后验专题

概率论(一)-概率论的基本概念:样本空间、随机事件、和事件、积事件、互斥事件、对立事件、频率、概率、加法定理、等可能概型、条件概率、乘法定理、全概率公式、贝叶斯公式、先验概率、后验概率、相互独立性
1 随机试验 2 样本空间、随机事件 3 频率与概率 4 等可能概型(古典概型) 5 条件概率 6 独立性


似然概率、先验概率、后验概率和边缘概率
似然概率、先验概率、后验概率和边缘概率是概率论和统计学中的几个重要概念,它们各自具有不同的定义和应用场景。 似然概率 似然概率(Likelihood Probability)或似然函数在统计学中是一种关于统计模型参数的函数。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率,即L(θ|x)=P(X=x|θ)。简单来说,似然概率就是当我们有一组数据x时,选择某
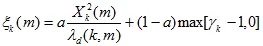
噪声抑制中先验信噪比与后验信噪比的关系
噪声抑制算法中,谱减算法用的是后验证信噪比,维纳滤波器使用的是先验信噪比,MMSE(最小均方误差)算法既用到了先验信噪比,也用到了后验信噪比,那么,自然提出一个问题,在降噪过程中,先验信噪比与后验信噪比到底那个作用比较大。这个结论其实通过验证可以得出,先验信噪比是影响噪声抑制的主要参数,后验信噪比是辅助参数。 那么先验信噪比与后验信噪比它们之间又有什么关系,

贝叶斯学习--极大后验假设学习
我们假定学习器考虑的是定义在实例空间X上的有限的假设空间H,任务是学习某个目标概念c:X→{0,1}。如通常那样,假定给予学习器某训练样例序列〈〈x1,d1,〉…〈xm,dm〉〉,其中xi为X中的某实例,di为xi的目标函数值(即di=c(xi))。为简化讨论,假定实例序列〈x1…xm〉是固定不变的,因此训练数据D可被简单地写作目标函数值序列:D=〈d1…dm〉。 基于贝叶斯理论我们可以设计一
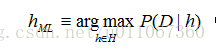
贝叶斯学习--极大后验概率假设和极大似然假设
在机器学习中,通常我们感兴趣的是在给定训练数据D时,确定假设空间H中的最佳假设。 所谓最佳假设,一种办法是把它定义为在给定数据D以及H中不同假设的先验概率的有关知识条件下的最可能(most probable)假设。 贝叶斯理论提供了计算这种可能性的一种直接的方法。更精确地讲,贝叶斯法则提供了一种计算假设概率的方法,它基于假设的先验概率、给定假设下观察到不同数据的概率、以及观察的数据本身。 要

先验概率、后验概率、似然函数的理解
注释:最近一直看到先验后验的说法,一直不懂,这次查了资料记录一下。 1.先验和后验的区别: A.简单的了解两个概率的含义 先验概率可理解为统计概率,后验概率可理解为条件概率。 ---------------------------------------------------------------------------------------------------------

贝叶斯公式中的先验概率、后验概率、似然概率
欢迎关注博主 Mindtechnist 或加入【智能科技社区】一起学习和分享Linux、C、C++、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。关注公粽号 《机器和智能》 回复关键词 “python项目实战” 即可获取美哆商城视频资源! 博主介绍: CSDN博客专家,CSDN优质创作者,CSD

贝叶斯公式(先验/后验概率)
转自https://www.cnblogs.com/yemanxiaozu/p/7680761.html 前言 以前在许学习贝叶斯方法的时候一直不得要领,什么先验概率,什么后验概率,完全是跟想象脱节的东西,今天在听喜马拉雅的音频的时候突然领悟到,贝叶斯老人家当时想到这么一种理论前提可能也是基于一种人的直觉. 先验概率:是指根据以往经验和分析得到的概率.[1] 意思是说我们人有
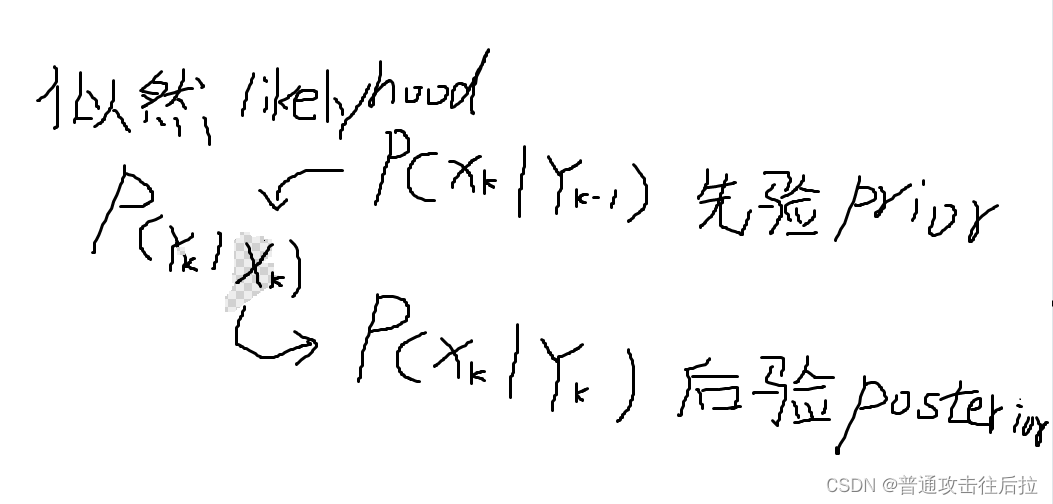
先验分布、后验分布、极大似然的一点思考
今天和组里同事聊天的时候,无意中提到了贝叶斯统计里先验分布、后验分布、以及极大似然估计这三个概念。同事专门研究如何利用条件概率做系统辨识的,给我画了一幅图印象非常深刻: 其中k表示时序关系。上面这个图表示后验分布是由先验分布与似然估计一同获得的。 我们经常在代码里给神经网络的最后一层的各个unit的概率值叫likelyhood,其实就是指在当前输入样本下输出各个logit的概率,其含义与极大似

