本文主要是介绍【Linux详解】缓冲区优化 | 进度条的实现 | Linux下git 的上传,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一. 缓冲区
1. 缓冲区概念
2. 缓冲区作用
2.1 提升读写效率
2.2 减少等待时间
3. 缓冲区刷新策略
3.4 特殊策略
4. 缓冲区存储位置
5. 总结
二. 实现进度条
引入:倒计时
process.c
三. Linux下git的上传
sum
一. 缓冲区
1. 缓冲区概念
缓冲区是计算机内存的一部分,用于暂时存储数据。它在数据传输过程中起到一个缓冲桥梁的作用,帮助协调数据传输的速度差异。缓冲区可以是磁盘缓存,网络传输中的数据缓存等。
2. 缓冲区作用
缓冲区的作用非常广泛和重要,主要体现在以下几个方面:
2.1 提升读写效率
当进程要进行文件读写操作时,数据会首先存储在缓冲区中,而不是直接写入磁盘。缓冲区根据特定的刷新策略定期或在特定条件下将数据写入磁盘。这样可以减少磁盘的频繁读写动作,从而提升整体系统的效率。
2.2 减少等待时间
在没有缓冲区的情况下,每次文件读写操作都需要等待外设(如磁盘)就绪,这可能会导致显著的等待时间。缓冲区减少了这种等待时间,因为数据可以暂时存储在内存中,进程可以继续执行其他任务,而无需等待外设操作完成。
先说一下 unistd.h 库中的 sleep 函数,它可以按照秒去休眠
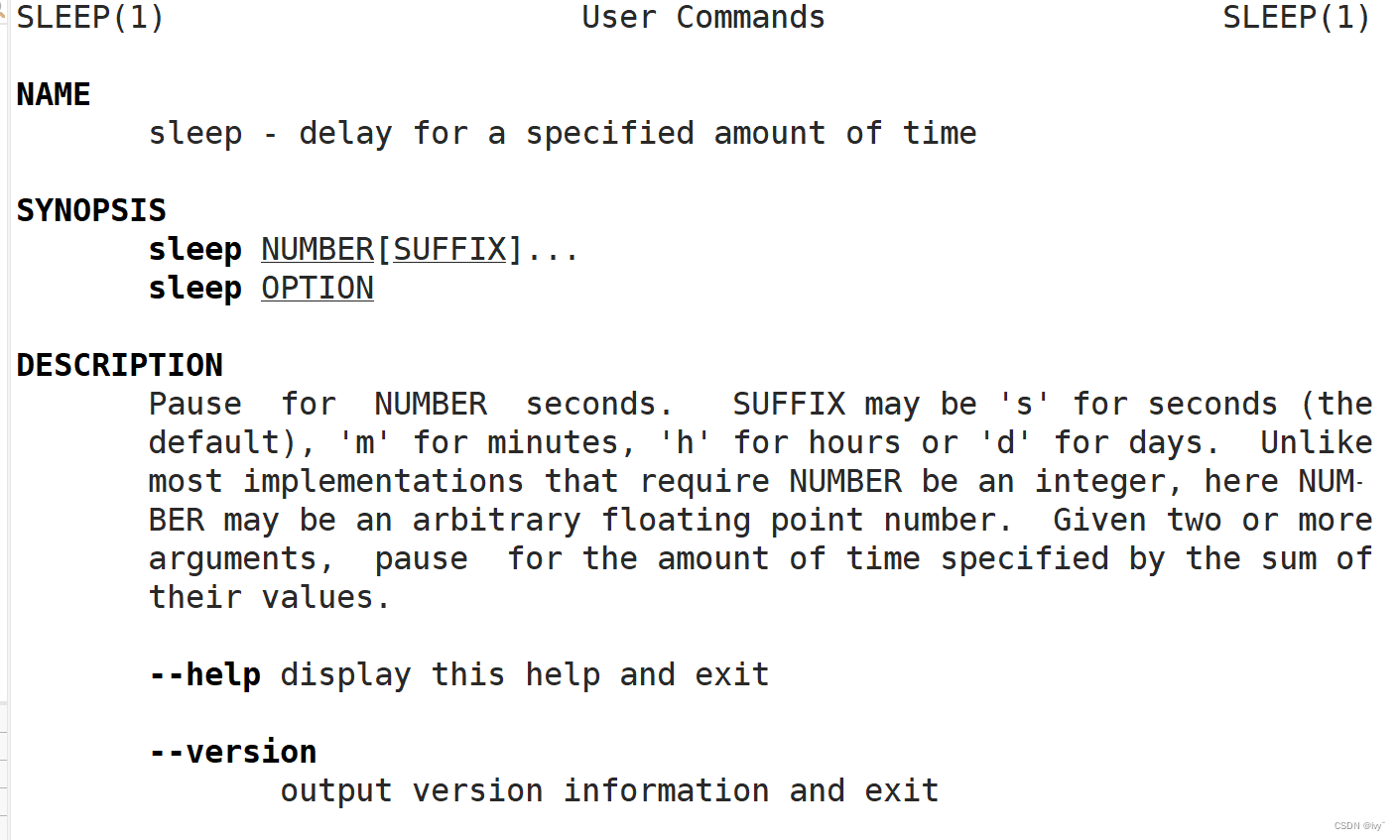
我们可以
man sleep了解到如上内容,代码演示:
#include <stdio.h>
#include <unistd.h>int main(void) {printf("hello\n"); sleep(2); return 0;
