并行度专题

处理List采用并行流处理时,通过ForkJoinPool来控制并行度失控的问题
在使用parallelStream进行处理list时,如不指定线程池,默认的并行度采用cpu核数进行并行,这里采用ForJoinPool来控制,但循环中使用了redis获取key时,出现失控。具体上代码。 @RunWith(SpringRunner.class)@SpringBootTest(classes = Application.class)@Slf4jpublic class Fo
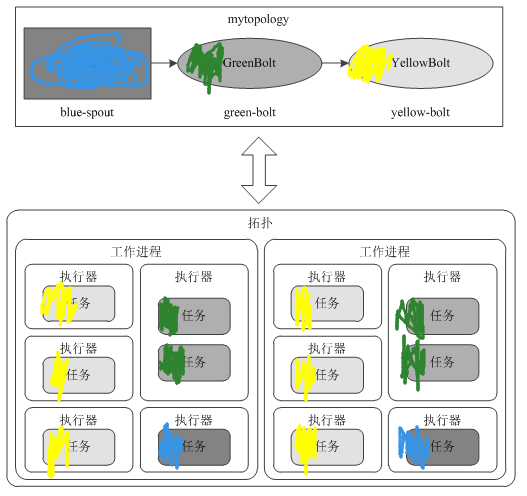
二、Topology的并行度
1、几个概念 Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程,这个工作进程就是worker。一个topology可能会在一个或者多个工作进程里面执行,每个工作进程执行整个topology的一部分。每一个worker都会占用工作节点的一个端口,这个端口可以在storm.yarm中配置。 每一个Spout和Bolt会被当作很多task在整个集群里面执行。

spark 大型项目实战(四十一):算子调优之使用repartition解决Spark SQL低并行度的性能问题
并行度:之前说过,并行度是自己可以调节,或者说是设置的。 1、spark.default.parallelism 2、textFile(),传入第二个参数,指定partition数量(比较少用) 咱们的项目代码中,没有设置并行度,实际上,在生产环境中,是最好自己设置一下的。官网有推荐的设置方式,你的spark-submit脚本中,会指定你的application总共要启动多少个executo

SparkCore(11):RDD概念和创建RDD两种方法,以及RDD的Partitions以及并行度理解
一、RDD概念 1.概念 Resilient Distributed Datasets弹性分布式数据集,默认情况下:每一个block对应一个分区,一个分区会开启一个task来处理。 (a)Resilient:可以存在给定不同数目的分区、数据缓存的时候可以缓存一部分数据也可以缓存全部数据 (b)Distributed:分区可以分布到不同的executor执行(也就是不同的worker/NM上执
Flink 单并行度内使用多线程来提高作业性能
分析痛点 笔者线上有一个 Flink 任务消费 Kafka 数据,将数据转换后,在 Flink 的 Sink 算子内部调用第三方 api 将数据上报到第三方的数据分析平台。这里使用批量同步 api,即:每 50 条数据请求一次第三方接口,可以通过批量 api 来提高请求效率。由于调用的外网接口,所以每次调用 api 比较耗时。假如批次大小为 50,且请求接口的平均响应时间为 50ms,使用同步

计算机体系结构:并行度与并行体系结构的分类
计算机中常见的并行: 指令级并行(ILP): 利用编译器的帮助和硬件支持(如流水线、超标量架构、推测执行等技术),在单个处理器内同时执行多条指令,以减少指令执行的串行依赖,实现有限程度的数据级并行。 向量体系结构与GPU: 向量处理器或图形处理器(GPU)设计为一次对一组数据(向量或数组)执行相同的单条指令,实现大规模数据级并行。这类架构特别适合处理大规模并行数据运算,如科学计算、图像处理

MapReduce——ReudceTask并行度决定机制
MapReduce——ReudceTask并行度决定机制 1. Reduce任务的数量(reduce task count): 这是最基本的决定因素之一。在作业启动时,用户可以指定Reduce任务的数量。更多的Reduce任务意味着更多的并行度,因为每个Reduce任务可以在不同的数据分区上独立运行。 2. 输入数据的分区数(number of input partitions):
【Flink精讲】Flink性能调优:CPU核数与并行度
常见问题 举个例子 提交任务命令: bin/flink run \ -t yarn-per-job \ -d \ -p 5 \ 指定并行度 -Dyarn.application.queue=test \ 指定 yarn 队列 -Djobmanager.memory.process.size=2048mb \ JM2~4G 足够 -Dtaskmanager.memory.process.si

