本文主要是介绍ArcGIS:如何进行离散点数据插值分析(IDW)、栅格数据的重分类、栅格计算器的简单使用、缓冲区分析、掩膜?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
01 说明
02 实验目的及要求
03 实验设备及软件平台
04 实验内容与步骤
4.1 反距离权重插值分析
4.2 多栅格局域运算
4.3 按表格显示分区统计
4.4 重分类
4.5 邻域运算
4.6 矢量数据的裁剪
4.7 缓冲区分析及栅格数据提取分析
05 思考及讨论
01 说明
由于这次的作业是从word上粘贴过来,所以有一些格式修改不了,也没有时间和精力修改,所以没有详细目录等等,浏览的时候应该非常难受.
| 实验名称 | 矢量及栅格数据分析 |
| 实验时间 | 2022.11.20 |
| 实验地点 | 资环楼229 |
《地理信息系统原理》实验报告
02 实验目的及要求
1)巩固学生掌握矢量数据插值分析、栅格数据重分类、叠加分
析的基本原理;
2)熟悉 ArcGis 中离散点数据插值分析的基本方法;
3)熟悉 ArcGis 中栅格数据重分类、栅格计算器的基本操作;
4)熟悉 ArcGis 中栅格数据分区统计的基本方法;
5)了解 ArcGis 中缓冲区分析、按掩膜提取的基本方法。
03 实验设备及软件平台
实验设备:笔记本电脑windows11系统
软件平台:ArcGIS
04 实验内容与步骤
4.1 反距离权重插值分析
打开 ArcMap 中,将数据框更名为“任务 1”
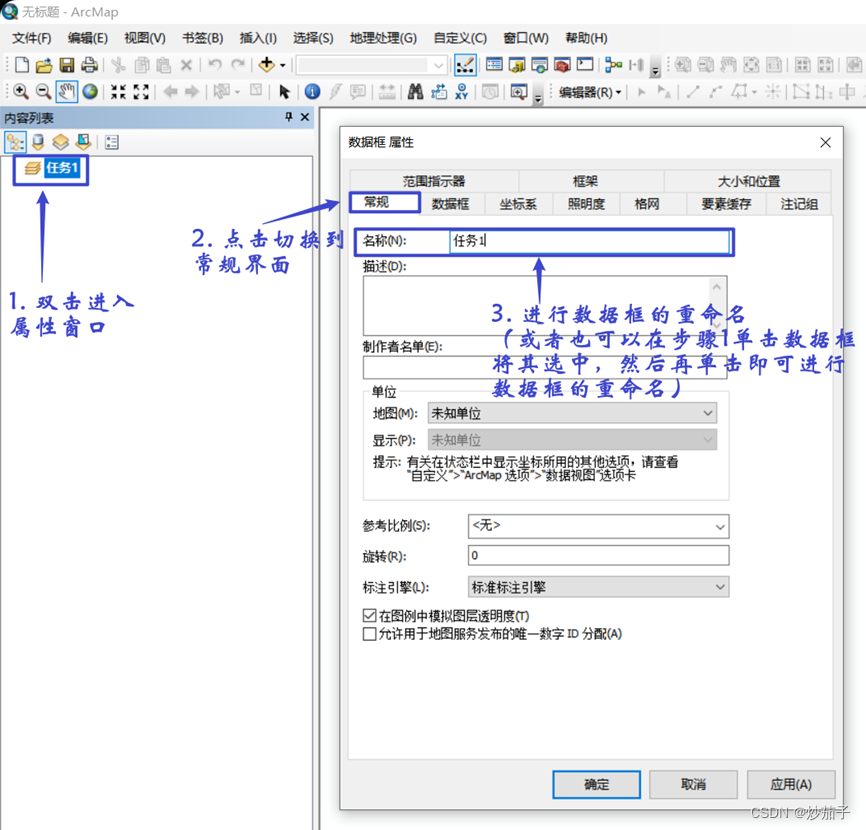
加入四川省边界图层。(眼里一片海,可惜没有蓝。)
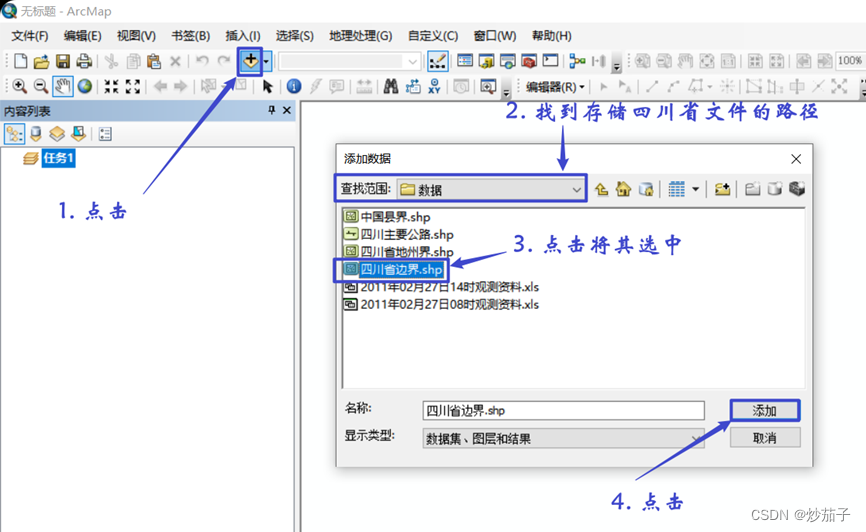
加载四川省边界文件之后的结果展示:
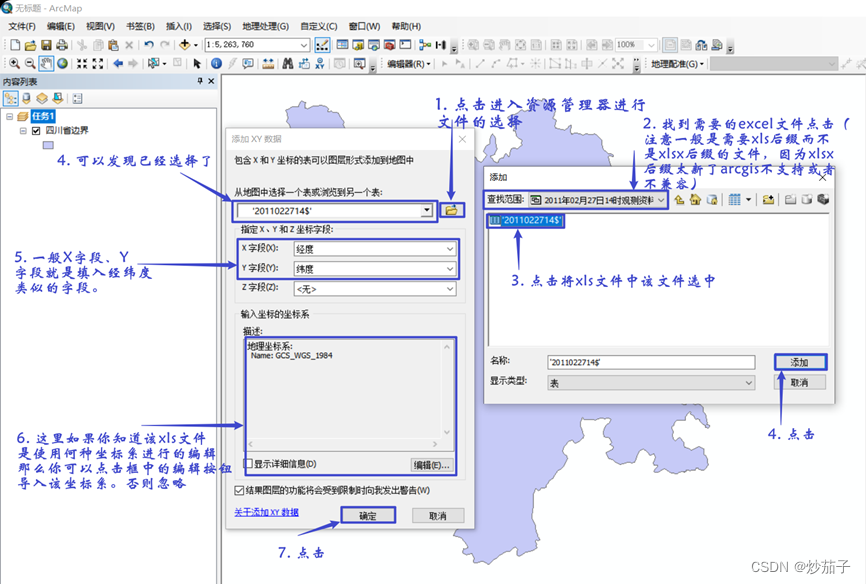
将 2011 年 02 月 27 日 08 时观测资料.xls、2011 年 02 月 27 日 14 时.xls 通过 Add Xy Data 功能,生成点图层。

类似的,另一个xls文件亦是如此进行添加,这里直接展示添加之后的结果:

将加载的XY数据导出,分别命名为 Obs2708.shp 和 Obs2714.shp
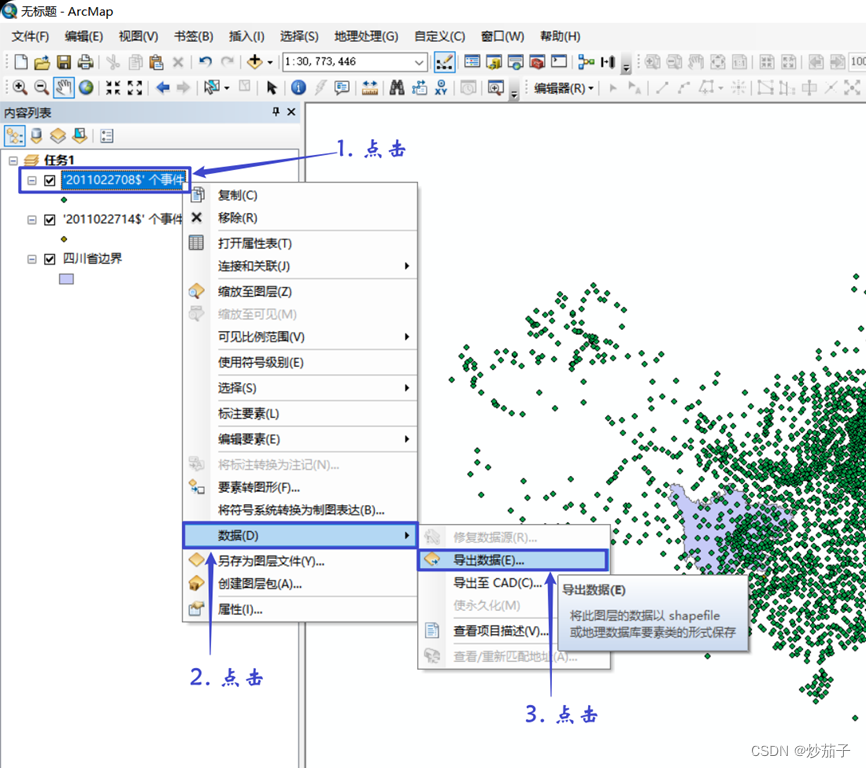
