分布专题

全英文地图/天地图和谷歌瓦片地图杂交/设备分布和轨迹回放/无需翻墙离线使用
一、前言说明 随着风云局势的剧烈变化,对我们搞软件开发的人员来说,影响也是越发明显,比如之前对美对欧的软件居多,现在慢慢的变成了对大鹅和中东以及非洲的居多,这两年明显问有没有俄语或者阿拉伯语的输入法的增多,这要是放在2019年以前,一年也遇不到一个人问这种需求场景的。 地图应用这块也是,之前的应用主要在国内,现在慢慢的多了一些外国的应用场景,这就遇到一个大问题,我们平时主要开发用的都是国内的地
![【Get深一度】谐振腔中的电场(E Field[V_per_m])与磁场(H field[A_per_m])分布](https://img-blog.csdn.net/20160809155646491?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
【Get深一度】谐振腔中的电场(E Field[V_per_m])与磁场(H field[A_per_m])分布
1.模式1[TM010模]的电场和磁场分布 模式1在腔体横截面(XY)上的电磁场分布
![[转载]t检验、t分布、t值](https://i-blog.csdnimg.cn/blog_migrate/c1fa9d8d3316d59ae97557381a197894.png)
[转载]t检验、t分布、t值
1. t检验的历史 阿瑟·健力士公司(Arthur Guinness Son Co.)是一家由阿瑟·健力士(Arthur Guinness)于1759年在爱尔兰都柏林建立的一家酿酒公司: 不过它最出名的却不是啤酒,而是《吉尼斯世界纪录大全》: 1951年11月10日,健力士酒厂的董事休·比佛爵士(Sir Hugh Beaver)在爱尔兰韦克斯福德郡打猎时,因为没打中金鸻,于

开绕组永磁电机驱动系统零序电流抑制策略研究(7)——基于零矢量重新分布的120°矢量解耦/中间六边形调制零序电流抑制策略
1.前言 很久没有更新过开绕组电机的仿真了。在一年前发了开绕组的各种调制策略。开绕组电机最常见的两种解耦调制就是120°矢量解耦/中间六边形调制和180°矢量解耦/最大六边形调制。 我当时想的是,180°解耦调制/最大六边形调制的电压利用率最高,所以我就一直用这个调制方式。但是近年来做开绕组电机的基本都是华科的老师,而他们都采用了120°调制/中间六边形调制。 我之前是做了120°解耦调
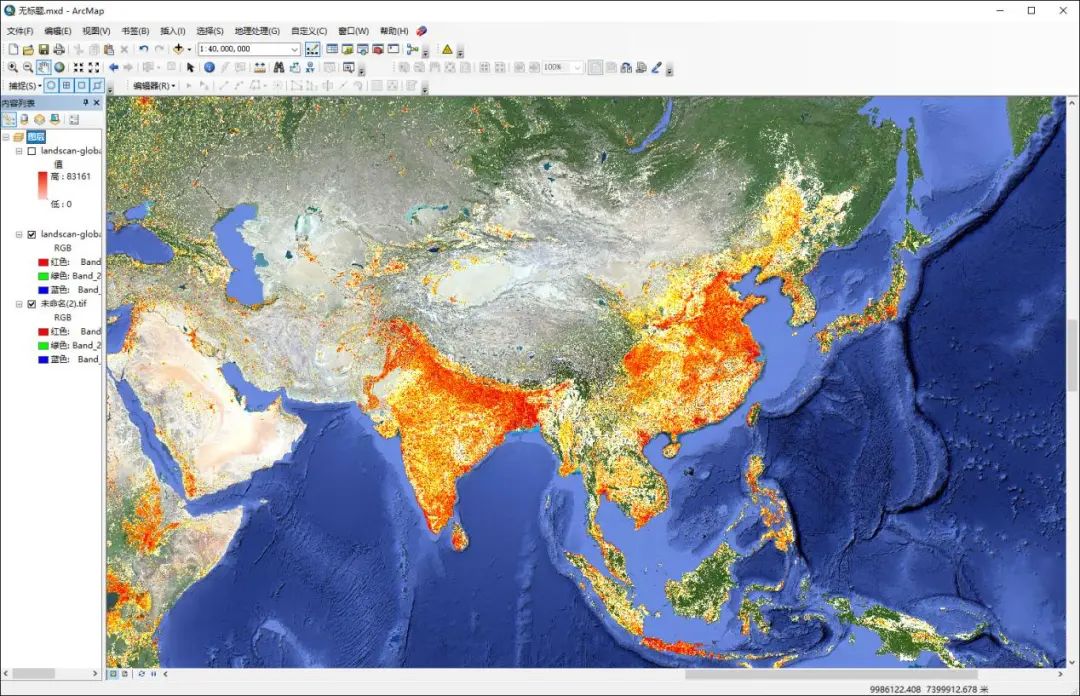
全球1km分辨率人口分布栅格数据
我们在《全国省市县三级“七普”人口数据分享》一文中,为你分享过全国人口数据。 现在再为你分享全球1km分辨率人口分布栅格数据,你可以在文末查看该数据的领取方法。 全球1km分辨率人口分布 人口空间分布数据是在各项研究中经常使用的数据,它在人口分布模拟、环境评估、城市规划等领域具有重要的作用。 我国县级人口分布密度示意 现在给你分享的全球1km分辨率人口分布栅格数据,来源于Land

