本文主要是介绍SegNet 语义分割网络以及其变体 基于贝叶斯后验推断的 SegNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HomePage: http://mi.eng.cam.ac.uk/projects/segnet/
SegNet Paper: https://www.computer.org/csdl/trans/tp/2017/12/07803544.html
Dropout as Bayesian Paper: http://mlg.eng.cam.ac.uk/yarin/PDFs/NIPS_2015_deep_learning_uncertainty.pdf
首先看一下Fate_fjh博主亲自测试的实验结果:

(Fate_fjh测试结果)
SegNet基于FCN,修改VGG-16网络得到的语义分割网络,有两种SegNet,分别为正常版与贝叶斯版,同时SegNet作者根据网络的深度提供了一个basic版(浅网络)。
1. SegNet原始网络模型
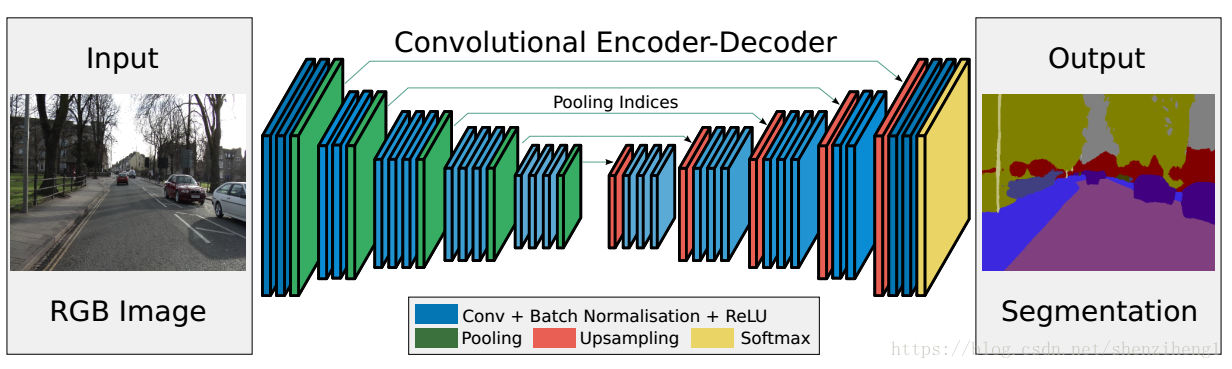
图一:SegNet网络模型
SegNet网络结构如上所示,Input为输入图片,Output为输出分割的语义图像,不同颜色代表不同的分类。语义分割的重要性就在于不仅告诉你图片中某个东西是什么,而且告知它在图片的位置。SegNet是一个对称网络,由中间绿色pooling层与红色upsampling层作为分割,左边是卷积提取高维特征,并通过pooling使图片变小,SegNet作者称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与upsampling,通过反卷积使得图像分类后特征得以重现,upsampling使图像变大,SegNet作者称为Decoder,最后通过Softmax,输出不同分类的最大值,这就是大致的SegNet过程。
1.1 关于卷积
SegNet的Encoder过程中,卷积的作用是提取特征,SegNet使用的卷积为same卷积,即卷积后不改变图片大小;在Decoder过程中,同样使用same卷积,不过卷积的作用是为upsampling变大的图像丰富信息,使得在Pooling过程丢失的信息可以通过学习在Decoder得到。SegNet中的卷积与传统CNN的卷积并没有区别。
1.2 关于批量归一化
批标准化的主要作用在于加快学习速度,用于激活函数前,在SegNet中每个卷积层都会加上一个bn层,bn层后面为ReLU激活层,bn层的作用过程可以归纳为:
(1)训练时:
1.向前传播,bn层对卷积后的特征值(权值)进行标准化,但是输出不变,即bn层只保存输入权值的均值与方差,权值输出回到卷积层时仍然是当初卷积后的权值。
2.向后传播,根据bn层中的均值与方差,结合每个卷积层与ReLU层进行链式求导,求得梯度从而计算出当前的学习速率。
(2)测试时:每个bn层对训练集中的所有数据,求取总体的均值与方差,假设有一测试图像进入bn层,需要统计输入权值的均值与方差,然后根据训练集中整体的无偏估计计算bn层的输出。注意,测试时,bn层已经改变卷积的权值,所以激活层ReLU的输入也被改变。
1.3 关于下采样与上采样的巧妙设计
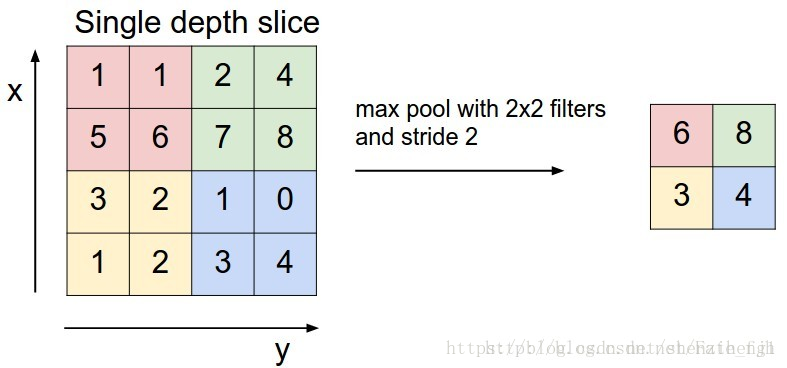
图二: 2x2-最大池化原理
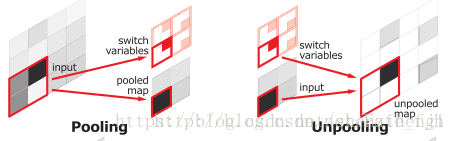
图三: SegNet中基于索引的下采样与上采样的实现
在SegNet中的Pooling与其他Pooling多了一个index功能,也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,对于图二的6来说,6在粉色2x2 filter中的位置为(1,1),黄色的3的index为(0,0)。同时,从图一可以看到绿色的pooling与红色的upsampling通过pool indices相连,实际上是pooling后的indices输出到对应的upsampling。
Upsamping就是Pooling的逆过程,Upsamping使得图片变大2倍。我们清楚的知道Pooling之后,每个filter会丢失了3个权重,这些权重是无法复原的,但是在Upsamping层中可以得到在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入,如图三所示,Unpooling对应上述的Upsampling,switch variables对应Pooling indices。
从图三中右边的Upsampling可以知道,2x2的输入,变成4x4的图,但是除了被记住位置的Pooling indices,其他位置的权值为0,因为数据已经被pooling掉了。因此,SegNet使用的反卷积在这里用于填充缺失的内容(可以理解为解码过程学习金标准信息),所以在图一中跟随Upsampling层后面的是也是卷积层。
1.4 关于Softmax分类
SegNet最后一个卷积层会输出所有的类别。网络最后连接一个softmax层,由于是end to end, 所以softmax需要求出所有每一个像素在所有类别最大的概率,最为该像素的label,最终完成图像像素级别的分类。
可以看一下作者得到的实验结果:

1.5 讨论Relu的应用效益
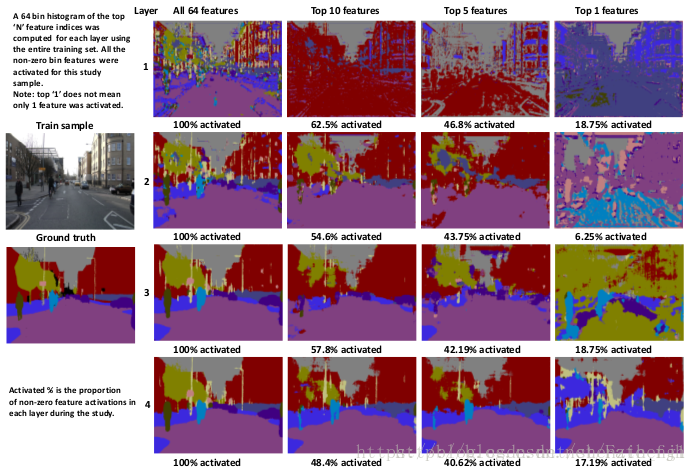
在传统的CNN网络中,ReLU通常在全连接之后,结合偏置bias用于计算权值的输出,但是在Seg Net作者的研究中发现,激活层越多越有利于图像语义分割。上图为论文中,不同深度的卷积层增加与不增加激活函数的对比图。
2. Bayesian SegNet
2.1 SegNet存在的一个问题
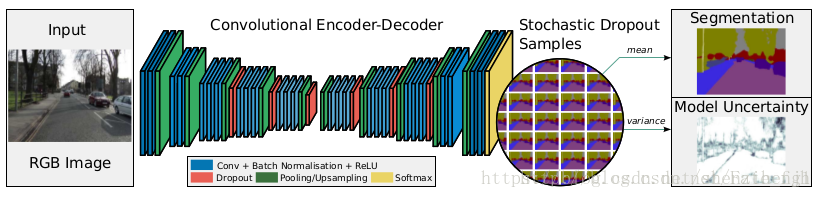
图四 Bayesian SegNet 网络模型
对比图一与图四,并没有发现Bayesian SegNet与SegNet的差别,事实上,从网络变化的角度看,Bayesian SegNet只是在卷积层中多加了一个DropOut层。最右边的两个图Segmentation与Model Uncertainty,就是像素点语义分割输出与其不确定度(颜色越深代表不确定性越大,即置信度越低)。
2.1 关于DropOut as Bayesian approximation
在传统神经网络中DropOut层的主要作用是防止权值过度拟合,增强学习能力。DropOut层的原理是,输入经过DropOut层之后,随机使部分神经元不工作(权值为0),即只激活部分神经元,结果是这次迭代的向前和向后传播只有部分权值得到学习,即改变权值。
因此,DropOut层服从二项分布,结果不是0,就是1,在CNN中可以设定其为0或1的概率来到达每次只让百分之几的神经元参与训练或者测试。在Bayesian SegNet中,SegNet作者把概率设置为0.5,即每次只有一半的神经元在工作。因为每次只训练部分权值,可以很清楚地知道,DropOut层会导致学习速度减慢。
在Bayesian SegNet中通过DropOut层实现多次采样,多次采样的样本值为最后输出,方差为其不确定度,方差越大不确定度越大,如图四所示,mean为图像语义分割结果,var为不确定大小。所以在使用Bayesian SegNet预测时,需要多次向前传播采样才能够得到关于分类不确定度的灰度图,Bayesian SegNet预测如图六所示。

图六 Bayesian SegNet 测试结果
这篇关于SegNet 语义分割网络以及其变体 基于贝叶斯后验推断的 SegNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







