掩膜专题

GIS之arcgis系列10:arcpy实现批量掩膜提取
按掩膜提取 (Spatial Analyst) 提取掩膜所定义区域内的相应栅格像元。 OutRas = ExtractByMask(InRas1, InMsk1, "INSIDE") 使用情况 输入栅格中的其他属性(若有的话)将按照原样添加到输出栅格属性表。 根据所记录的属性,某些属性值可能需要重新计算。 将多波段栅格指定为输入栅格(Python 中的 in_raster)值时
掩膜操作手写+API(第二天)
1.1首先是用到的理论知识: 上面是一个通用的公式,光知道上面写程序还是有点麻烦的,下面公式画的有点丑,可以表达我的观点。 1.2用到的知识点:可以边看程序边看用到的知识点: CV_Assert(); //这是C++的一个限制函数,这个不用多说了。 dst.create();//创建一个图像,形式根据参数选定 Mat.ptr<uchar>(i,j)//代表第i行,

【转载】利用ENVI直接建立掩膜去除背景Inf值或NaN值
有时候我们会遇到遥感影像的背景值为Inf(或其他坏值)的的情况,在ENVI中通过建立掩膜可以直接将背景值变为0(或者你需要的其他值)。如下图,其背景值是Inf值,那么下面,我们就通过掩膜操作将Inf变为0值。 步骤:建立掩膜——应用掩膜 具体操作如下: 为需要掩膜的文件建立掩膜文件:Basic Tools——Masking——Build Masking ,选择你需要为其建立掩膜的文件。

OpenCV学习5:掩膜mask操作
什么是掩膜(mask) 定义:用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。用于覆盖的特定图像或物体称为掩模或模板。光学图像处理中,掩模可以足胶片、滤光片等。 数字图像处理中,掩模为二维矩阵数组,有时也用多值图像。数字图像处理中,图像掩模主要用于: 提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持
独家|OpenCV 1.3 矩阵的掩膜操作(附链接)
翻译:陈之炎校对:王可汗、林夕本文约1600字,建议阅读5分钟本文为大家介绍了 OpenCV 矩阵的官方教程。 矩阵的掩膜操作(mask)并不难。主要思路为:根据掩膜矩阵(也称为内核kernel)重新计算图像中每个像素的值。利用掩膜矩阵调整相邻像素对当前像素值的影响。从数学的角度来看,即是利用特定的权重值,对像素做一个加权平均。 测试案例 来看一下如何增强图像对比度的示例,按照以下公式重新
opencv矩阵掩膜操作
#include<opencv2/opencv.hpp>#include<iostream>using namespace std;using namespace cv;int main(){Mat src, dst;src = imread("D:/image/1.jpg", 1);if (src.empty()){cout << "无法加载图像" << endl;return -1;}i

二维相位解包裹理论算法和软件【全文翻译-掩膜切割算法(4.4)】
4.4 掩膜切割算法 在上一节中,我们了解到质量引导路径跟踪算法可以解决一些相位解包问题,而在这些问题上,戈尔茨坦算法会因为分支切割的错位而失败。这是因为质量引导方法采用了更多的信息(质量图)来引导解包路径。在本节中,我们将这一想法与戈尔茨坦算法相结合,产生了一种 "混合 "算法,它使用质量图来引导分支切割的位置。由此产生的算法结合了两种算法的优点:除了残基数据外,还利用了额外的信息来指导解包过
Leaflet使用多面(MultiPolygon)进行遥感影像掩膜报错解决之道
目录 前言 一、问题初诊断 1、山重水复 2、柳暗花明 3、庖丁解牛 4、问题定位 二、解决多面掩膜问题 1、尝试数据修复 2、实际修复 3、最终效果 三、总结 前言 之前一篇讲解遥感影像掩膜实现:基于SpringBoot和Leaflet的行政区划地图掩膜效果实战,在这边博客中,详细说明了在Leaflet中进行行政区划地图掩膜效果的实现。

