缓冲区专题

Pyserial设置缓冲区大小失败的问题解决
《Pyserial设置缓冲区大小失败的问题解决》本文主要介绍了Pyserial设置缓冲区大小失败的问题解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面... 目录问题描述原因分析解决方案问题描述使用set_buffer_size()设置缓冲区大小后,buf

Python循环缓冲区的应用详解
《Python循环缓冲区的应用详解》循环缓冲区是一个线性缓冲区,逻辑上被视为一个循环的结构,本文主要为大家介绍了Python中循环缓冲区的相关应用,有兴趣的小伙伴可以了解一下... 目录什么是循环缓冲区循环缓冲区的结构python中的循环缓冲区实现运行循环缓冲区循环缓冲区的优势应用案例Python中的实现库

Linux中的缓冲区和文件系统详解
《Linux中的缓冲区和文件系统详解》:本文主要介绍Linux中的缓冲区和文件系统方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录一、FILE结构1、fd2、缓冲区二、文件系统1、固态硬盘2、逻辑地址LBA(一)数据块 Data blocks(二)inode表

【0324】Postgres内核 Shared Buffer Access Rules (共享缓冲区访问规则)说明
0. 章节内容 1. 共享磁盘缓冲区访问机制 (shared disk buffers) 共享磁盘缓冲区有两套独立的访问控制机制:引用计数(a/k/a pin 计数)和缓冲区内容锁。(实际上,还有第三级访问控制:在访问任何属于某个关系表的页面之前,必须持有该关系表的适当类型的锁。这里不讨论关系级锁。) Pins 在对缓冲区做任何操作之前,必须“对缓冲区pin”(即增加其引用计数, re

工作集、granule、缓冲区、缓冲池概念及关系?
工作集、granule、缓冲区、缓冲池概念及关系? granule:为了让内存在db_chache_size和shared_pool_size之间高效的移动,oracle在9i重构SGA,使用固定大小的内存块即为granule。这个参数就是为什么当你分配给shared pool值的时候,为什么有时候比你分配的值要大一点,但是granule的整数倍。 缓冲区:内存存放数据的地方,类似于数

圆形缓冲区-MapReduce中的
这篇文章来自一个读者在面试过程中的一个问题,Hadoop在shuffle过程中使用了一个数据结构-环形缓冲区。 环形队列是在实际编程极为有用的数据结构,它是一个首尾相连的FIFO的数据结构,采用数组的线性空间,数据组织简单。能很快知道队列是否满为空。能以很快速度的来存取数据。 因为有简单高效的原因,甚至在硬件都实现了环形队列。 环形队列广泛用于网络数据收发,和不同程序间数据交换(比如内核与应用

Kafka【五】Buffer Cache (缓冲区缓存)、Page Cache (页缓存)和零拷贝技术
【1】Buffer Cache (缓冲区缓存) 在Linux操作系统中,Buffer Cache(缓冲区缓存)是内核用来优化对块设备(如磁盘)读写操作的一种机制(故而有一种说法叫做块缓存)。尽管在较新的Linux内核版本中,Buffer Cache和Page Cache已经被整合在一起,但在理解历史背景和功能时,了解Buffer Cache仍然很有帮助。 Buffer Cache 的历史和定义

两个月冲刺软考——概念+求已知内存按字节编址从(A)…到(B)…的存储容量+求采用单/双缓冲区需要花费的时间计算 类型题目讲解
1.四个周期的区别与联系 时钟周期:也称为CPU周期或机器周期,是CPU操作的基本时间单位。 指令周期:是指CPU执行一条指令所需的全部时间。一个指令周期通常由多个时钟周期组成,因为执行一条指令可能需要多个步骤,如取指令、译码、执行、访存和写回等。 总线周期:总线周期是数据在计算机总线上传输所需的时间。 它涉及CPU与其他系统组件(如内存、输入/输出设备)之间的数据传输。一个总线周期可能包括

一个免锁环形缓冲区的实现
面是串口DMA+环形缓冲区的实现,数据收发是异步的,不需要死等。 关于环形缓冲区参考: 1 2 http://blog.csdn.net/jieffantfyan/article/details/53572103 实现原理 程序是在串口中断收发方式的基础上设计的,应用层通过环形缓冲区进行串口数据读取,环形缓冲区作为一级缓存,增加DMA作为二级缓存。相对中断方式这种设计可以减少串口进入中断的次数,

golang基础-终端读(Scanln\bufio)、bufio文件读、、ioutil读读压缩、缓冲区读写、文件写入、文件拷贝
终端读写Scanln、Sscanfbufio带缓冲区的读bufio文件读(1)bufio文件读(2)通过ioutil实现读读取压缩文件文件写入文件拷贝 终端读写Scanln、Sscanf package mainimport ("fmt")var (firstName, lastName, s stringi intf
文章解读与仿真程序复现思路——电网技术@EI\CSCD\北大核心《基于双缓冲区生成对抗模仿学习的电力系统实时安全约束经济调度》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源程序擅长文章解读,论文与完整源程序,等方面的知识,电网论文源程序关注python