} 会发现代码是自上而下,正常运行的,那如果我们尝试去掉hello后面的\n会发生什么呢
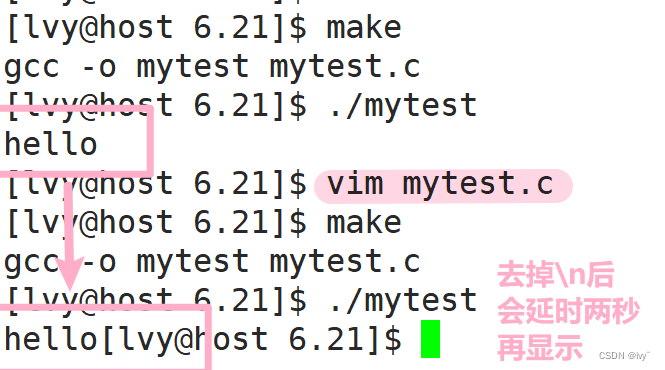
实际上,printf 已经先执行了,只是这个 "Helo,World" 没有立马被显示出来罢了!
当我们 sleep 时也没有显示,当我们 sleep 完甚至到程序退出后,这个 "Helo,World" 才显示出来。
说明带有\n会马上刷新,那么不带的时候,那2s 代码又存在哪里呢?
就是存在我们的缓冲区啦, return 退出的时候,这个数据才显示出来,所以才看到了我们现在看到的现象
3. 缓冲区刷新策略
缓冲区的刷新策略决定了何时将缓冲区中的数据真正写入到目标存储器,如磁盘或显示器。主要有以下几种策略:
数据一写入缓冲区就立即刷新写入目标设备。这种方式适合对时间敏感的操作,但可能导致系统资源的低效利用。
当缓冲区检测到换行符(\n)时,立即刷新写入目标设备。这种方式常用于终端显示器,以保证一行行的输出效果。例如,在终端或控制台输出时,行缓冲能确保即时显示用户输入的一行内容。
只有当缓冲区满了时,才会将数据刷新写入目标设备。这种方式适合大量数据的写入操作,能提高整体的写入效率。例如,在将数据写入磁盘文件时,通常使用全缓冲策略。
3.4 特殊策略
- 用户强制刷新
用户可以显式调用刷新函数(如fflush(FILE *stream))来强制刷新缓冲区内容。- 进程退出刷新
当进程正常退出时,缓冲区会自动刷新,以确保所有已写入缓冲区但尚未写入目标设备的数据都被处理完毕。
如果我们想让上面的hello马上打印,就可以进行如下操作啦
#include <stdio.h>int fflush(FILE* stream);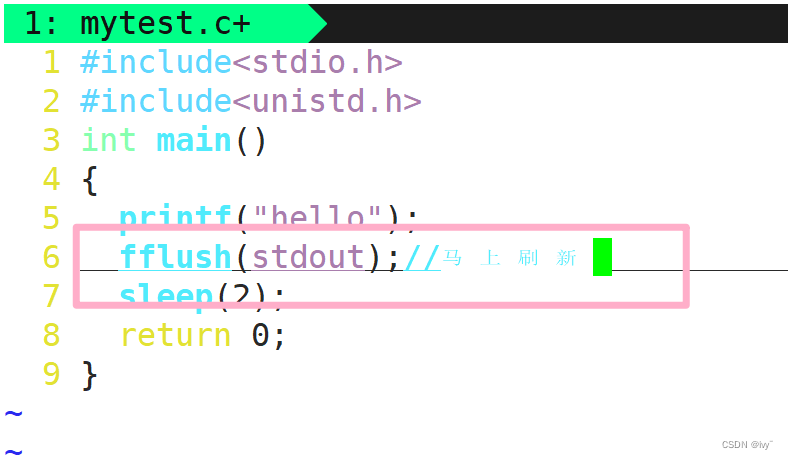
效果:

