本文主要是介绍Flink并行度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
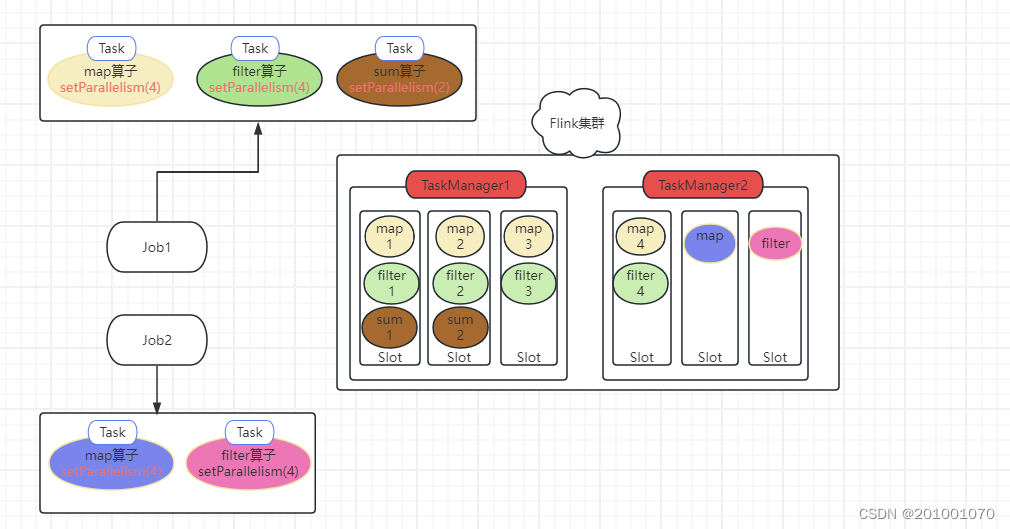
1、Task
flink中每个算子就是一个Task,比如flatMap、map、sum是一个Task。
2、SubTask
算子有几个并行度SubTask的数量就是几,比如
3、算子并行度
算子并行度指的是每个算子的并行度,可用env.setParallelism(1);设置所有算子的并行度,也可以对每个算子单独设置,通过降数据流划分为多个并行的算子实例(SubTask)可实现数据的并行处理。
一个Job的并行度是算子并行度的最大值,比如一个Job中有map算子并行度是2、filter算子并行度是4,则任务并行度就是4。
总结:Flink中,每一个算子都可以成为一个独立任务(task)。
这篇关于Flink并行度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






