并行计算专题

Python 中考虑 concurrent.futures 实现真正的并行计算
Python 中考虑 concurrent.futures 实现真正的并行计算 思考,如何将代码所要执行的计算任务划分成多个独立的部分并在各自的核心上面平行地运行。 Python 的全局解释器锁(global interpreter lock,GIL)导致没办法用线程来实现真正的并行,所以先把这种方案排除掉。另一种常见的方案,是把那些对性能要求比较高的(performance-critica

J.U.C Review - Stream并行计算原理源码分析
文章目录 Java 8 Stream简介Stream单线程串行计算Stream多线程并行计算源码分析Stream并行计算原理Stream并行计算的性能提升 Java 8 Stream简介 自Java 8推出以来,开发者可以使用Stream接口和lambda表达式实现流式计算。这种编程风格不仅简化了对集合操作的代码,还提高了代码的可读性和性能。 Stream接口提供了多种集合


CUDA:用并行计算的方法对图像进行直方图均衡处理
(一)目的 将所学算法运用于图像处理中。 (二)内容 用并行计算的方法对图像进行直方图均衡处理。 要求: 利用直方图均衡算法处理lena_salt图像 版本1:CPU实现 版本2:GPU实现 实验步骤一 软件设计分析: 数据类型: 根据实验要求,本实验的数据类型为一个256*256*8的整型矩阵,其中元素的值为256*256个0-255的灰度值。 存储方式: 图像在内存中

DPDK基础入门(三):并行计算
CPU亲和性 CPU亲和性(CPU Affinity)是指将特定的进程或线程绑定到特定的CPU核心或一组核心上运行。这样做的目的是提高性能和效率,避免由于线程在不同核心间频繁迁移而导致的缓存失效(cache misses)和上下文切换(context switching)开销。通过CPU亲和性,可以更好地利用CPU缓存,提高数据处理速度,特别是在高负载的环境中。 Linux内核API提供了一些

python并行计算之pool.apply_async()与pool.imap()的异同点
目录 1. 框架和技术概要: 🎨🖥️2. 相似点: 🧩💡3. 不同点: 📊👣4. 使用示例: 😊👨💻5. 总结: 🎉 1. 框架和技术概要: 🎨🖥️ multiprocessing 模块中的 pool.apply_async() 与 pool.imap() 都用于并行处理,但它们在使用方式和返回结果上有所不同。 2. 相似点: 🧩💡 并行处理
CPU服务器如何应对大规模并行计算需求?
大规模并行计算是指利用多个处理单元同时处理计算任务,以提高计算效率和缩短完成时间。这种计算方式常用于科学计算、数据分析、机器学习、图像处理等领域,面对海量数据与复杂计算时,传统的串行计算往往显得无能为力。 现代 CPU 通常具备多个核心,这使得它们能够在同一时间内并行执行多个线程或任务。多核处理器可以大幅提升并行计算能力,适合处理大型计算任务。 CPU 服务器通常配备多级高速缓存(

【并行计算】CUDA基础
cuda程序的后缀:.cu 编译:nvcc hello_world.cu 执行:./hello_world.cu 使用语言还是C++。 1. 核函数 __global__ void add(int *a, int *b, int *c) {*c = *a + *b;} 核函数只能访问GPU的内存。也就是显存。CPU的存储它是碰不到的。 并且核函数不能使用变长参数、静态变量、函数指
NLP-生成模型-2017-Transformer(一):Encoder-Decoder模型【非序列化;并行计算】【O(n²·d),n为序列长度,d为维度】【用正余弦函数进行“绝对位置函数式编码”】
《原始论文:Attention Is All You Need》 一、Transformer 概述 在2017年《Attention Is All You Need》论文里第一次提出Transformer之前,常用的序列模型都是基于卷积神经网络或者循环神经网络,表现最好的模型也是基于encoder- decoder框架的基础加上attention机制。 2018年10月,Google发出一篇

