多项选择题要求考生在四个选项中选出两个到四个符合题意的选项。如果全部选对,则得到