基于图像掩膜和深度学习的花生豆分拣(附源码)
目录 项目介绍 图像分类网络构建 处理花生豆图片完成预测 项目介绍 这是一个使用图像掩膜技术和深度学习技术实现的一个花生豆分拣系统 我们有大量的花生豆图片,并以及打好了标签,可以看一下目录结构和几张具体的图片 同时我们也有几张大的图片,里面有若干花生豆,我们要做的任务就是将花生豆框住并且实现分类,可以看一下这些图片 图像分类网络构建 这部分的内容和
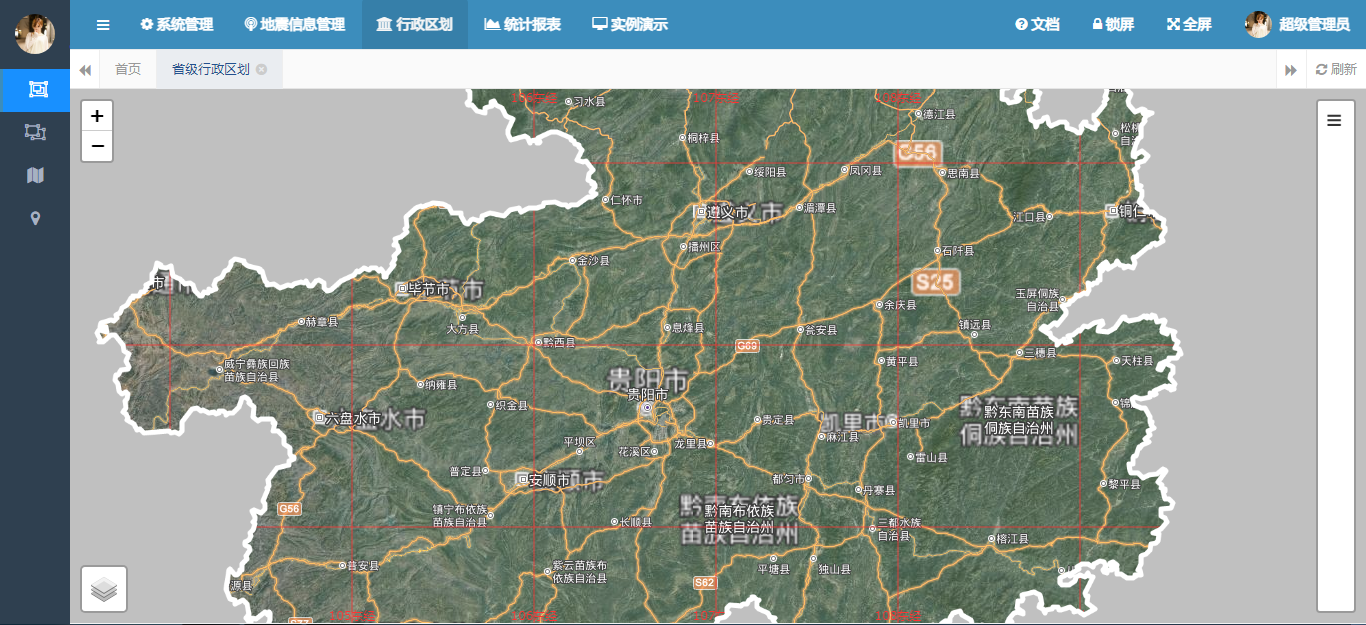