storm(四) 并行度
概念 worker 一个实体机可以运行一个或者多个worker一个worker只能运行一个topology上的部分或全部component一个worker是一个独立的进程在运行过程中可以调整worker的数量 executor 一个worker中可以运行多个executor一个executor是一个线程一个executor可以运行一个或者多个task,这些task必须是同一类型execut
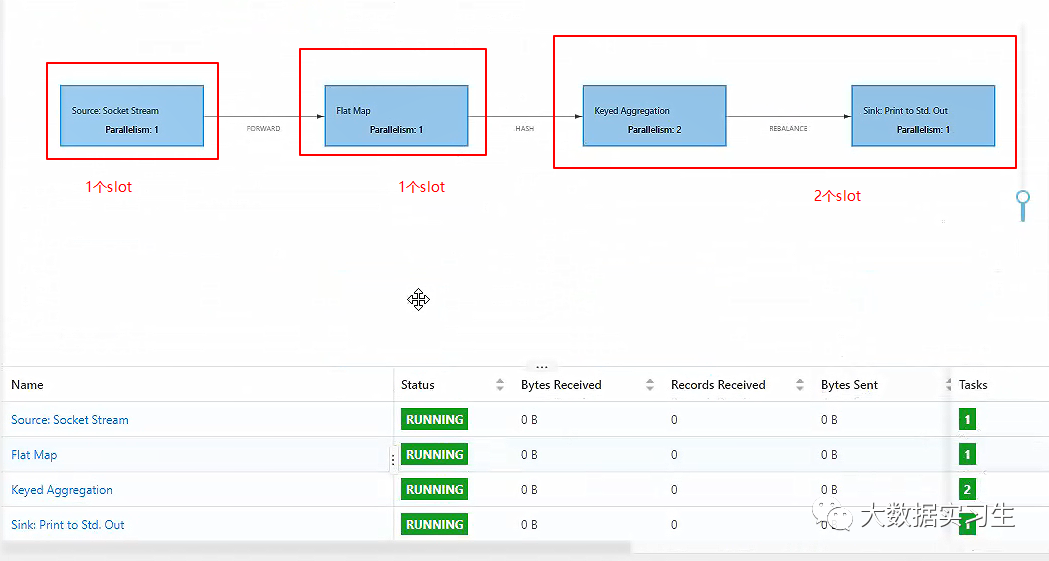
【大数据】Flink 中的 Slot、Task、Subtask、并行度
Flink 中的 Slot、Task、Subtask、并行度 1.并行度2.Task 与线程3.算子链与 slot 共享资源组4.Task slots 与系统资源5.总结 我们在使用 Flink 时,经常会听到 task,slot,线程 以及 并行度 这几个概念,对于初学者来说,这几个概念以及它们与内存,CPU 之间的关系经常搞不清楚,下面我们就通过这篇文章来弄清楚这些概念。

Java大数据学习07--Mapreduce--MapTask和ReduceTask并行度的决定机制
一、mapTask并行度的决定机制 1、maptask的并行度决定map阶段的任务处理并发度,它可以决定job的处理速度。但并不是MapTask并行实例越多越好,它是综合了很多因素来决定的。 2、一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每