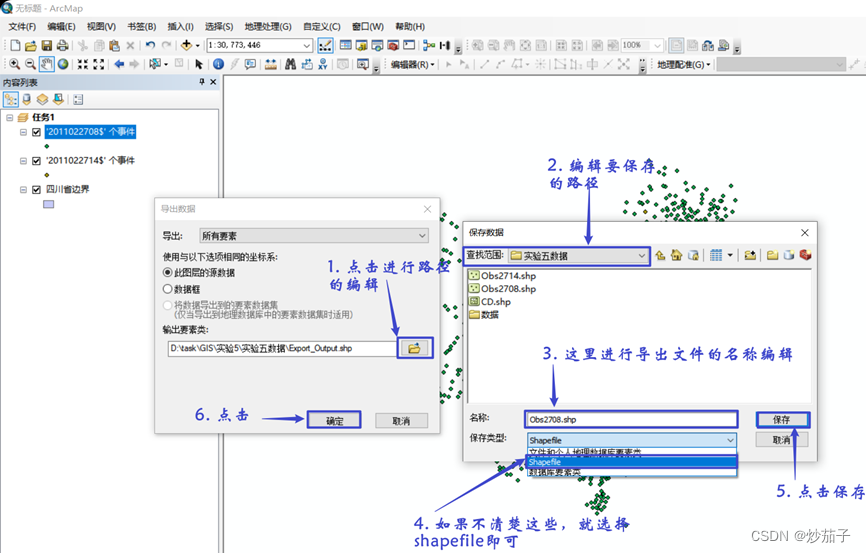
另一个事件文件亦是如此进行操作,这里直接展示导出之后的结果:

对 Obs2708.shp 中的属性“温度”在 四 川 范 围 内 进 行 插 值 分 析 。 可 以 通 过 “Arctoolbox->Spatial Analyst(空间分析)工 具中的 Interpolate to Raster(插值)工具选择。 (本实验采用反距离权重法 IDW),点插值成 栅格表面。
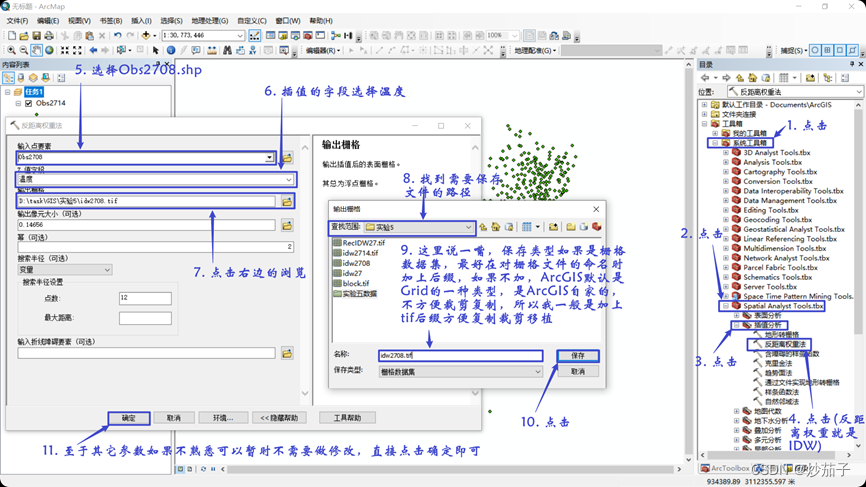
IDW插值之后的结果展示:
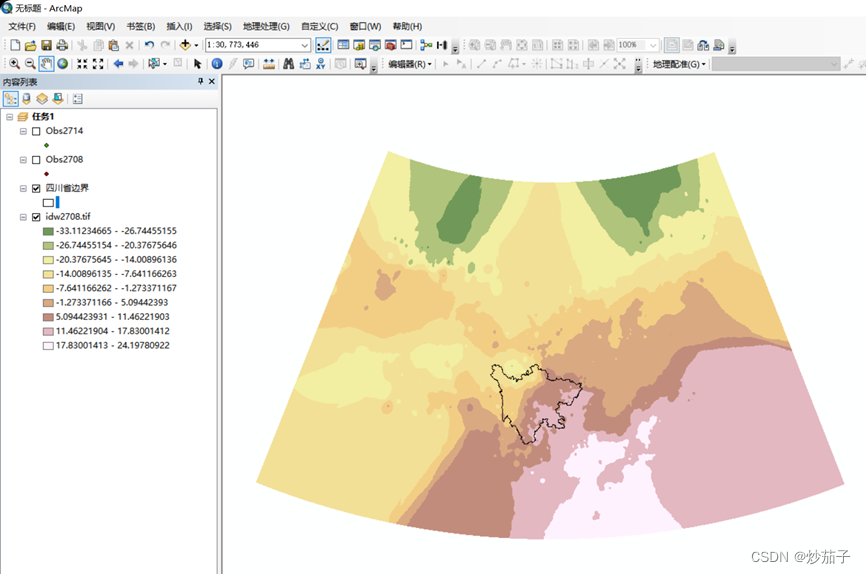
但是上面这种情况似乎不是大家想要的,这里我们是想要四川区域的插值结果(当然你可以在此基础上做一个掩膜之类的)。其实在上面的插值工具的窗口中可以进一步进行参数的设置,步骤如下:
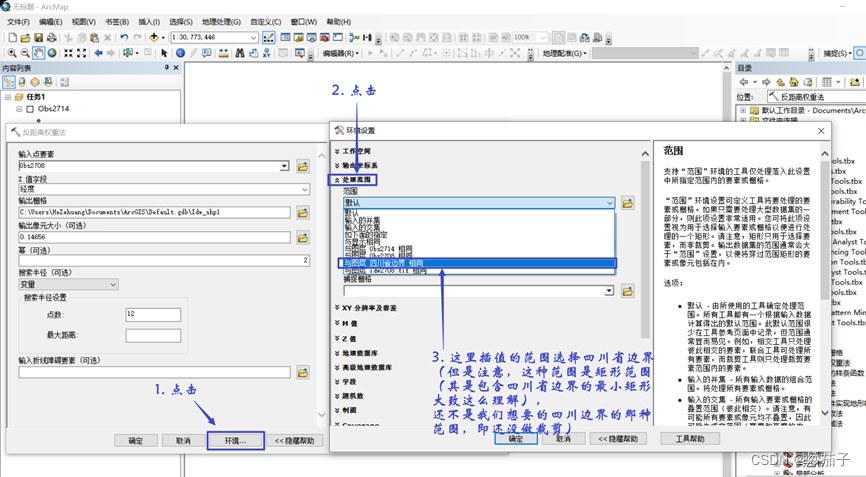
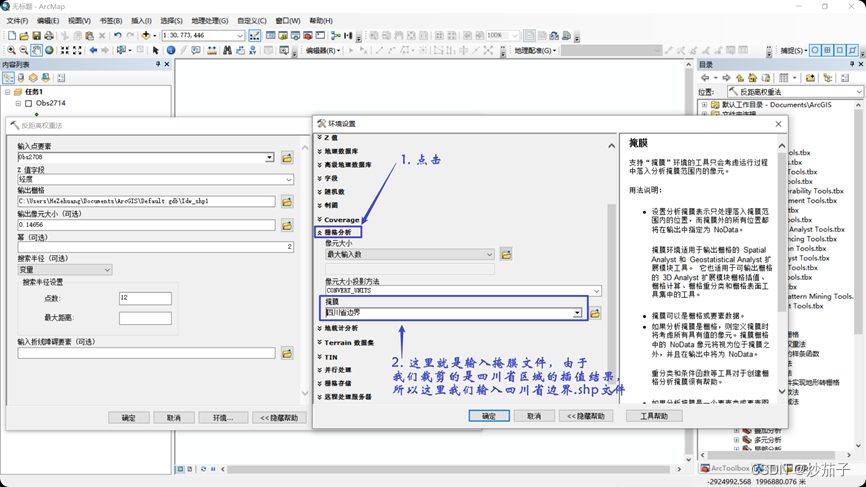
做了环境变量设置之后的结果展示:
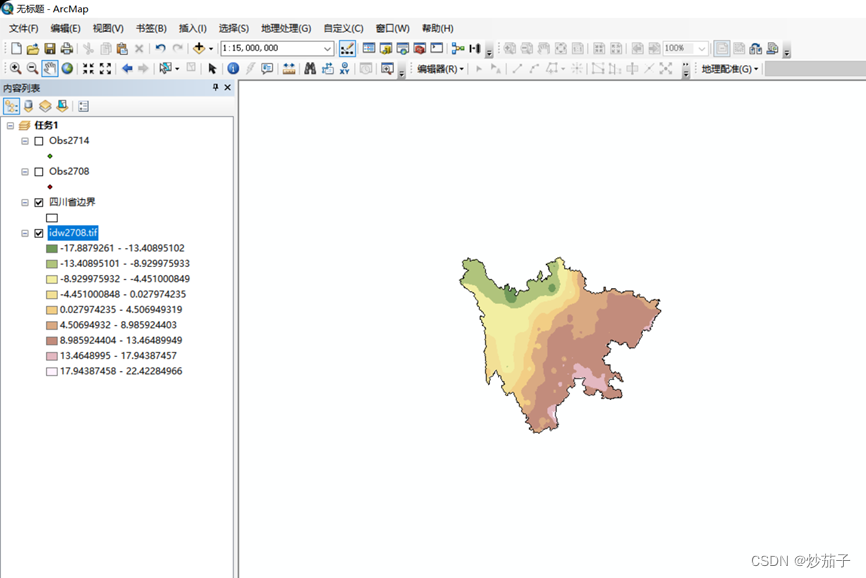
4)通过属性中的符号系统,修改显示样式。
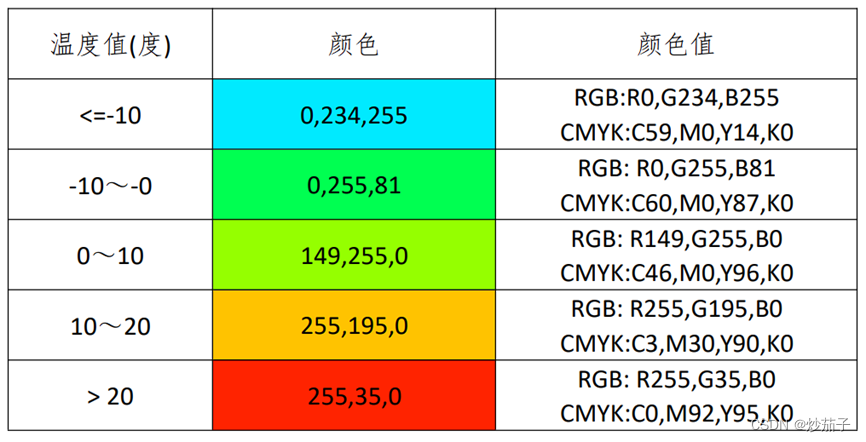
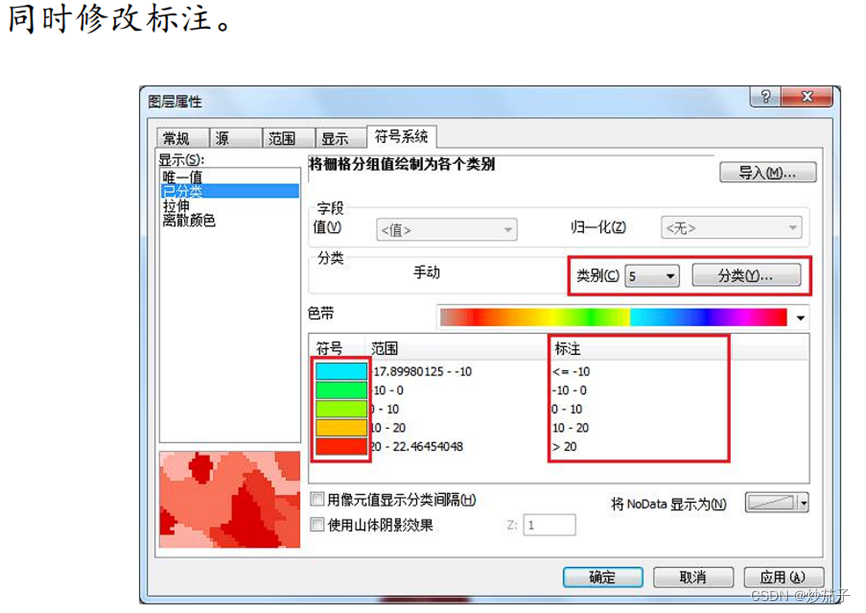
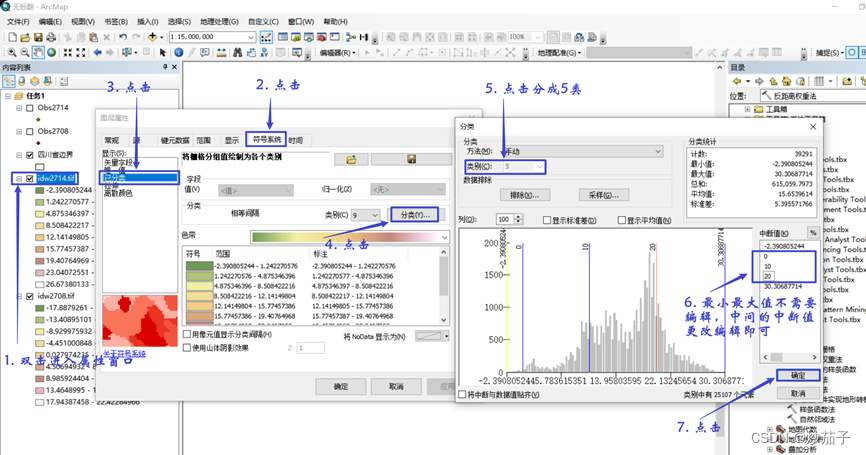
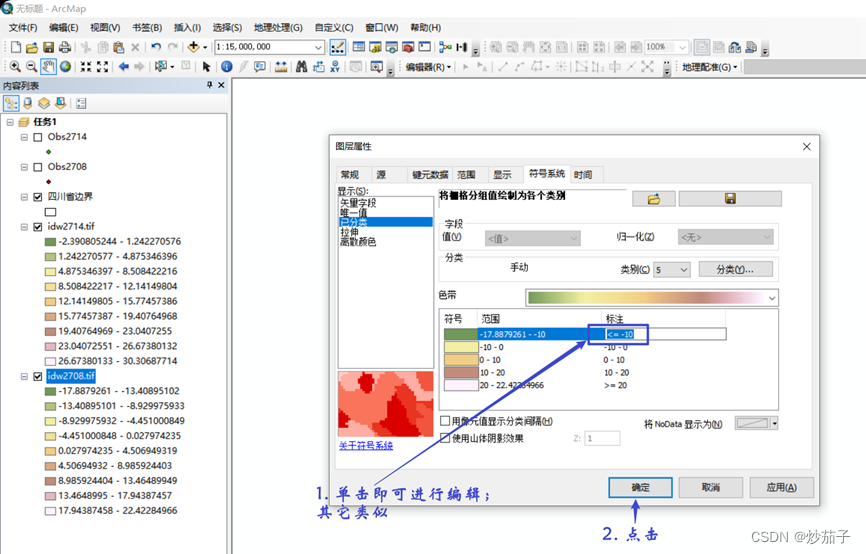
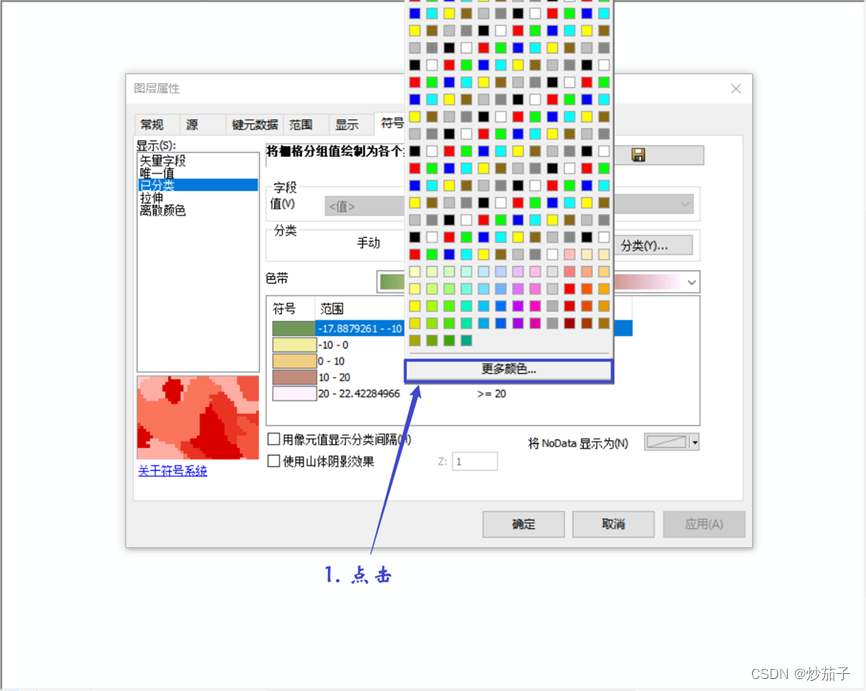
更改颜色的RGB值

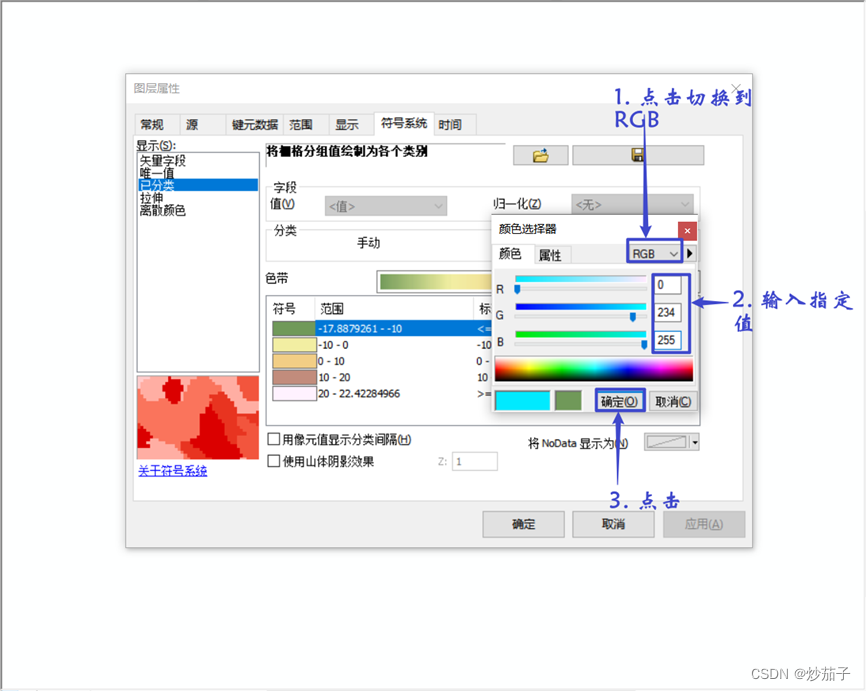
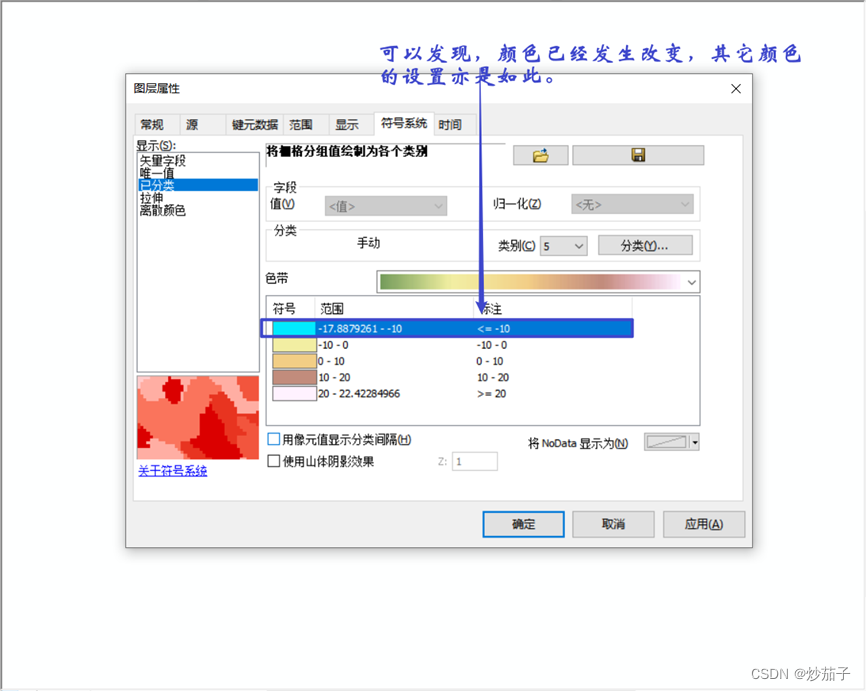
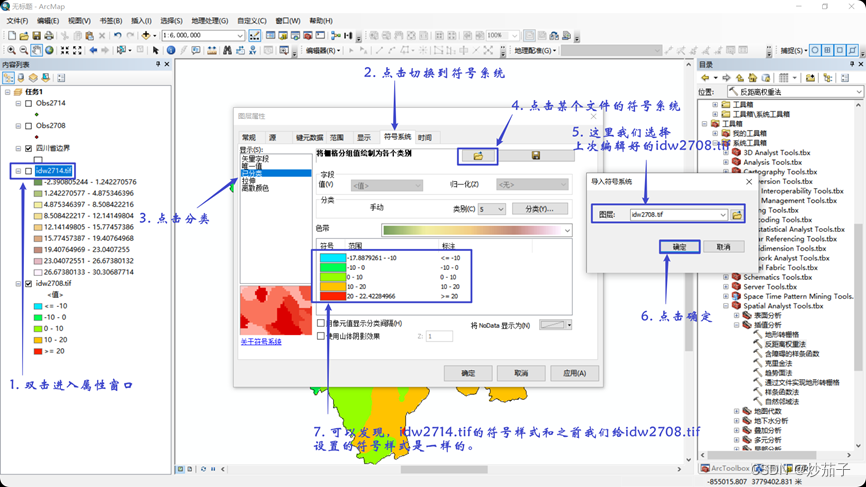
对 Obs2714.shp 同上 方 法 进 行 插 值 , 保 存 为 IDW2714 ( 符 号 系 统 可 从 IDW2708 中导入
4.2 多栅格局域运算
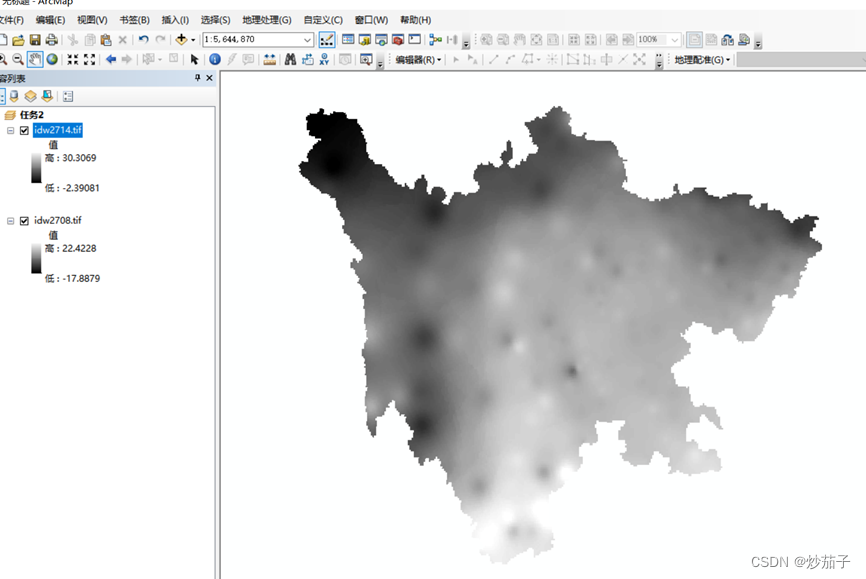