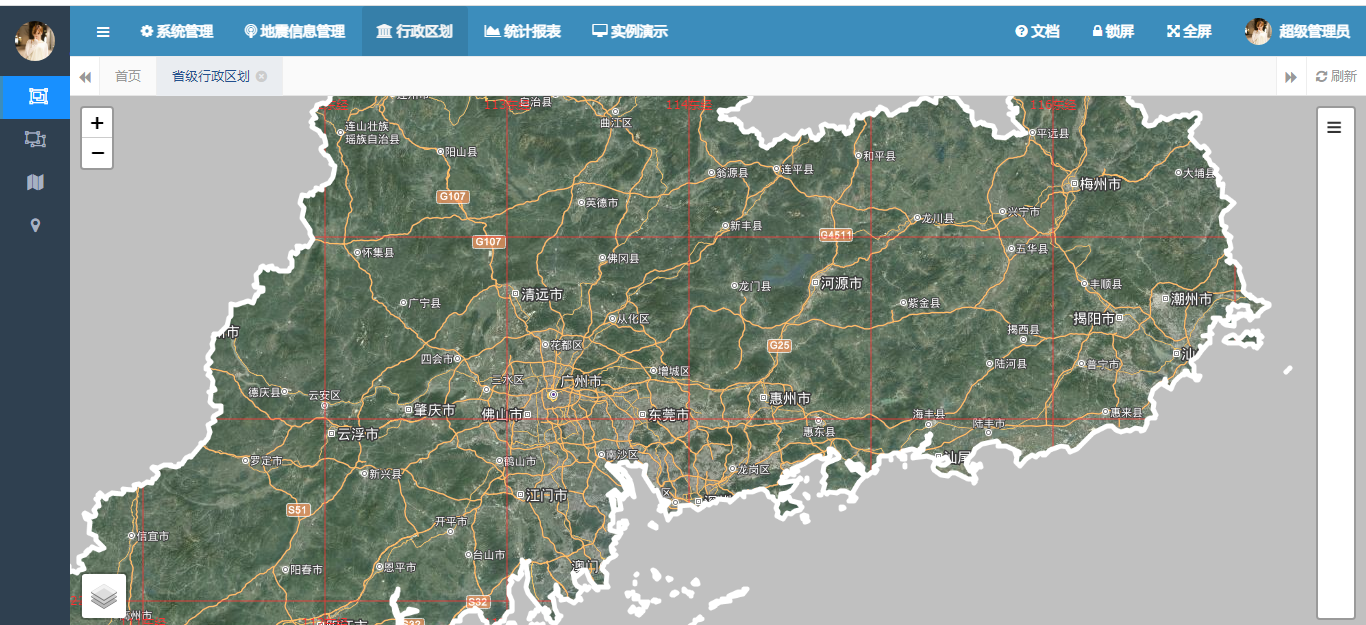
基于SpringBoot和Leaflet的行政区划地图掩膜效果实战
目录 前言 一、掩膜小知识 1、GIS掩膜的实现原理 2、图层掩膜流程 二、使用插件 1、leaflet-mask介绍 2、核心代码解释 三、完整实例实现 1、后台逻辑实现 2、省级行政区划查询实现 3、行政区划定位及掩膜实现 4、成果展示 总结 前言 在之前的博客提过按空间矢量范围下载遥感,有兴趣的同学可以参考已下的博文地址:基于Q