72.Spark大型电商项目-算子调优之使用repartition解决Spark SQL低并行度的性能问题
目录 并行度 问题解析 解决方法 设置前 设置后 本篇文章记录算子调优之使用repartition解决Spark SQL低并行度的性能问题。 并行度 之前说过,并行度是自己可以调节,或者说是设置的。 1、spark.default.parallelism 2、textFile(),传入第二个参数,指定partition数量(比较少用) 在项目代码中,没有设置并行度,实
Spark性能调优之合理设置并行度
1.Spark的并行度指的是什么? spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度! 当分配完所能分配的最大资源了,然后对应资源去调节程序的并行度,如果并行度没有与资源相匹配,那么导致你分配下去的资源都浪费掉了。同时并行运行,还可以让每个task要处理的数量变少(很简单的原理。合理设置并行度,可以充分利用集群资源,减少每个
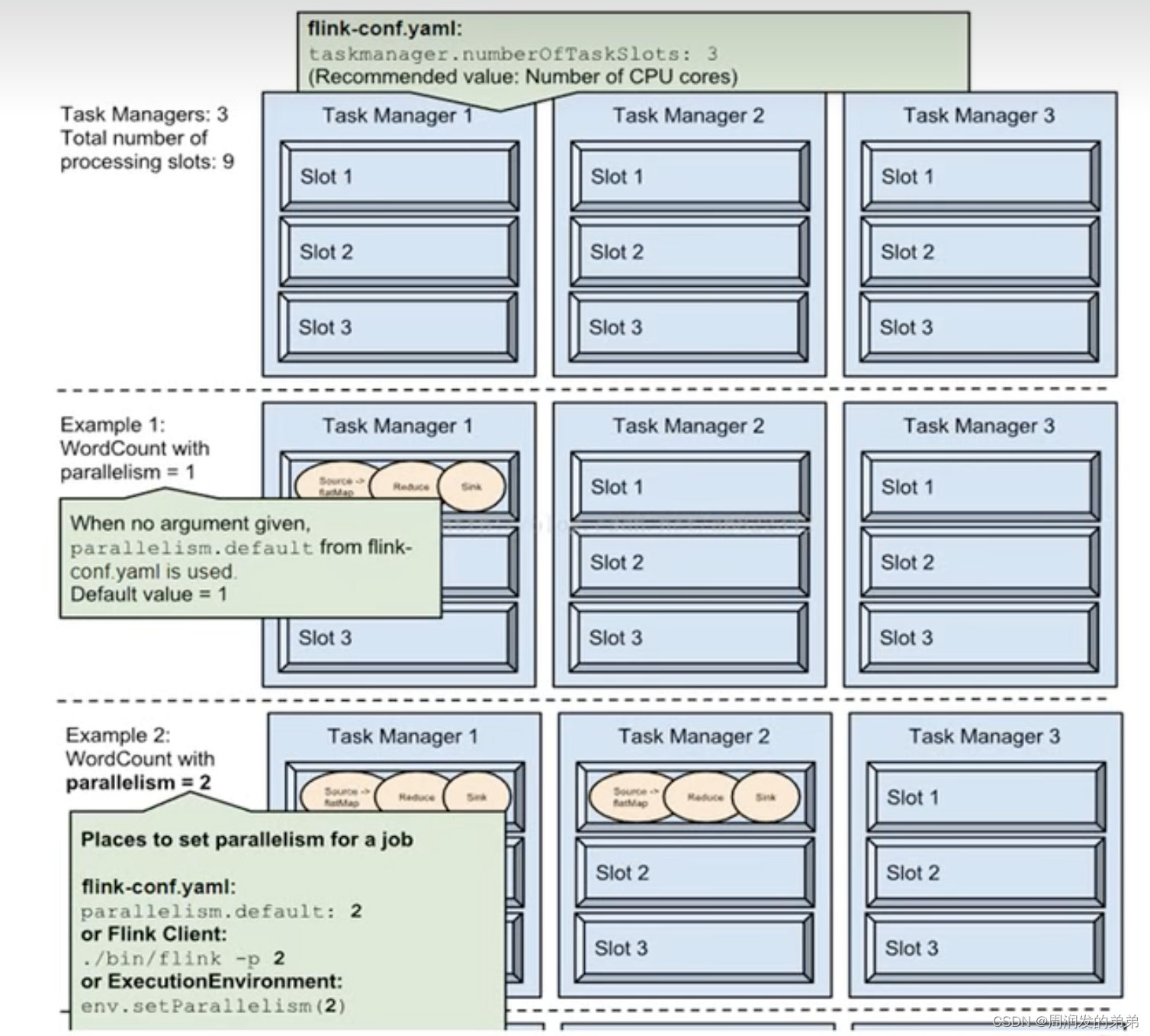
【Flink系列二】如何计算Job并行度及slots数量
接上文的问题 并行的任务,需要占用多少slot ?一个流处理程序,需要包含多少个任务 首先明确一下概念 slot:TM上分配资源的最小单元,它代表的是资源(比如1G内存,而非线程的概念,好多人把slot类比成线程,是不恰当的) 任务(task):线程调度的最小单元,和java中的类似。 ---------------------------------------------------