Linux 用户缓冲区
1. 文件描述符的分配规则 我们知道Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入stdin--0, 标准输出stdout--1, 标准错误stderr--2。0,1,2对应的物理设备一般是:键盘,显示器,显示器.接下来我们来研究文件描述符的分配规则,代码如下。 #include<stdio.h>#include<sys/types.h>#include<sys/st
![[Meachines] [Insane] Bankrobber XSS-MDOG+SQLI+XSRF+Local-RCE+Bankv2转账模拟应用缓冲区溢出](https://img-blog.csdnimg.cn/img_convert/21bf917bfdb878e22b164fedc3d8bb33.jpeg)
[Meachines] [Insane] Bankrobber XSS-MDOG+SQLI+XSRF+Local-RCE+Bankv2转账模拟应用缓冲区溢出
信息收集 IP AddressOpening Ports10.10.10.154TCP:80,443,445,3306 $ nmap -p- 10.10.10.154 --min-rate 1000 -sC -sV -Pn PORT STATE SERVICE VERSION 80
c printf 缓冲区分析
printf行缓冲区的分析总结 2013-08-18 12:29 5222人阅读 评论(7) 收藏 举报 分类: app program(9) 版权声明:本文为博主kerneler辛苦原创,未经允许不得转载。 最近在客户那调试串口的时候,read串口然后printf打印,单字符printf,发现没有输出,后来想起来printf这些

android openGL ES详解——深度缓冲区
一、深度缓冲区概念 深度缓存区是指一块专门内存区域,存储在显存中,用于存储屏幕上所绘制图形的每个像素点的深度值。深度值越大,离观察者越远。深度值越小,里观察者越近。 深度缓冲区与帧缓冲区相对应,用于记录上面每个像素的深度值,通过深度缓冲区,我们可以进行深度测试,从而确定像素的遮挡关系,保证渲染正确。 二、深度概念 深度,指OpenGL坐标系中,像素点的Z坐标距观察者的距离。其实就是该象素点

缓冲区与缓存(buffer与cache)
文章目录 缓冲区与缓存(buffer与cache)1.缓冲区buffer缓存区的作用Python中的缓冲缓存区的类型 2.缓存cache缓存的适用场景缓存的三种模式Python中的缓存 缓冲区与缓存(buffer与cache) 1.缓冲区buffer 缓冲区(buffer),它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数

Linux基础I/O之文件缓冲区
一、缓冲区的基本概念 缓冲区这个概念,我相信大家或多或少的有听到过,那么其到底是个什么东西呢? 简单地理解一下,其可以被看做一部分的内存(可以认为是malloc来的)。 那为什么要有缓冲区这个东西呢?其有什么作用呢?先说结论,缓冲区的主要作用就是来提高我们的效率(提高使用者的效率,提高发送效率)。那其是如何做到提高效率的呢?这里我给大家举个例子:

linux文件——用户缓冲区——概念深度理解、IO模拟实现
前言:本篇文章主要讲解文件缓冲区。 讲解的方式是通过抛出问题, 然后通过分析问题, 将缓冲区的概念与原理一步一步地讲解。同时, 本节内容在最后一部分还会带友友们模拟实现一下c语言的printf, fprintf接口, 加深友友们对于缓冲区的理解。 ps: 本节内容适合了解linux进程和linux文件重定向的友友们进行观看。 目录 缓冲区概念——使用c

【传输层协议】UDP协议 {端口号的范围划分;UDP数据报格式;UDP协议的特点;UDP的缓冲区;基于UDP的应用层协议}
一、再谈端口号 1.1 使用“五元组”标识一个通信 端口号(Port)标识了一个主机上进行通信的不同的应用程序 在TCP/IP协议中, 用 “源IP”, “源端口号”, “目的IP”, “目的端口号”, “协议号” 这样一个五元组来标识一个通信(可以通过netstat -n查看); netstat 查看网络状态的重要工具 1.2 端口号的范围划分 0 - 1023:这个范围