4. 缓冲区存储位置
标准输入输出流(stdin、stdout、stderr)和文件流都是 FILE* 类型,它们在缓冲区管理中扮演了重要角色。当我们打开一个文件时,系统会返回一个 FILE* 类型的指针,文件的读写和关闭操作都需要该指针作为参数。
struct FILE 封装了文件描述符(fd)、缓冲区以及缓冲区刷新策略。这使得文件操作变得高效和透明,开发者无需关心低级别的文件操作细节。
5. 总结
缓冲区是提高系统数据读写效率的重要机制。理解和有效利用缓冲区及其刷新策略,可以显著提升程序性能和资源利用效率。
二. 实现进度条
引入:倒计时
换行:/n
回车:/r
#include <stdio.h>
#include <unistd.h>int main()
{int cnt=10;while(cnt>=0)//循环判断的条件{printf("倒计时:%2d\r",cnt);//输出倒计时的数字sleep(1);//间隔一秒fflush(stdout);//刷新缓冲区cnt--;//倒计时}printf("\n");//刷新缓冲区,换行 return 0;
}

进度条
process.c
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#define MAX 100
int main()
{ int i=0; char bar[MAX+5];//设置进度条字符数组 memset(bar,0,sizeof(bar));//初始化 const char* arr="|\\-/"; //旋转字符数组while(i<=100) { printf("[%-100s][%3d%%] %c\r",bar,i,arr[i%4]);//防止越界 fflush(stdout);//马上刷新 bar[i] = '=';bar[i+1] = '>';//进度条符号 i++; usleep(50000);//0.5秒的缓冲时间 } printf("\n");//换行刷新 return 0;
}

注意:

1.打印样式的代码实现
2.fflush实现不断刷新
三. Linux下git的上传
在之前有写过【必备工具】gitee上传-保姆级教程
是借助小乌龟上传的,接下来我们将用指令来实现
1.
复制地址
2.
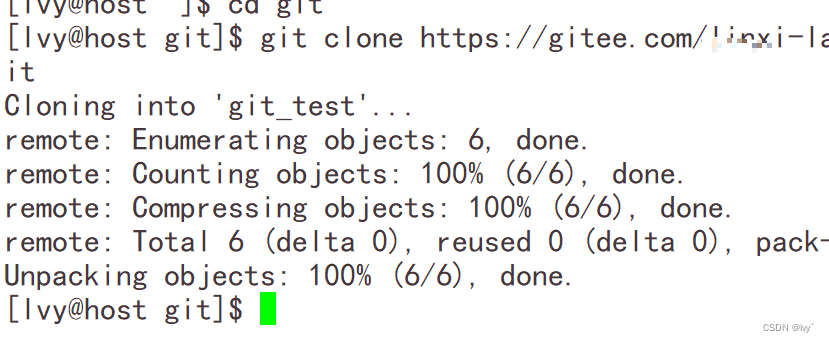
克隆
git clone
这样就是克隆成功啦
3.
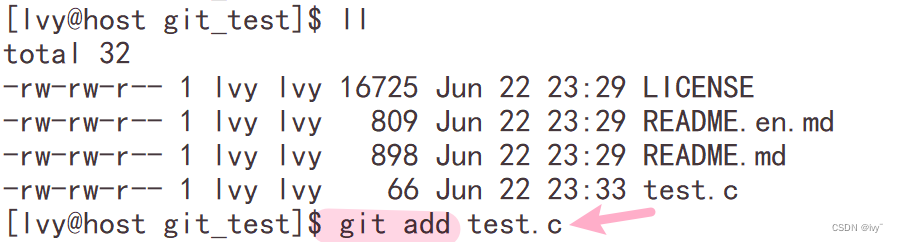
添加
git add [file name]
4.
上传
git commit -m # -m选项代表的是本次的提交日志
# 提交时应该表明提交日志、描述改动的详细内容,务必培养这个好习惯。

5.
推入
git push

上传成功啦!
sum


这篇关于【Linux详解】缓冲区优化 | 进度条的实现 | Linux下git 的上传的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