Flink TaskSlot与并行度
文章目录 一、Flink的Task、SubTask二、算子链三、什么情况下算子可以组合为算子链?四、算子链操作五、并行度六、TaskSlot与并行度的联系七、槽位共享八、并行度设置注意事项九、并行度设置十、并行度优先级十一、并行度Parallelism与任务槽TaskSlot总结十二、Local模式下注意事项 上文说到:TaskManager 是一个 JVM 进程,是实际负责执行计
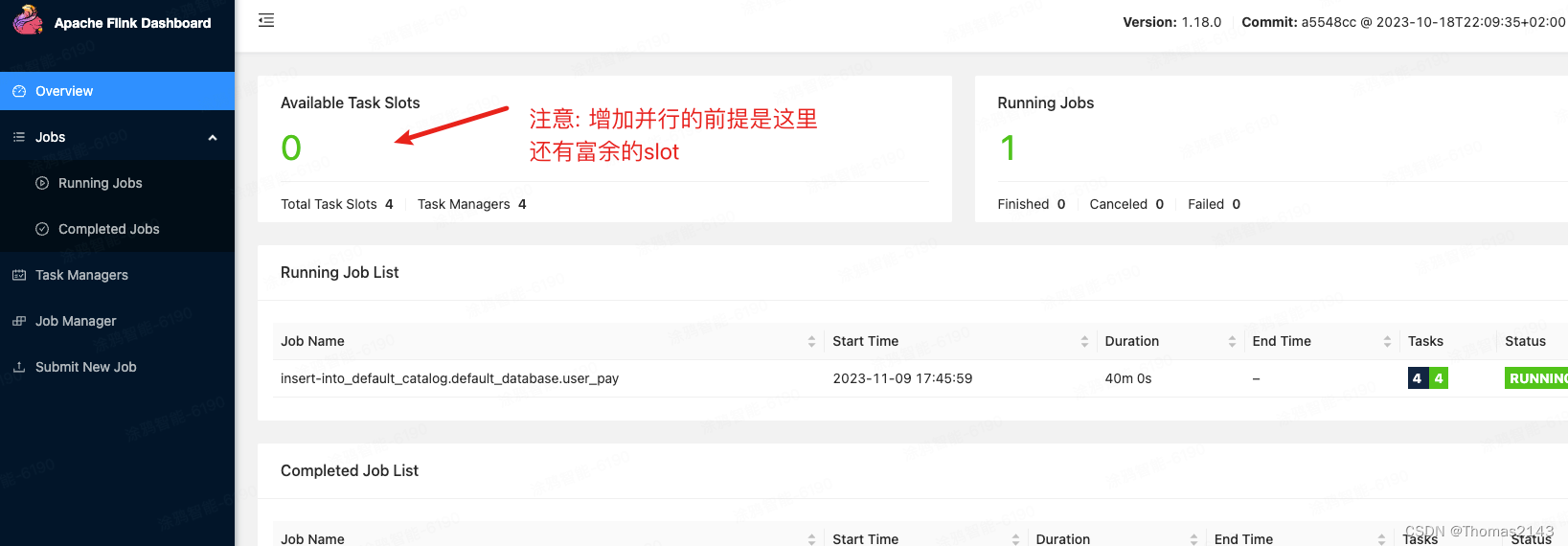
flink1.18.0 自适应调度器 资源弹性缩放 flink帮你决定并行度
jobmanager.scheduler Elastic Scaling | Apache Flink 配置文件修改并重启flink后,webui上会显示调整并行度的按钮,他可以自己调整,你也可以通过webUI手动调整: 点击 + 之后: 调整完成后:
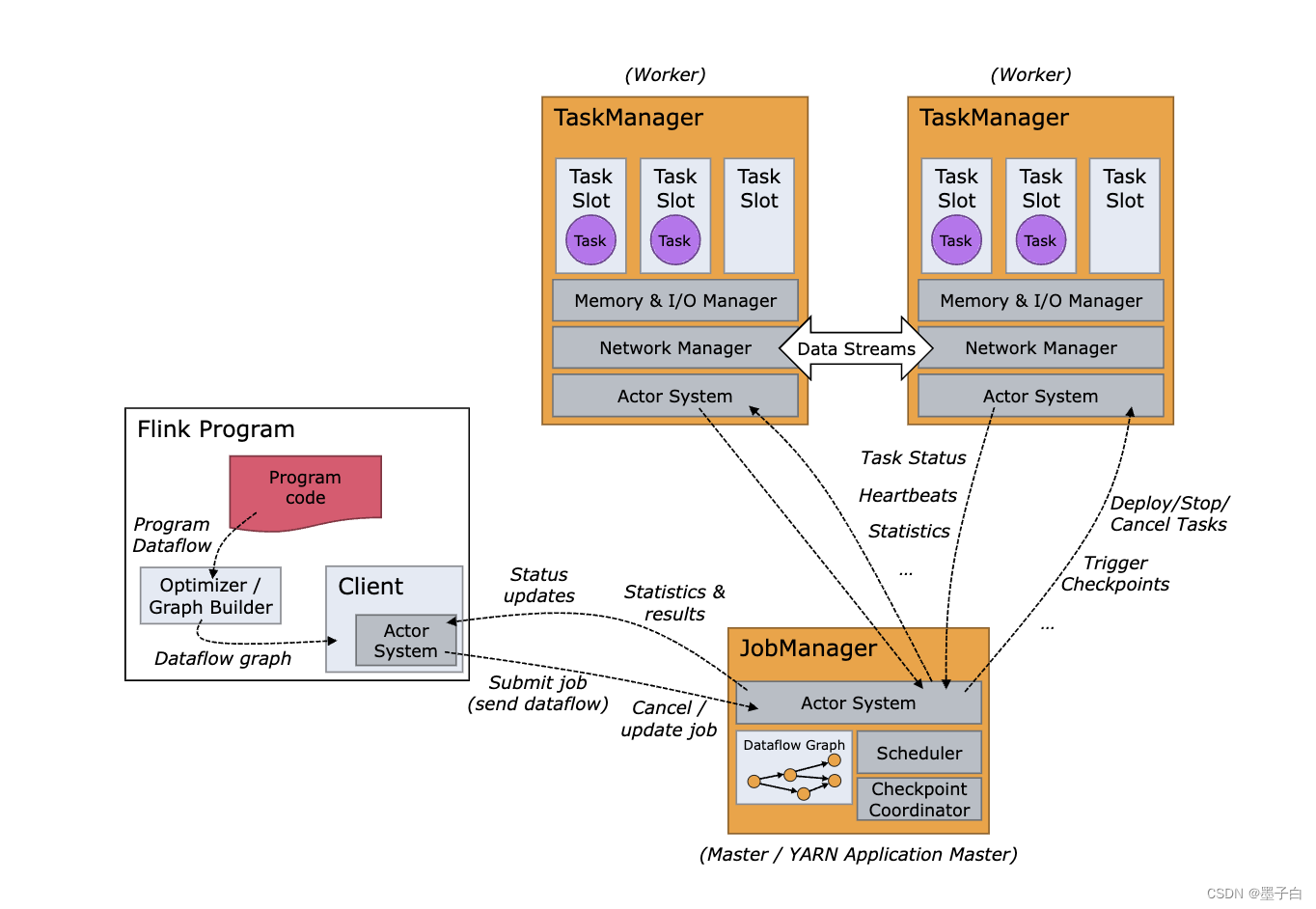
Flink的API分层、架构与组件原理、并行度、任务执行计划
Flink的API分层 Apache Flink的API分为四个层次,每个层次都提供不同的抽象和功能,以满足不同场景下的数据处理需求。下面是这四个层次的具体介绍: CEP API:Flink API 最底层的抽象为有状态实时流处理。其抽象实现是Process Function,并且Process Function被 框架集成到了DataStream API中来为我们使用
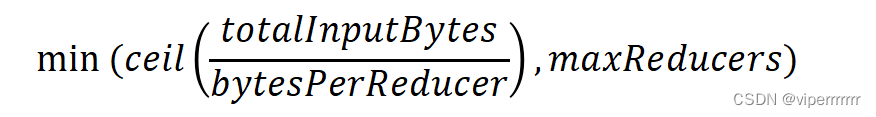
大数据学习(18)-任务并行度优化