深度学习掩膜_深度学习在AEC中的应用探索
本文来自大象声科高级算法工程师闫永杰在LiveVideoStackCon2019北京大会上的分享。 闫永杰介绍了深度学习在回声消除(AEC)中的应用。 正如我们所知,AEC是 在线音视频通话(VoIP)领域中一个非常棘手的问题,目前应用比较广泛的AEC方法主要还是基于传统信号处理的方法。 大象声科在成功将深度学习应用于人声和噪声分离的基础上,正在通过引入深度学习技术,解决回声消除问题。

GEE学习——如何在计算蒸散发量的过程中剔除水体面积带来的影响?(掩膜去除水体)
简介 如何在计算蒸散发量的过程中剔除水体面积带来的影响?(掩膜去除水体) 就像上面这句话,我们很多时候计算的是陆地上的蒸散发,而又担心如何去除水体蒸散发带来的影响,所以我们这里首要的方式就是通过掩膜的方式来进行,也就是将土地分类中水体的面积从整个研究区中去除调,然后将剩余的影像参与后续蒸散发计算。整个思路是非常简答的,所以我们这里只需要先加载相应的土地分类影像,选择对应的水体波段作为掩膜对象,
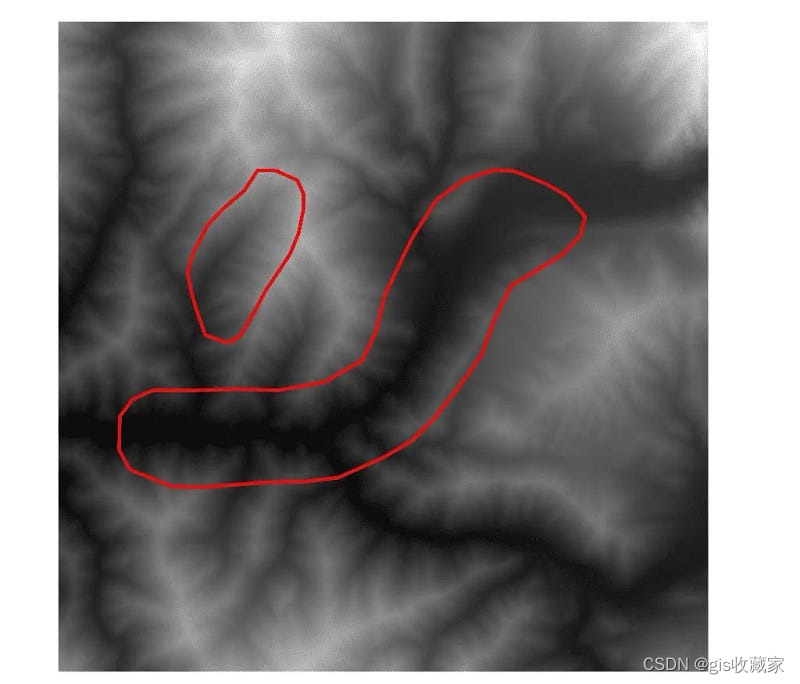
Python 通过掩膜剪切栅格多边形
剪切、提取到掩码和栅格子集是常见的 GIS 操作。使用 Python 的 gdal 软件包可以非常容易地实现这些过程的自动化。本教程将演示如何使用 gdal Python API 中的 Warp() 函数将栅格剪切到指定范围并将栅格剪切到多边形图层。这些操作通常也被称为掩码提取或提取到掩码。 安装 GDAL 您需要gdal在 Python 环境中安装才能完成本教程。不幸的是,gdal这并不
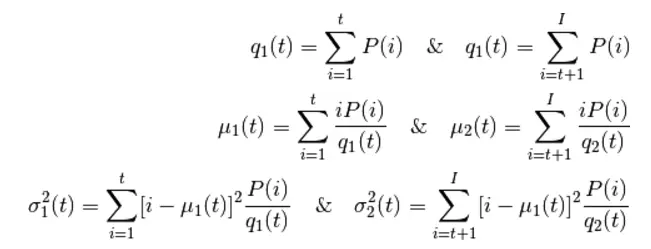
图像处理 mask掩膜
1,图像算术运算 图像的算术运算有很多种,比如两幅图像可以相加,相减,相乘,相除,位运算,平方根,对数,绝对值等;图像也可以放大,缩小,旋转,还可以截取其中的一部分作为ROI(感兴趣区域)进行操作,各个颜色通道还可以分别提取对各个颜色通道进行各种运算操作。总之,对图像可以进行的算术运算非常的多。这里先学习图片间的数学运算,图像混合,按位运算。 1.1 图片加法 要叠加两张图片,可以用

OpenCV 2 - 矩阵的掩膜操作
1知识点 1-1 CV_Assert(myImage.depth() == CV_8U); 确保输入图像是无符号字符类型,若该函数括号内的表达式为false,则会抛出一个错误。 1-2 Mat.ptr(int i = 0); 获取像素矩阵的指针,索引 i 表示第几行,从0开始计行数。 1-3 const uchar* current = mylmage.ptr(row);