数据评价方法:关联度检验/后验差检验/小误差频率
1.关联度检验 关联度检验可以这么理解:将得到的数据和一个“标准数据”进行比对,得出对应的关联度,关联度最大的数据(即和“标准数据”最“接近”的数据)是最优的数据(直观理解就是,班级里面有一个同学最优秀,拿全班同学和ta比较,认为最接近ta的就是最优秀的)。 关联度检验的流程: 举例说明,现在有一组原始数据x0=[1,2,5,7,9],对它按时间[1,2,3,4,5]分别进行灰色预测、一次拟合
先验概率、后验概率、最大似然估计(MLE)
本文假设大家都知道什么叫条件概率了(P(A|B)表示在B事件发生的情况下,A事件发生的概率)。 先验概率和后验概率 教科书上的解释总是太绕了。其实举个例子大家就明白这两个东西了。 假设我们出门堵车的可能因素有两个(就是假设而已,别当真):车辆太多和交通事故。 堵车的概率就是先验概率 。 那么如果我们出门之前我们听到新闻说今天路上出了个交通事故,那么我们想算一下堵车的概率,这个就叫
先验概率 后验概率 似然 极大似然估计 极大后验估计 共轭 概念
http://blog.csdn.net/hxxiaopei/article/details/8034184 最近在看LDA,里面涉及到 狄利克雷的概念,为了把这个事情搞明白,查了一些相关概率知识, 举个例子,掷硬币,伯努利实验 中随机变量x={正面,背面},正面的概率μ为模型参数,假定做了N次试验,Data 中观察序列为X={正面,正面。。。。反面},正面的次数为k,服从二项分布:p(

高斯噪声和泊松噪声的最大后验模型去噪
文章目录 1. 高斯噪声的最大后验去噪模型1.1 退化模型1.2 最大后验建模 2.泊松噪声的最大后验去噪模型 1. 高斯噪声的最大后验去噪模型 1.1 退化模型 高斯噪声的数学模型如(1)式所示 y = x + n (1) y=x+n \tag{1} y=x+n(1) 其中 y y y是噪声图像, x x x是清晰图像, n n n为加性高斯噪声服从独立同分布(i.i.
先验概率、最大释然估计(MLE)与最大后验估计(MAP)
前言 在数据分析和机器学习中,估计是一个很重要的内容,这里着重介绍下极大似然估计与极大后验估计。 最大似然估计(MLE) 最大似然估计是模型已定,参数未定时的一种估计方法。比如说对于抛硬币而言,模型已定,可以看做是多个伯努利实验,我们所不知道的是这个硬币正面朝上的概率 p p,所以我们的任务就是估计pp的值。极大似然估计的思想是,对于已经给定的一些观测数据,参数 p p的取值应使得取
什么是先验知识和后验知识
在概率论和统计学中,先验知识(Prior knowledge)和后验知识(Posterior knowledge)是贝叶斯推断的两个基本概念。 先验知识(先验概率): 先验知识指的是在观察到数据之前,关于一个不确定参数的知识或者信念。这通常是通过先验概率分布来表达的,它代表了在考虑任何具体数据之前,我们对参数可能值的信念。先验知识可以来自以往的研究、专家的经验、历史数据等,也可以是主观的判断。