Pytorch:Tensor的高阶操作【where(按条件取元素)、gather(查表取元素)、scatter_(查表取元素)】【可并行计算,提高速度】
一、where:逐个元素按条件选取【并行计算,速度快】 torch.where(condition,x,y) #condition必须是tensor类型 condition的维度和x,y一致,用1和0分别表示该位置的取值 import torchcond = torch.tensor([[0.6, 0.7],[0.3, 0.6]])a = torch.tensor([[1., 1.],[
Python 中用线程执行阻塞式 I/O,不做并行计算
Python 中用线程执行阻塞式 I/O,不做并行计算 尽管 Python 也支持多线程,但这些线程受 GIL(global interpreter lock,全局解释器锁) 约束,所以每次或许只能有一条线程向前推进,而无法实现多头并进。既然有这么多限制,那 Python 还支持多线程干什么? 首先,这种机制让我们很容易就能实现出一种效果,也就是令人感觉程序似乎能在同一时间做许多件事。这样的效
python并发与并行(二) ———— 用线程执行阻塞式IO,但不要用它做并行计算
Python语言的标准实现叫作CPython,它分两步来运行Python程序。首先解析源代码文本,并将其编译成字节码(bytecode)。字节码是一种底层代码,可以把程序表示成8位的指令(从Python 3.6开始,这种底层代码实际上已经变成16位了,所以应该叫作wordcode才对,但基本原理依然相同)。然后,CPython采用基于栈的解释器来运行字节码。这种字节码解释器在执行Python程序的
python并发与并行(十二) ———— 考虑用concurrent.futures实现真正的并行计算
有些Python程序写到一定阶段,性能就再也上不去了。即便优化了代码,程序的执行速度可能还是达不到要求。考虑到现在的计算机所装配的CPU核心数量越来越多,所以我们很自然地就想到用并行方式来解决这个问题。那么接下来就必须思考,如何将代码所要执行的计算任务划分成多个独立的部分并在各自的核心上面平行地运行。 Python的全局解释器锁(global interpreter lock,GIL)导致我们没
并行计算的艺术:PyTorch中torch.cuda.nccl的多GPU通信精粹
并行计算的艺术:PyTorch中torch.cuda.nccl的多GPU通信精粹 在深度学习领域,模型的规模和复杂性不断增长,单GPU的计算能力已难以满足需求。多GPU并行计算成为提升训练效率的关键。PyTorch作为灵活且强大的深度学习框架,通过torch.cuda.nccl模块提供了对NCCL(NVIDIA Collective Communications Library)的支持,为多GP

高性能并行计算华为云实验五:
目录 一、实验目的 二、实验说明 三、实验过程 3.1 创建PageRank源码 3.2 makefile的创建和编译 3.3 主机配置文件建立与运行监测 四、实验结果与分析 4.1 采用默认的节点数量及迭代次数进行测试 4.2 分析并行化下节点数量与耗时的变化规律 4.3 分析迭代次数与耗时的变化规律 五、实验思考与总结 5.1 实验思考 5.2 实验总结 E

高性能并行计算华为云实验二:WordCount算法实验
目录 一、实验目的 二、实验说明 三、实验过程 3.1 创建wordcount源码 3.1.1 实验说明 3.1.2 文件创建 3.2 Makefile文件创建与编译 3.3 主机配置文件建立与运行监测 3.3.1 主机配置文件建立 3.3.2 运行监测 三、实验结果与分析 4.1 实验结果 4.2 结果分析 4.2.1 原始结果分析 4.2.2 改进后的结果分析
【每周一库】- Rayon 数据并行计算库
Rayon - 数据并行计算库 Rayon 是一个Rust的数据并行计算库。它非常轻巧,可以轻松地将顺序计算转换为并行计算。同时保证不会有数据争用情况出现。 并行迭代器 使用Rayon,可以轻松地将顺序迭代器转换为并行迭代器:通常,只需将您的foo.iter()调用更改为foo.par_iter(),其余则由Rayon完成: use rayon::prelude::*;fn sum_of_sq
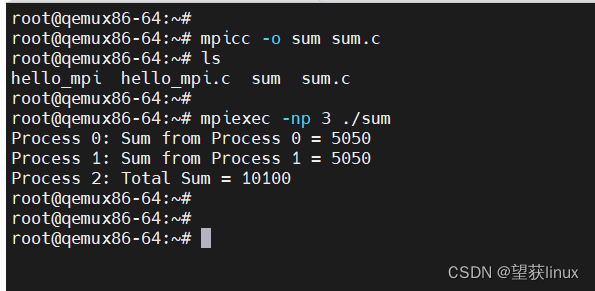
MPI并行计算关键点讲解及使用入门
MPI(Message Passing Interface)是并行计算领域的一个关键标准,它定义了一套用于在多个计算节点间进行高效消息传递和数据交换的通信协议和库。在高性能计算(HPC)领域,MPI尤为重要,特别是在处理大规模科学计算、模拟和数据分析等复杂任务时。 MPI关键点讲解 分布式内存模型 MPI基于分布式内存模型,每个计算节点(可能是独立的计算机或处理器)拥有其独立的内
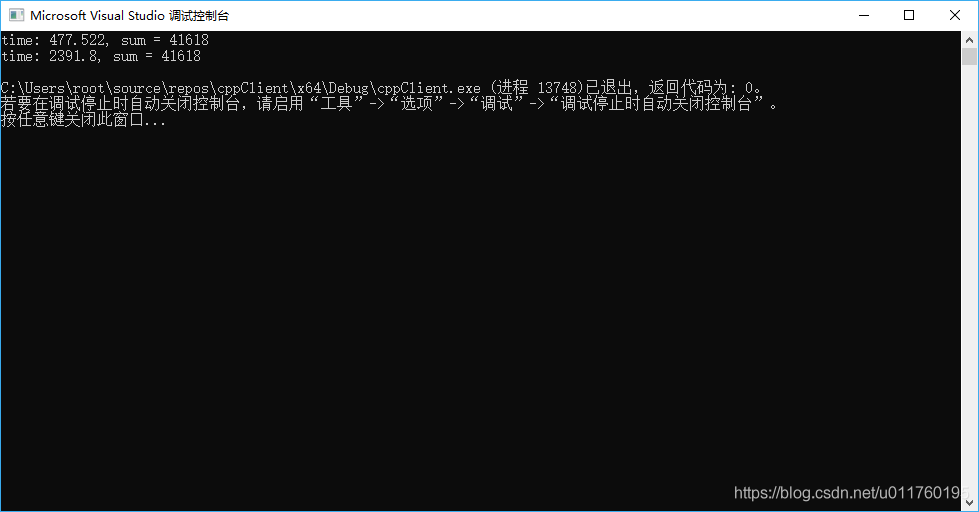
C++多线程并行计算
C++多线程并行计算 多线程(std::thread) 多线程(std::thread) 写了一个简短的并行计算例子 存粹的利用CPU性能计算素数个数 //实现标准库头文件<numeric>中accumulate函数的并行版本#include <iostream>#include <thread>#include <numeric>#include <algorithm
并行计算简介和多核CPU编程Demo
tag:多线程,并行计算,OpenMP,多核编程,工作线程池 ( 2008.01.19 更新 鉴于读者反映代码阅读困难,重新改写了文章和实现,使文章更易读 ) ( 2007.09.04 更新 把用事件控制的线程启动更新为临界区的实现 ) 2006年是双核的普及年,双核处理器出货量开始超过单核处理器出货量;2006年的11月份Intel开始供货4核;AMD今年也将发布4核,并计划