AE+C#按掩膜提取
点击“空间分析”菜单标题按钮,其中包括: 点击按掩膜提取,会在主界面的MapControl控件里实现该功能。 click事件 private void 按掩膜提取ToolStripMenuItem_Click(object sender, EventArgs e){//设置栅格图层pRasterLayer = GetLayerByName(mainMapControl.Ma
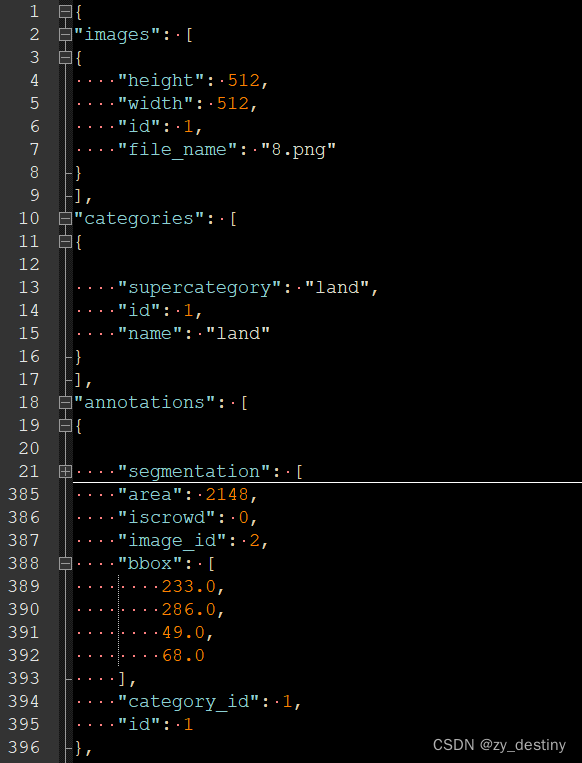
【coco】掩膜mask影像转coco格式txt(含python代码)
最近在做实例分割,遇到二值掩膜影像——coco格式txt的实例分割转换问题,困扰很久,不知道怎么转换,转出来的txt没法用代码成功读取。一系列问题,索性记录下自己的结局路程,方便大家python代码自取。 目录 📞📞1.coco格式示例 📗 images模块 📘 categories模块 📙annotation模块 📷📷2.环境准备 📢

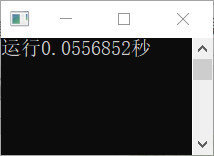
【opencv4.3.0教程】08之图像掩膜(Mask)操作与执行时间
目录 一、前言 二、温故知新——像素基本操作 1、获取像素指针 2、像素范围处理 3、读写像素 三、图像掩膜操作 1、怎么理解掩膜Mask 2、掩膜实现 3、API-filter2D 四、执行时间 一、前言 图像操作其实就是对像素进行操作,这些操作不仅仅是像前面那些基础操作一样简单,只有获取值啊,简单赋值啊之类的。但是像素操作可不止有这么简单。 从今天这节内容开始,我
论文阅读: Masked Autoencoders Are Scalable Vision Learners掩膜自编码器是可扩展的视觉学习器
Masked Autoencoders Are Scalable Vision Learners 掩膜自编码器是可扩展的视觉学习器 作者:FaceBook大神何恺明 一作 摘要: This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision.

vec3b、vec3f和CV_8UC3、CV_32FC3的含义和掩膜抠图经验
作者:RayChiu_Labloy 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 目录 vec3b、vec3f等的含义: CV_8UC3、CV_32FC3等的含义: 掩膜抠图过程中的坑: vec3b、vec3f等的含义: 格式:CV_<bit_depth>(S|U|F)C<number_of_channels> 解释: 1--bit_dep