启动 ArcMap,添加数据框, 并更名为“任务 2”,将温度栅格数 据 IDW2708、IDW2714 加入
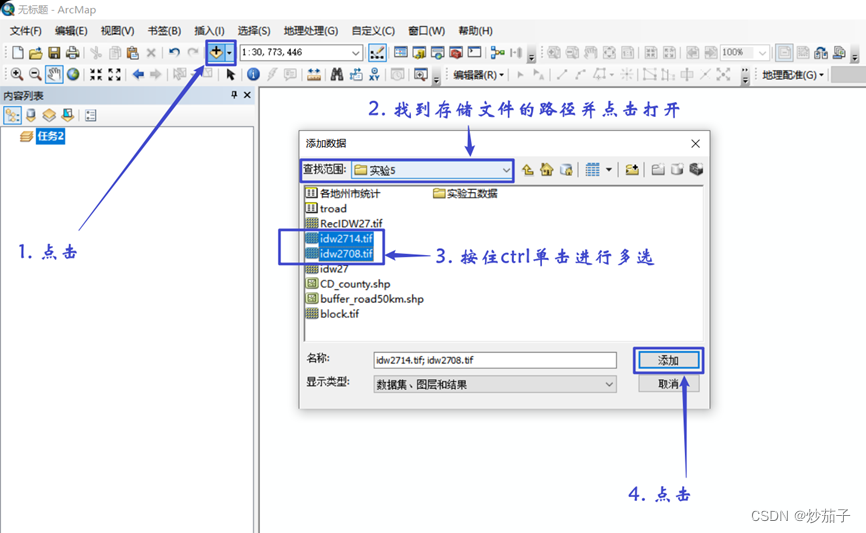
加载之后的结果展示:
取idw2708和idw2714对应每一个像元的平均值并输出为新的栅格文件
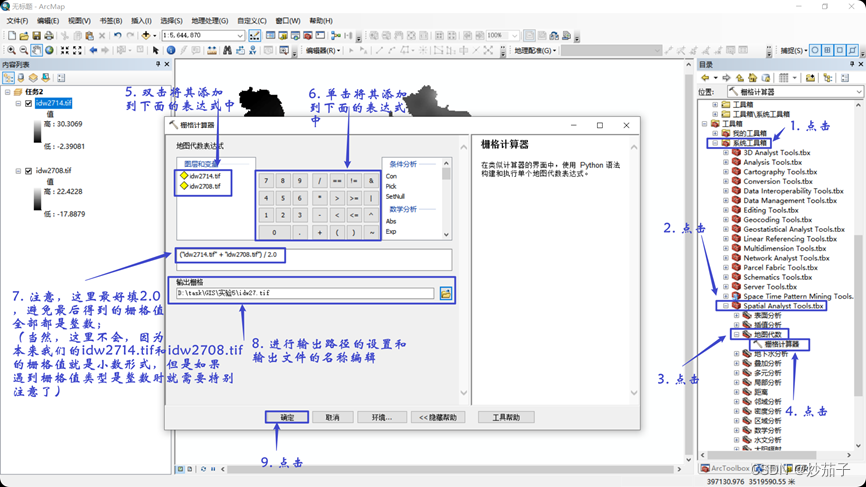
平均值计算的结果展示:

4.3 按表格显示分区统计
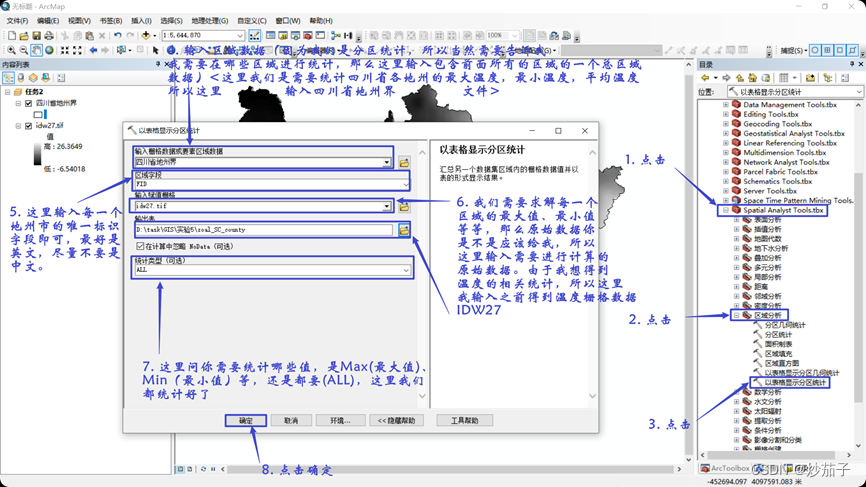
在 ArcMap 中插入数据帧,并命名为“任务 3”,并把上一个 任务的输出结果 IDW27 和四川省地州界图层添加到任务 3 中
添加操作就不再详细说明(参考前面的操作),这里直接展示添加之后的结果

2)从 ArcToolbox 中“Spatial Analyst 工具”的“区域分析”选择 “以表格显示分区统计 Zonal Statistics”。分区区域输入为四川地州界, 区域字段(转栅格属性值)为 Name(四川地州界图层中的属性),赋 值格栅为 IDW27
分区统计的结果展示:

4.4 重分类
