本文主要是介绍storm(四) 并行度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概念
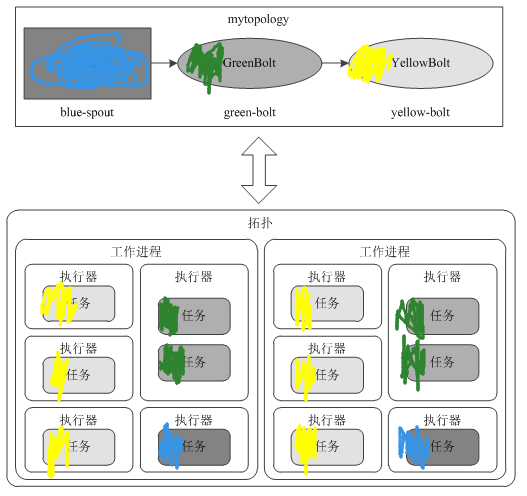
worker
- 一个实体机可以运行一个或者多个worker
- 一个worker只能运行一个topology上的部分或全部component
- 一个worker是一个独立的进程
- 在运行过程中可以调整worker的数量
executor
- 一个worker中可以运行多个executor
- 一个executor是一个线程
- 一个executor可以运行一个或者多个task,这些task必须是同一类型
- executor的数量<=task的数量
- 默认情况下一个executor中运行一个task
- executor的数量在topology的运行过程中可以动态调整,storm的并行度调整主要针对的就是executor
task
- 具体操作数据的bolt或者spout
- 在整个topology运行状态中,task的数量是固定的不能改变的
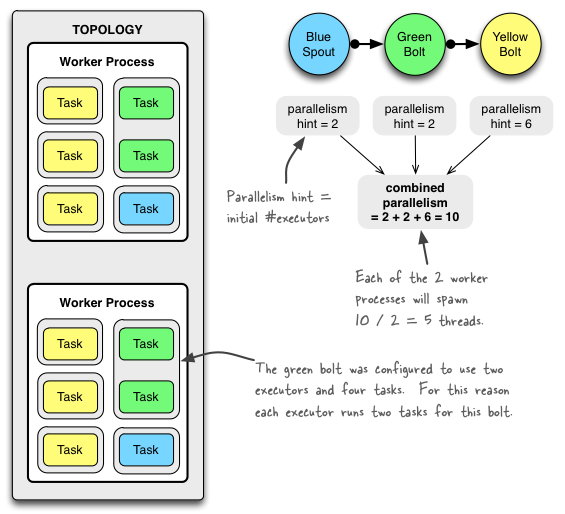
对于并行度的概念,最准确的还是要看官方的:http://storm.apache.org/releases/1.2.2/Understanding-the-parallelism-of-a-Storm-topology.html
并行度调整
调整并行度有几种方法,这里我选择的是直接在代码中进行设置
设置worker
- 关闭acker,将worker进程设置成2
- 由于现在有两个worker,两个executor(见下面截图),所以两个executor被平均分配给了两个worker,在我们这里就是一个生产一个消费(从打印的日志可以看出来)
Config config=new Config();
config.setNumWorkers(2);
config.setNumAckers(0);
StormSubmitter.submitTopology("SumTopology",config,topology);

设置executor
- 默认一个executor对应一个task,这里我设置executor的数量为3,所以task也为3
builder.setBolt("countNum",new SumBolt(),3).shuffleGrouping("createNum");

设置task
- 默认情况下一个executor下只有一个task,但是当设置的task的数量大于executor的时候,一个executor上就可能有多个task
builder.setSpout("createNum",new NumSpout());builder.setBolt("countNum",new SumBolt(),3).setNumTasks(6).shuffleGrouping("createNum");


设置acker
- 设置acker的方式在第一个例子中已经示范过,这里就不在演示了
- 不过一般并不建议将acker关闭,这样将无法保证数据的可靠性
动态设置并行度
- 这里我使用的是命令行的方式,至于storm ui的方式没搞懂
- 这里我将worker改成1个,createNum改为2个executor,countNum改为2个executor。注意这里没有调整task
- 所谓的并行调整其实就是重新分配:task所在的executor,executor所在的worker。task是真正做事的bolt、spout。所以如果task数量不够,即使将executor、worker的数量设置的再大也没有用
docker run --link nimbus:nimbus -it --rm storm
storm rebalance SumTopology -n 1 -e createNum=2 -e countNum=2
这篇关于storm(四) 并行度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!