Python 大规模数据存储与读取、并行计算:Dask库简述
本文转自:https://blog.csdn.net/sinat_26917383/article/details/78044437 数据结构与pandas非常相似,比较容易理解。 原文文档:http://dask.pydata.org/en/latest/index.html github:https://github.com/dask dask的内容很多,挑一些我比较看好的内容着重点一

DASK==python并行计算
文档10 Minutes to Dask — Dask documentation demo代码 import numpy as npimport pandas as pdimport dask.dataframe as ddimport dask# 设置调度器为多线程dask.config.set(scheduler='threads')# 创建一个示例的Pandas DataFr
你应该这样去开发接口:Java多线程并行计算(Google的Guava使用)
所谓的高并发除了在架构上的高屋建瓴,还得需要开发人员在具体业务开发中注重自己的每一行代码、每一个细节,面子有的同时,更重要的还是要有里子。 面对性能,我们一定要有自己的工匠精神,不可以对任何一行代码妥协! 今天和大家分享在业务开发中如何降低接口响应时间的一个小技巧,也是大家日常开发中比较普遍存在的一个问题,即如何提高程序的并行计算能力? 本文主要包含以下内容: 顺序执行很慢线程池+Fu

(2024,attention,可并行计算的 RNN,并行前缀扫描)将注意力当作 RNN
Attention as an RNN 公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 3. 方法 3.1 注意力作为一种(多对一的)RNN 3.2 注意力作为(多对多)RNN 3.3 Aaren: 将注意力当作 RNN 4. 实验 附录 F. 计算时间 0. 摘要 随着 Transfor
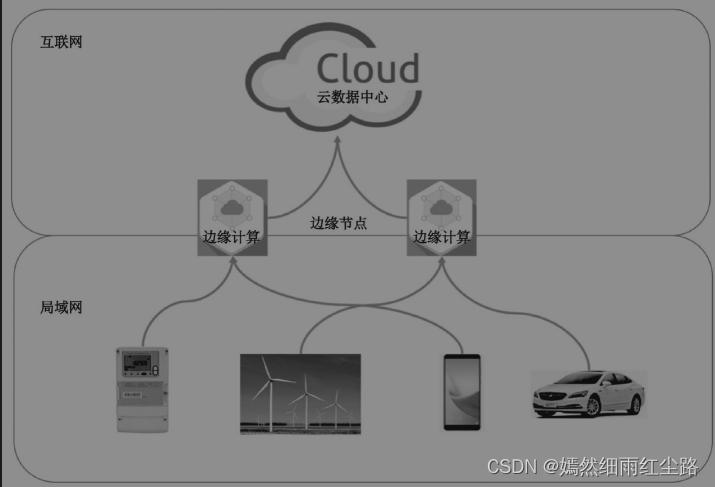
分布式计算、并行计算、网格计算、边缘计算
分布式计算 分布式计算是一种计算方法,它将一个大型的计算任务分解成多个子任务,并将这些子任务分布在网络上的多台计算机(节点)上同时执行。这些节点通过通信网络协同工作,共同完成任务。每个节点可以独立处理自己的那部分数据或计算任务,最终汇总结果。分布式计算特别适用于处理那些需要巨大计算资源或数据处理能力的问题,如大规模数据分析、模拟和科研项目(如SETI@home寻找外星智能项目)。它的优势在于能够
VIVADO HLS并行计算加速,fpga
https://blog.csdn.net/weixin_39942351/article/details/111202292?utm_medium=distribute.pc_relevant_download.none-task-blog-baidujs-4.nonecase&depth_1-utm_source=distribute.pc_relevant_download.none-tas