本文主要是介绍先验分布、后验分布、极大似然的一点思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天和组里同事聊天的时候,无意中提到了贝叶斯统计里先验分布、后验分布、以及极大似然估计这三个概念。同事专门研究如何利用条件概率做系统辨识的,给我画了一幅图印象非常深刻:
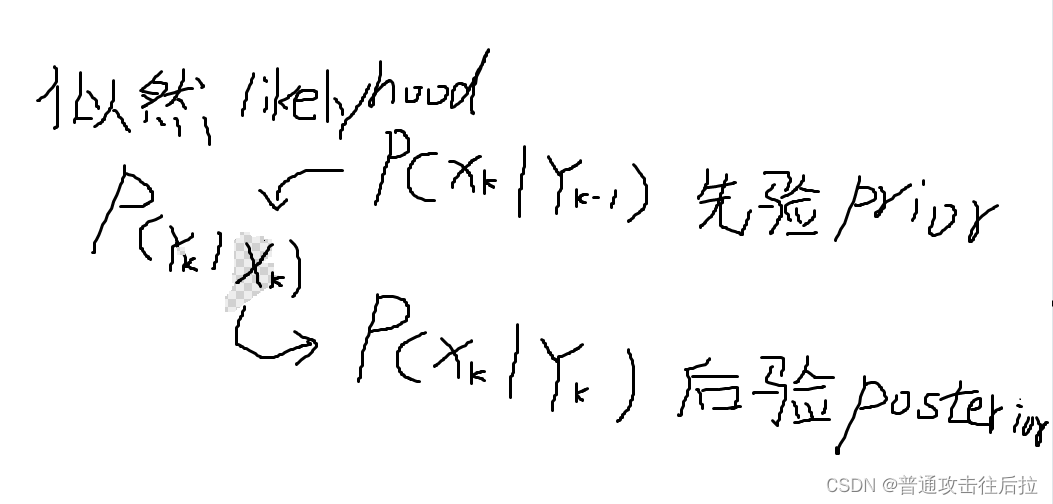
其中k表示时序关系。上面这个图表示后验分布是由先验分布与似然估计一同获得的。
我们经常在代码里给神经网络的最后一层的各个unit的概率值叫likelyhood,其实就是指在当前输入样本下输出各个logit的概率,其含义与极大似然估计是一样的。
后验分布:由果推因
先验分布:由历史推因
所以深度学习中常见的训练过程其实就是求参数的先验分布的过程,模型里的权重和偏差参数就是‘因’,输出就是‘果’。贝叶斯神经网络一般用的都是后验分布。
这篇关于先验分布、后验分布、极大似然的一点思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