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞 对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。Hive的计算任务由MapReduce完成,故并行度的调整需要分为Map端和Reduce端。 12.7.1.1 Map端并行度 Map端的并行度,也就是Ma
三、Spark性能调优——并行度调节
val conf = new SparkConf().set("spark.default.parallelism", "500") Spark 作业中的并行度指各个 stage 的 task 的数量。 如果并行度设置不合理而导致并行度过低, 会导致资源的极大浪费,例如, 20个 Executor,每个 Executor 分配 3 个 CPU core, 而 Spark 作业有 40 个 t
Flink如何基于事件时间消费分区数比算子并行度大的kafka主题
背景 使用flink消费kafka的主题的情况我们经常遇到,通常我们都是不需要感知数据源算子的并行度和kafka主题的并行度之间的关系的,但是其实在kafka的主题分区数大于数据源算子的并行度时,是有一些注意事项的,本文就来讲解下这些注意事项 flink数据源算子并行度大于kafka主题分区数 我们这里的注意事项对于即使做到配置flink数据源算子的并行度和kafka主题一样,但是有一些ka
EXPDP/IMPDP 中的并行度PARALLEL参数
如果设置 EXPDP parallel=4 必须要设置4个EXPDP文件,不然PARALLEL是有问题的,同时EXPDP会使用一个WORKER进程导出METADATA,其他WORKER进程会同时出数据。如果EXPDP作业低于250M,只会启动一个WORKER进程。如果是500M会启动2个,1000M及会启动4个WOKER进程。一般来说加上%U来设置多个文件。 而IMPDP