秒懂Linux之缓冲区
目录 一.何为缓冲区 二. 缓冲区在哪 三. 模拟编码 一.何为缓冲区 缓冲区说白了就是一块内存区域,目的是为了提高使用者的效率以及减少C语言接口的使用频率~ 下面我们用一则小故事来类比出缓冲区的功能~ 张三为了给朋友李四庆祝生日快乐准备了份生日礼物~张三难道会横跨如此远的距离专门跑到新疆亲手给李四礼物吗?——这是不可能的~ 这时候张三只需要下楼到顺丰站寄礼物就完事了,

Java NIO 创建/复制缓冲区
创建缓冲区的方式 主要有以下两种方式创建缓冲区: 1、调用allocate方法 2、调用wrap方法 我们将以charBuffer为例,阐述各个方法的含义; allocate方法创建缓冲区 调用allocate方法实际上会返回new HeapCharBuffer(capacity, capacity)对象; 缓存空间存储在CharBuffer类的成员属性char[] h

【Linux详解】缓冲区优化 | 进度条的实现 | Linux下git 的上传
目录 一. 缓冲区 1. 缓冲区概念 2. 缓冲区作用 2.1 提升读写效率 2.2 减少等待时间 3. 缓冲区刷新策略 3.4 特殊策略 4. 缓冲区存储位置 5. 总结 二. 实现进度条 引入:倒计时 process.c 三. Linux下git的上传 sum 一. 缓冲区 1. 缓冲区概念 缓冲区是计算机内存的一部分,用于暂时存储数据。它在数据传输过程中
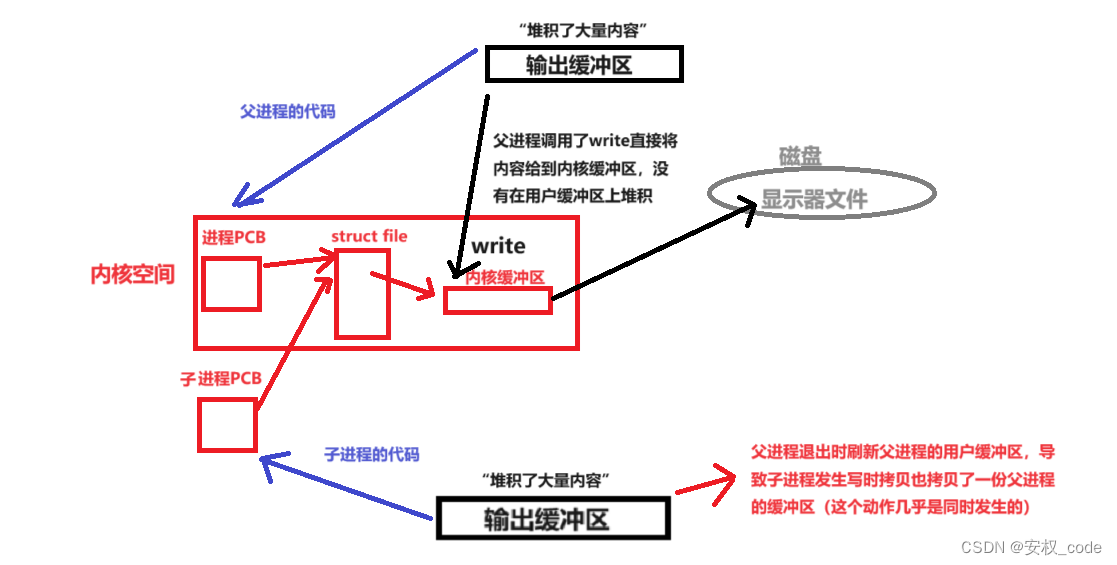
Linux_内核缓冲区