概率论(三)-多维随机变量及其分布:n维随机变量、概率分布函数F(x1,x2,..xn)、联合分布律、联合概率密度、边缘分布律、边缘概率密度、条件分布律、条件概率密度、β函数、Γ函数、max{X,Y}
1 二维随机变量 2 边缘分布 3 条件分布 4 相互独立的随机变量 5 两个随机变量的函数的分布
概率论(二)-随机变量及其分布:分布函数F(x)、离散型随机变量【分布律:(0-1)分布、二项分布、泊松分布】、连续型随机变量【概率密度:均匀分布、指数分布、正态/高斯分布】、3σ法则、偏度、峰度
1 随机变量 2 离散型随机变量及其分布律 3 随机变量的分布函数 4 连续型随机变量及其概率密度 5 随机变量的函数的分布

2019年Android版本分布(市场占有率、市场份额)统计
分发仪表板 此页面提供有关共享特定特征的设备的相对数量的信息,例如Android版本或屏幕大小。每个数据快照代表过去7天内访问过Google Play商店的所有设备。通过显示Android和Google Play生态系统中哪些设备处于活动状态,信息此柯林斯帮助您确定请立即获取iTunes不同设备的工作的优先顺序。 如果您想想查看用户运行应用的设备的信息,您可以使用Google Play控制台。

【译】PCL官网教程翻译(22):全局对齐空间分布(GASD)描述符 - Globally Aligned Spatial Distribution (GASD) descriptors
英文原文查看 全局对齐空间分布(GASD)描述符 本文描述了全局对齐的空间分布(GASD)全局描述符,用于有效的目标识别和姿态估计。 GASD基于表示对象实例的整个点云的参考系的估计,该实例用于将其与正则坐标系对齐。然后,根据对齐后的点云的三维点在空间上的分布情况计算其描述符。这种描述符还可以扩展到整个对齐点云的颜色分布。将匹配点云的全局对齐变换用于目标姿态的计算。更多信息请参见GASD。

【Python机器学习】NLP词频背后的含义——隐性狄利克雷分布(LDiA)
目录 LDiA思想 基于LDiA主题模型的短消息语义分析 LDiA+LDA=垃圾消息过滤器 更公平的对比:32个LDiA主题 对于大多数主题建模、语义搜索或基于内容的推荐引擎来说,LSA应该是首选方法。它的数学机理直观、有效,它会产生一个线性变换,可以应用于新来的自然语言文本而不需要训练过程,并几乎不会损失精确率。但是,在某些情况下,LDiA可以给出稍好的结果。 LDiA和LS

基于Leaflet Legend的图例数据筛选实践-以某市教培时空分布为例
目录 前言 一、关于Leaflet.Legend组件 1、Legend组件的主要参数 2、相关参数 二、Legend图例可视化控制 1、违规教培信息的管理 2、违规培训信息时空可视化及图例渲染控制 3、成果展示 三、总结 前言 在很多的地理时空分析系统中,我们经常会遇到一些需求。比如在地图中,我们会结合内容的分类来进行图例的展示,而图例不仅

【C/C++】C语言中的内存分布
在C语言中,内存分布主要可以分为以下几个区域: 栈(Stack):由编译器自动分配和释放,存放函数的参数值、局部变量的值等。 堆(Heap):一般由程序员分配和释放,若未释放,程序结束时由操作系统回收。 全局区(静态区)(Static):存放全局变量、静态变量和常量。 文字常量区:存放常量字符串。程序结束后由系统释放。 程序代码区:存放程序的二进制代码。 下面是一个简单的例子,展示了这些区域的基
生成一个给定的度分布的图
生成一个给定的度分布的图 参考文献:《Efficient and Simple Generation of Random Simple Connected Graphs with Prescribed Degree Sequence》2006 这篇文章讲的是如何快速生成一个满足指定度分布的图,并不包含具体完整的算法,只能做引用文献使用,另外,文章引用部分给定了代码网址,只可惜现在无法访问了。

Hadoop详解(五)——ZooKeeper详解,ZooKeeper伪分布搭建和集群搭建,Hadoop集群搭建,sqoop工具的使用
ZooKeeper简介 什么是ZooKeeper? ZooKeeper是Google的Chubby一个开源的实现,是Hadoop分布式协调服务。 它包含了一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命令服务等。 它的结构图如下: ZooKeeper集群搭建的要求:必须要有奇数台。如果想让ZooKeeper既具有高效性,又能正常工作,只要

