本文主要是介绍二、Topology的并行度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、几个概念

Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程,这个工作进程就是worker。一个topology可能会在一个或者多个工作进程里面执行,每个工作进程执行整个topology的一部分。每一个worker都会占用工作节点的一个端口,这个端口可以在storm.yarm中配置。
每一个Spout和Bolt会被当作很多task在整个集群里面执行。默认情况下每一个task对应到一个线程(Executor),这个线程用来执行这个task。
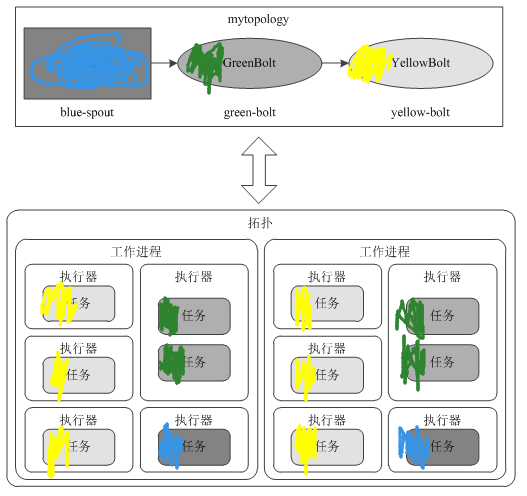
2、拓扑示例:
<span style="font-size:14px;">Config conf = new Config();
conf.setNumWorkers(2); // 使用两个工作进程topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // 设并行度为2,即2个Executor,每个executor下面有一个TasktopologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4) // 使用4个任务,每个Execotor执行2个Task.shuffleGrouping("blue-spout");topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)//并行度为6,有6个Executor.shuffleGrouping("green-bolt");StormSubmitter.submitTopology("mytopology",conf,topologyBuilder.createTopology()
);</span>该拓扑一共有两个工作进程(Worker),2+2+6=10个执行器(Executor),2+4+6=12个任务。因此,每个工作进程可以分配到10/2=5个执行器,12/2=6个任务
3、改变拓扑并行度
Storm一个很好的特性是,可以增加或减少工作进程(Worker)和/或执行器(Executor)的数量而不需要重新启动群集或拓扑,这样的行为被称为再平衡(rebalancing)。
有两种方式可实现拓扑再平衡:
(1)使用Storm Web UI。
(2) 使用CLI工具。
这篇关于二、Topology的并行度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!