目录 1、用户缓冲区概念 2、用户缓冲区刷新策略 3、用户缓冲区的好处 4、内核缓冲区 5、验证内核缓冲区 6、用户缓冲区存放的位置 7、全缓冲 结语 前言: Linux下的内核缓冲区存在于系统中,该缓冲区和用户层面的缓冲区不过同一个概念,用户层面的缓冲区称之为用户缓冲区,而系统中也有自己的缓冲区即内核缓冲区,两者虽然同为缓冲区却差之毫厘谬以千里,
![[Vulnhub] BrainPan BOF缓冲区溢出+Man权限提升](https://img-blog.csdnimg.cn/img_convert/1f6f3d1b221242eb28cf37f9067b478e.jpeg)
[Vulnhub] BrainPan BOF缓冲区溢出+Man权限提升
信息收集 Server IP AddressPorts Open192.168.8.105TCP: $ nmap -p- 192.168.8.105 -sC -sV -Pn --min-rate 1000 Starting Nmap 7.92 ( https://nmap.org ) at 2024-06-10 04:20 EDTNmap scan report for 192.168.8
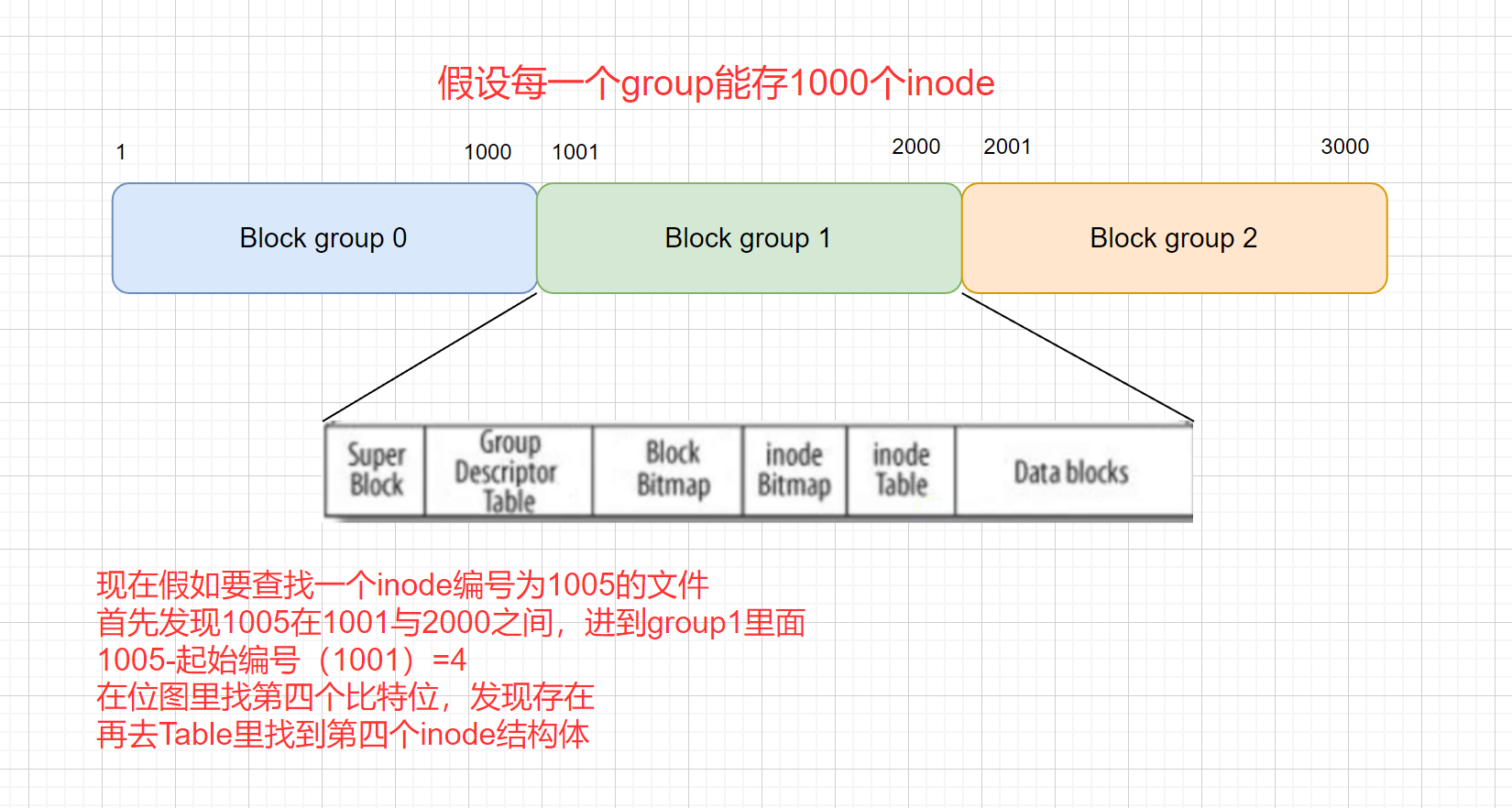
Linux:基础IO(二.缓冲区、模拟一下缓冲区、详细讲解文件系统)
上次介绍了:Linux:基础IO(一.C语言文件接口与系统调用、默认打开的文件流、详解文件描述符与dup2系统调用) 文章目录 1.缓冲区1.1概念1.2作用与意义 2.语言级别的缓冲区2.1刷新策略2.2具体在哪里2.3支持格式化 3.自己来模拟一下缓冲区3.1项目文件规划3.2mystdio.h3.3mystdio.c3.4test.c 4.文件系统4.1磁盘机械结构4.2磁盘的物
