本文主要是介绍爬虫学习笔记-requests爬取NBA得分榜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.导入requests库,用于请求获取URL位置的资源
import requests
2.导入lxml库,解析及生成xml和html文件
from lxml import etree
3.定义发送请求的地址
url = 'https://nba.hupu.com/stats/players'
4.定义请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
5.发送请求,获取html代码
resp = requests.get(url,headers=headers)
6.处理结果,解析字符串格式的HTML文档对象
e = etree.HTML(resp.text)
7.解析响应的数据,确定XML文档中某部分位置的语言
numbers = e.xpath('//tbody//tr//td[1]/text()')
names = e.xpath('//tbody//tr//td[2]/a/text()')
teams = e.xpath('//tbody//tr//td[3]/a/text()')
scores = e.xpath('//tbody//tr//td[4]/text()')
8. 保存到txt中
with open ('nba1.txt','w',encoding='utf-8') as f:for num,name,team,score in zip(numbers,names,teams,scores):f.write(f'{num} {name} {team} {score}\n') #f'变量'
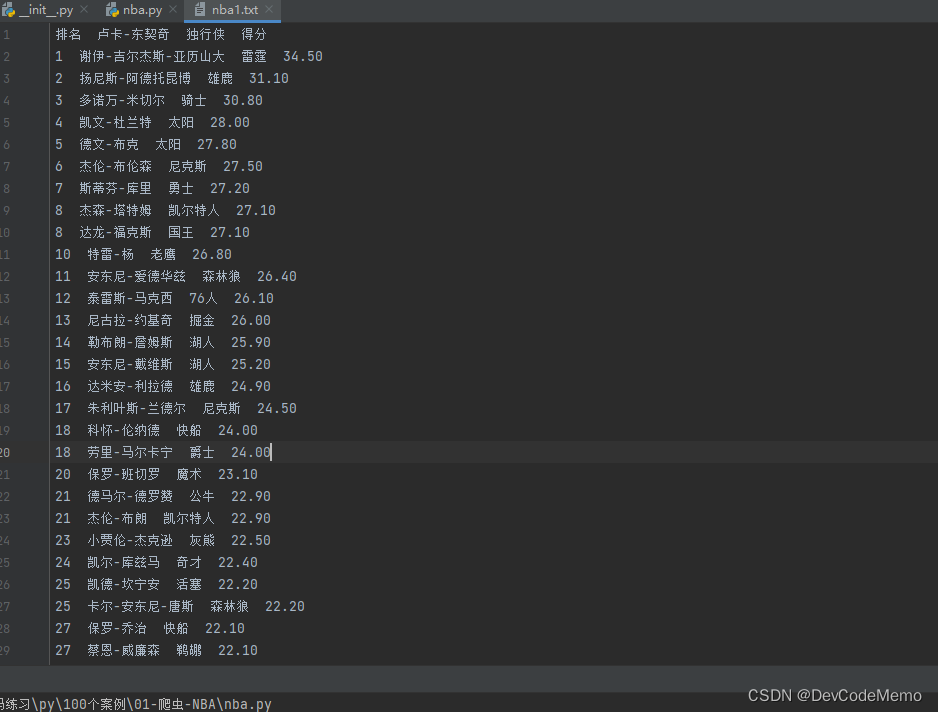
8.源码
#导入requests库,用于请求获取URL位置的资源
import requests
#导入lxml库,解析及生成xml和html文件
from lxml import etree
#发送的地址
url = 'https://nba.hupu.com/stats/players'
#伪装
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
#发送请求,获取html代码
resp = requests.get(url,headers=headers)
# print(resp.text)
#处理结果,解析字符串格式的HTML文档对象,
e = etree.HTML(resp.text)
#解析响应的数据,确定XML文档中某部分位置的语言
# numbers = e.xpath('//table[@class="players_table"]//tr//td[1]/text()')
numbers = e.xpath('//tbody//tr//td[1]/text()')
names = e.xpath('//tbody//tr//td[2]/a/text()')
teams = e.xpath('//tbody//tr//td[3]/a/text()')
scores = e.xpath('//tbody//tr//td[4]/text()')
#保存到txt中
with open ('nba1.txt','w',encoding='utf-8') as f:for num,name,team,score in zip(numbers,names,teams,scores):f.write(f'{num} {name} {team} {score}\n') #f'变量'这篇关于爬虫学习笔记-requests爬取NBA得分榜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