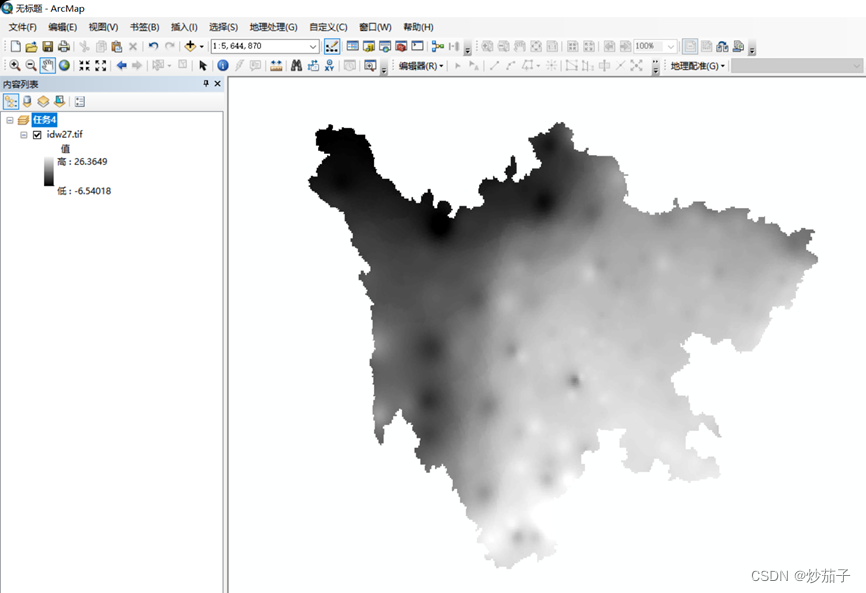
- 在 ArcMap 中插入数据帧,并命名为“任务 4”,并把上一个 任务的输出结果 IDW27 添加到任务4
这里直接展示添加之后的结果:
- 从“Spatial Analyst 工具”的“重分类 (Reclassify)”功 能进行重分类,重分类生成的栅格命名为 RecIDW27(重分类规则如下)
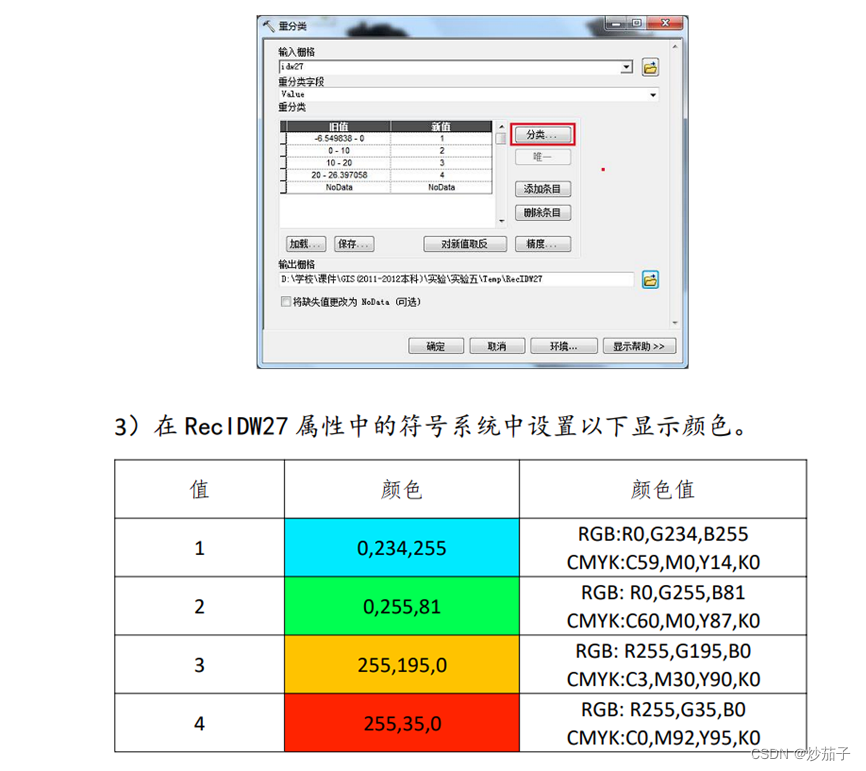
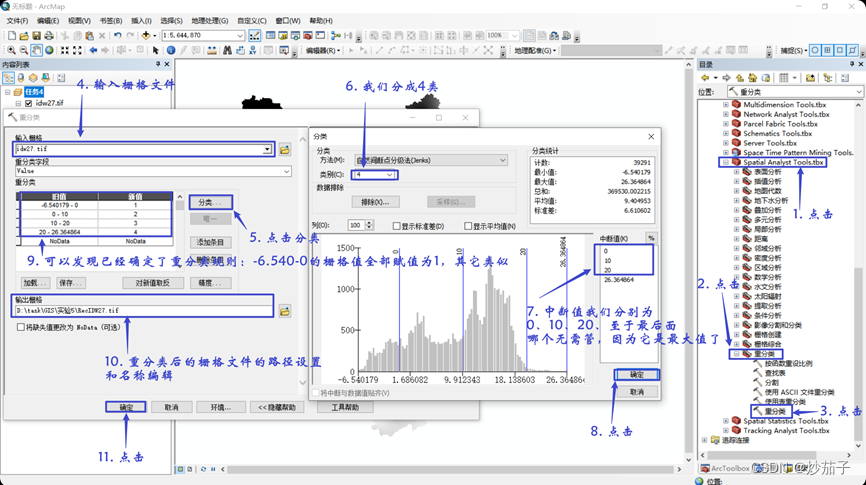
重分类之后的结果展示:

4.5 邻域运算
- 在 ArcMap 中插入数据帧,并命名为“任务 5”,并把上一个 任务的输出结果 IDW27 添加到任务
直接展示添加的结果:
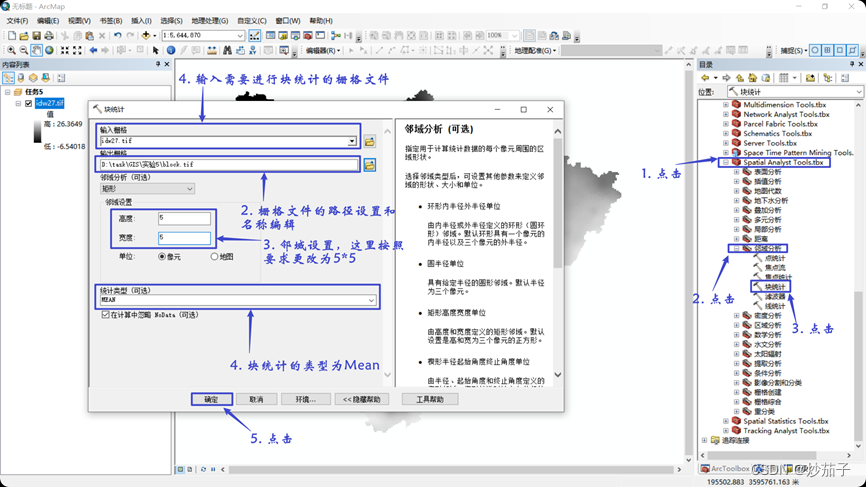
- 从“Spatial Analyst 工具”选择“邻域分析 Neighborhood analysis” 中的“块统计 Block Statistics”,设置统计值为 Mean(平均值)、邻域 是设置为 5*5 的正方形