掩膜行列和空间分辨率不一致的数据
欢迎关注我的个人公众号:小Rser 掩膜行列和空间分辨率不一致的数据https://mp.weixin.qq.com/s?__biz=MzkyNjMzNTQ2Mw==&mid=2247483929&idx=1&sn=c16db2a848b6013e3526fbfc79e517b8&chksm=c239aa91f54e2387c15f5dc48f7ef368e6a745112a98f22a0302
【ArcGIS】批量对栅格图像按要素掩膜提取
要把一张大的栅格图裁成分省或者分县市的栅格集,一般是用ArcGIS里的按掩膜提取。 但是有的时候所要求的栅格集量非常大,所以用代码来做批量掩膜(按字段)会非常方便。 import arcpy , shutil , osfrom arcpy import envfrom arcpy.sa import *#使用说明print "开始使用前,请认真阅读使用说明"print "\n"pri
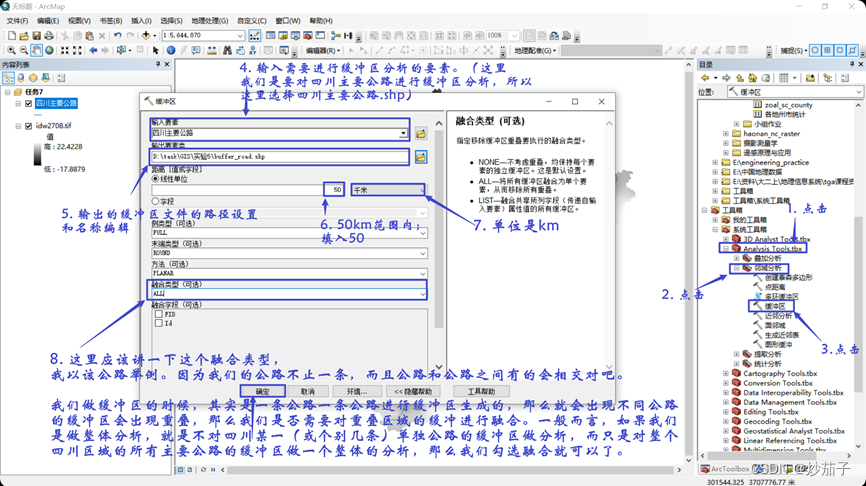
ArcGIS:如何进行离散点数据插值分析(IDW)、栅格数据的重分类、栅格计算器的简单使用、缓冲区分析、掩膜?
目录 01 说明 02 实验目的及要求 03 实验设备及软件平台 04 实验内容与步骤 4.1 反距离权重插值分析 4.2 多栅格局域运算 4.3 按表格显示分区统计 4.4 重分类 4.5 邻域运算 4.6 矢量数据的裁剪 4.7 缓冲区分析及栅格数据提取分析 05 思考及讨论 01 说明 由于这次的作业是从word上粘贴过来,所以有一些格式修改不了,也没有时间和精力修改,所以没有详细目

【opencv】python在图片中画mask掩膜
模仿maskrcnn,在图片中画一个多边形掩膜,提供可视化效果 code '''author:chenjundate:2020-01-16use:draw the mask on image'''import cv2import numpy as npfrom PIL import Imageimport matplotlib.pyplot as pltimport pyco

基于C#的AE二次开发之影像数据的裁切(掩膜)
基于C#的AE二次开发之影像数据的裁切(掩膜) 我的开发环境为ArcGIS Engine 10.2与Visual studio2010,主地图名称为axMapControl1,如果变动则需要修改(注意相关事件的添加与动态链接库的引入)。 效果预览 裁剪前 裁剪后 实现代码 引用类库 using ESRI.ArcGIS.esriSystem;using ESRI.Ar

【Python语义分割】Segment Anything(SAM)模型交互式分割+掩膜保存(三)
我之前分享了Segment Anything(SAM)模型的基本操作,这篇给大家分享下交互式语义分割代码,可以通过鼠标点击目标物生成对应的掩膜,同时我还加入了掩膜保存的代码。 1 Segment Anything介绍 1.1 概况 Meta AI 公司的 Segment Anything 模型是一项革命性的技术,该模型能够根据文本指令或图像识别,实现对任意物体的识别和分割。这