SegNet 语义分割网络以及其变体 基于贝叶斯后验推断的 SegNet
HomePage: http://mi.eng.cam.ac.uk/projects/segnet/ SegNet Paper: https://www.computer.org/csdl/trans/tp/2017/12/07803544.html Dropout as Bayesian Paper: http://mlg.eng.cam.ac.uk/yarin/PDFs/NIPS_201
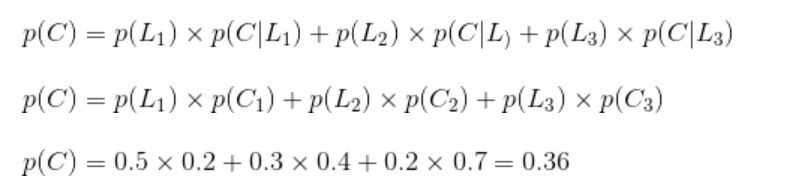
条件概率、全概率、先验概率、后验概率
** 前言 ** 条件概率,全概率,先验概率,后验概率这么多的定义,以前是几乎遇见一次都要百度一次,一看就会,然而没有做好总结下一次还是会忘掉,好记性终究敌不过烂笔头,这次做个总结,一劳永逸,个人愚见,请大家不吝赐教。 ** 1.条件概率 ** 首先上定义 :设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率为: P(A|B)=P(AB)/P(B)
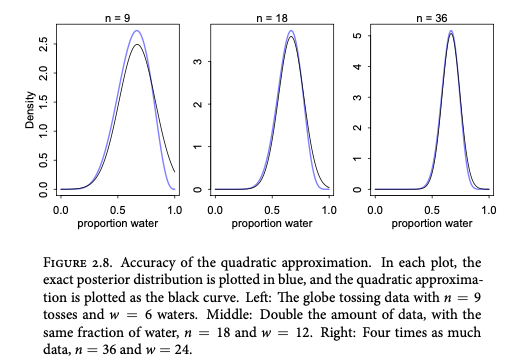
贝叶斯建模:从先验合理性到后验分布
一、说明 本文探讨贝叶斯模型,首先用摸球游戏展开模型构建步骤,然后讨论分类算法,以及实际操作方法:网格法、二次近似、蒙特卡洛。 二、针对贝叶斯的模型构建 2.1 分支剪枝和假设 在贝叶斯分析中,我们可以将这个过程想象成照料一个充满数据分支路径的花园。这个花园代表了我们考虑的不同可能性或事件顺序。每条路径代表对观察到的数据
![[work] 拟合目标函数后验分布的调参利器:贝叶斯优化](https://image.jiqizhixin.com/uploads/wangeditor/55d7a03d-7196-4bcb-ae18-4fae4df67615/72307image%20%2819%29.png)
[work] 拟合目标函数后验分布的调参利器:贝叶斯优化
如何优化机器学习的超参数一直是一个难题,我们在模型训练中经常需要花费大量的精力来调节超参数而获得更好的性能。因此,贝叶斯优化利用先验知识逼近未知目标函数的后验分布从而调节超参数就变得十分重要了。本文简单介绍了贝叶斯优化的基本思想和概念,更详细的推导可查看文末提供的论文。 超参数 超参数是指模型在训练过程中并不能直接从数据学到的参数。比如说随机梯度下降算法中的学习速率,出于计算复杂度和算法

先验概率、似然函数、后验概率、贝叶斯公式
转自:http://www.sigvc.org/why/book/3dp/chap10.8.1.htm 联合概率的乘法公式: (如果随机变量是独立的,则) 由乘法公式可得条件概率公式:, 全概率公式:,其中 (,则可轻易推导出上式) 贝叶斯公式: 又名后验概率公式、逆概率公式:后验概率=似然函数×先验概率/证据因子。解释如下,假设我们根据“手臂是否很长”这个随机
先验概率、后验概率、似然函数
直接看我这篇文章更清楚 搬运了网页各处的解释,有点意思 一、先验概率 先验概率(prior probability)是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现的概率· 中文名 先验概率 外文名 prior probability 分 类 客观先验概率,主观先验概率 释 义 根据以往经验和分析得到的概率 又
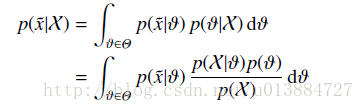
经验风险最小化、结构风险最小化、极大似然估计、最大后验概率估计...||《统计学习方法》李航_第1章_蓝皮(学习笔记)
第1章 统计学习方法概论 监督学习统计学习三要素模型策略(经验风险和结构经验风险) 判别模型与生成模型补充(含课后作业)MLE、MAP和贝叶斯估计证明经验风险最小化等价于极大似然估计(在特定条件下)证明结构风险最小化与最大后验概率等价(在特定条件下)贝叶斯估计 挑重点记录一下。 监督学习 监督学习有一个重要的假设:设输入的随机变量 X X X和 Y Y Y遵循联合概率分布 P