4.6 矢量数据的裁剪
(将四川省成都市内及成都市内的区县提取出来)
- 在 ArcMap 中插入数据帧,并命名为“任务 6”,并把中国县界图层和四川地州界图层加入。

- 在四川地州界图层中,选择成都市,并将选择的数据导出,
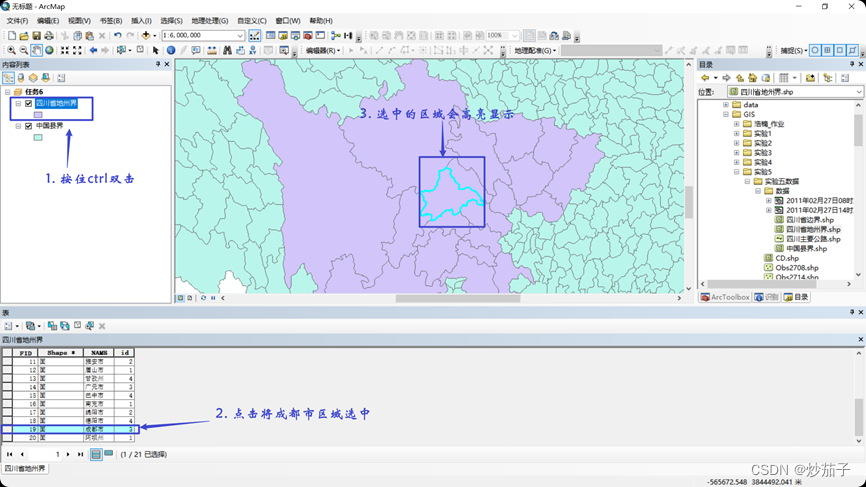
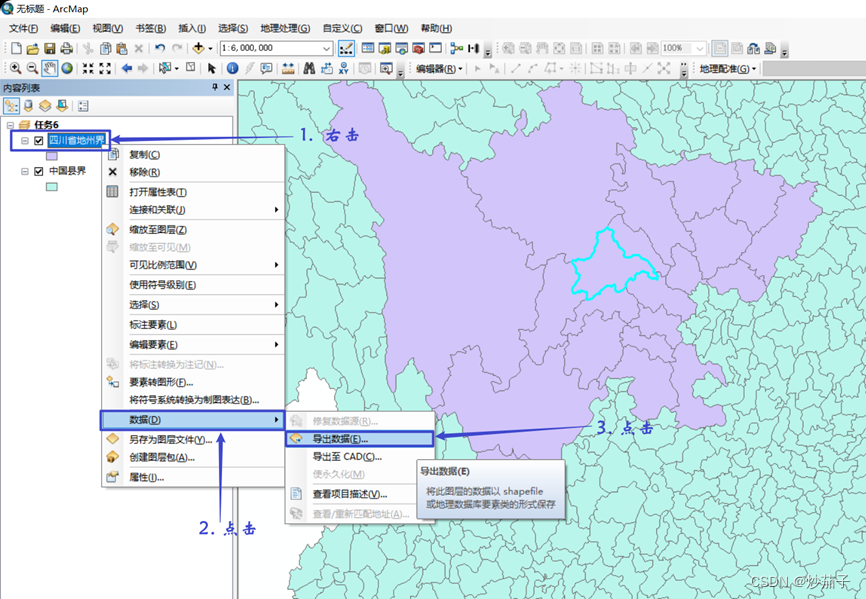
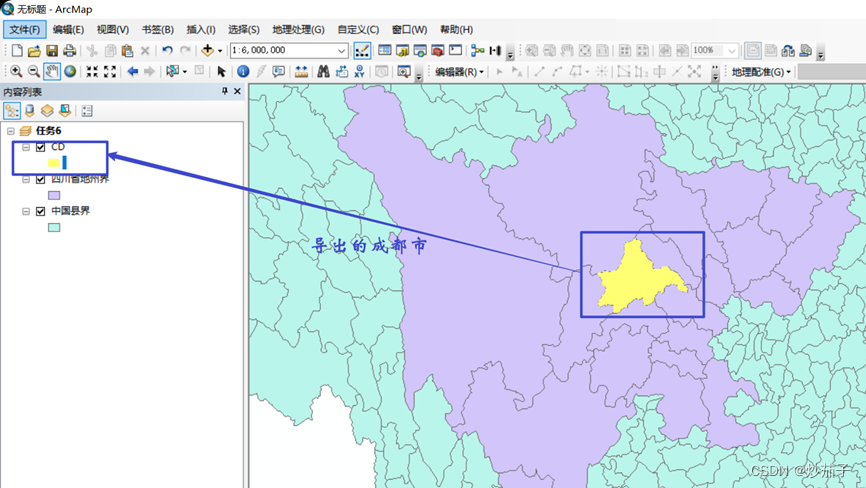
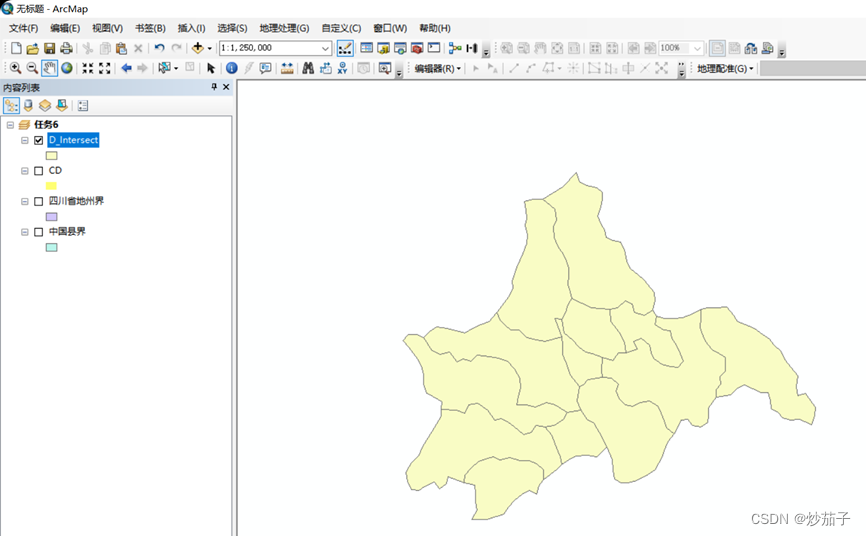
- 使用 ArcToolbox 中“分析 工具 Analyst Tool”的裁剪功能(或 “分析工具 Analyst Tool”的叠加 分析中的相交功能)将中国县界 中成都市内的县界裁剪出来。(这里用裁剪也是可以的)
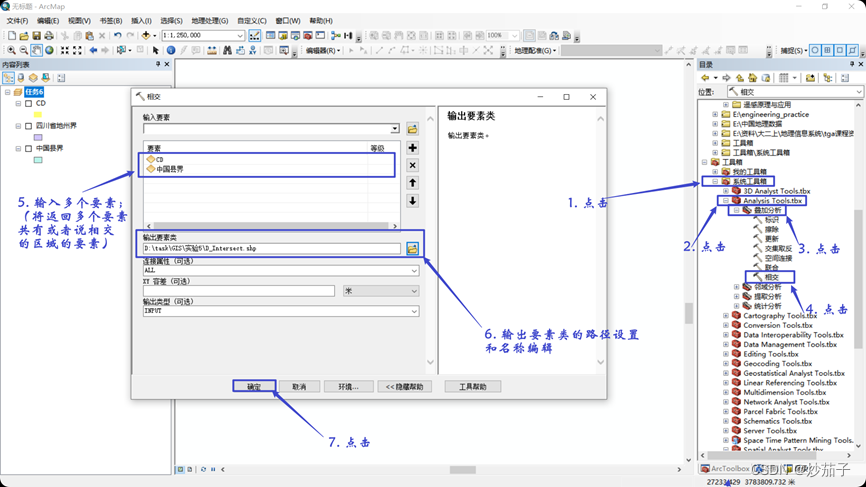
相交之后的结果展示:
4.7 缓冲区分析及栅格数据提取分析
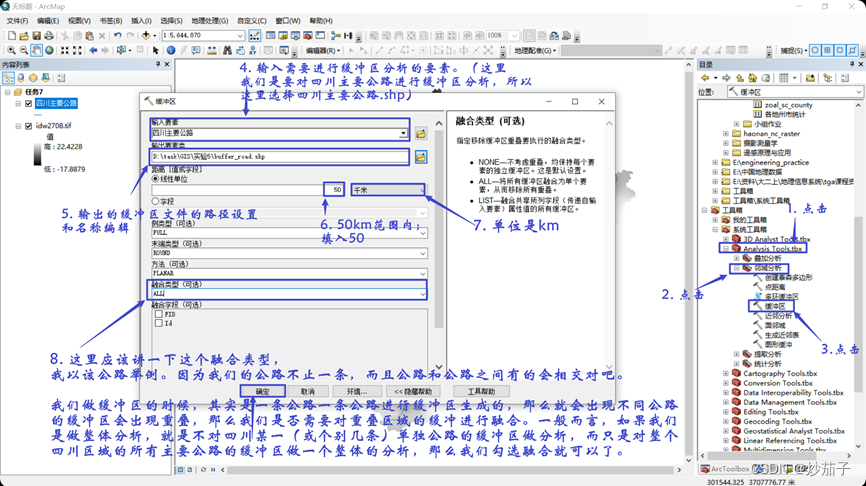
(求 27 日 08 时四川省主要公路 50 公里范围内的最高温度、 最低温度和平均温度。)
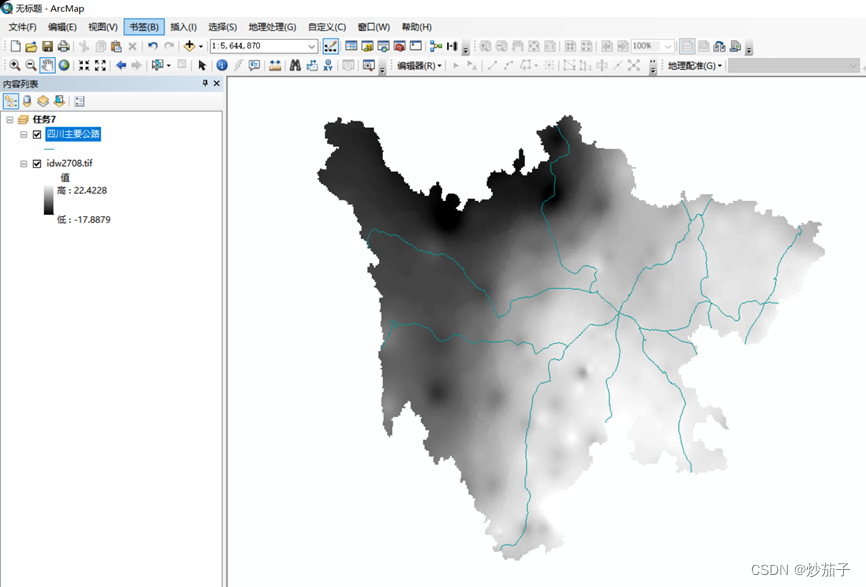
- 在 ArcMap 中插入数据帧,并命名为“任务 7”,并把上一个 任务的输出结果 IDW2708 添加到任务 7,以及四川主要公路也要导入。
添加的文件结果展示:
- 使用 ArcToolbox 中“分析工具 Analysis tools”求出四川省主 要公路 50 公里范围内的缓冲区
05 思考及讨论
这次的实验总体而言不是很难,除了分区统计和插值分析前面没有接触,其它的操作在之前的实验中或多或少都有操作过,所以感觉难度可以接受。分区统计这个我觉得挺有意思,之前我做一个东西时一直想要获取某一个区域的最大最小值,而我往往都是在属性窗口看的,而且信息量很少,而这个分区统计则很好的解决了这个问题。
如果有问题,欢迎一起探讨.
<p>炒茄子</p>
这篇关于ArcGIS:如何进行离散点数据插值分析(IDW)、栅格数据的重分类、栅格计算器的简单使用、缓冲区分析、掩膜?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