使用颜色分布法计算图像相似度
基于比较灰度直方图的方法计算两幅图像相似度误判较多,一个原因上篇博客已经提到,就是直方图自身局限性: 仅反映图像像素各灰度值的数量,不能反映图像纹理结构;另一个原因就是在使用该方法时,对于彩色图像,一般都是将其转为灰度图像,然后在计算其灰度直方图,最后再参与运算比较,很明显在彩色转灰度的转换过程中将损失图像颜色信息,所以在计算时存在大量误判。由第一个原因产生的误判很难找到解决方案,
NumPyro入门API和开发人员参考 pyro分布推理效果处理程序贡献代码更改日志入门教程使用NumPyro的贝叶斯回归贝叶斯分层线性回归例
NumPyro文档¶ NumPyro入门 API和开发人员参考 烟火元素分布推理效果处理程序贡献代码更改日志 入门教程 使用NumPyro的贝叶斯回归 贝叶斯分层线性回归 例如:棒球击球率 示例:变型自动编码器 例子:尼尔的漏斗 例子:随机波动 例如:亚麻和俳句 可变推断参数化 NumPyro模型的自动绘制



【架构系列】分布式微服务架构设计原理
我们先来张宏观的导图来看看分布式微服务设计架构的原理都有些什么?然后再详细介绍一下。 微服务的演变历史 在了解分布式微服务架构设计原理之前,我们首先应该知道什么是微服务,以及微服务是如何发展而来的。 单体架构——》服务化——》微服务 1、单体架构 JEE架构 早期的企业级软件架构为JEE架构,它将企业软件划分为三个层次:web层(web容器),业务逻辑层(EJB组件),数据存取层(
项目技术总结三之分布与集群的区别
这次在旁听技术分享的时候自己当时提了一个问题就是分布式的方式,但是当时我回答的不是分布式而是集群的联系,所以我在分享交流会以后就查阅了有关这方面的资料,那小编今天就来跟大家分享一下分布集群那些事儿! 分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率,拿一个高中学过的电路知识来说就是分布式是并联完成任务,而集群是串联完成任务

【流体力学】第二章 流体静力学,流体静压强及其特性,静止流体内压强分布,作用在平面和曲面上的流体压力(西北工业大学)
目录 第二章 流体静力学 2.1 流体静压强及其特性 一、基本概念 1.静压强 二、静压强的特性 2.2 静止流体平衡微分方程式编辑 二、 平衡微分方程的积分 三、 等压面 2.3 重力场中静止流体内的压强分布 三. 位置水头、压强水头、测压管水头 四. 压强的度量单位 2.4 压强测量 一. 绝对压强、相对压强、真空 二. 测压原理 U形测压管

概率统计Python计算:连续型随机变量分布(norm)
scipy.stats的norm对象表示正态分布,下表说明norm的几个常用函数。 函数名参数功能rvs(loc, scale, size)loc,scale:分布参数 μ \mu μ和 σ \sigma σ,缺省值分别为0和1,size:产生的随机数个数,缺省值为1产生size个随机数pdf(x, loc, scale)x:自变量取值,loc,scale:与上同概率密度函数 f ( x )

概率统计Python计算:连续型随机变量分布(uniform expon)
1. uniform分布(均匀分布) Python的scipy.stats包中的对象uniform表示连续型的均匀分布。下表展示了uniform分布的几个常用函数。 函数名参数功能rvs(loc, scale, size)loc:分布参数 a a a,缺省值为0, scale:分布参数差 b − a b-a b−a,缺省值为1,size:产生的随机数个数,缺省值为1产生size个随机数pd

概率统计Python计算:离散型随机变量分布(bernoulli geom)
Python的scipy.stats包中提供了各种随机变量的分布。每一种分布,其累积分布函数(分布函数)记为cdf。离散型变量分布的概率质量函数(分布律),记为pmf。除此之外,每个分布都有一个服从该分部变量发生器函数rvs,用来产生服从该分布的随机数。 1. bernoulli分布(0-1分布) Python的scipy.stats包中,bernoulli类就是用来表示伯努利分布的。常用的

概率统计Python计算:随机变量的分布函数
任何随机变量 X X X都有其分布函数(或称为累积分布函数) F ( x ) = P ( X ≤ x ) , x ∈ ( − ∞ , + ∞ ) . F(x)=P(X\leq x), x\in (-\infty,+\infty). F(x)=P(X≤x),x∈(−∞,+∞). 例1 向半径为 r r r的圆内任一投掷一个点,求此点到圆心的距离 X X X的分布函数,并计算 P ( X > r

概率统计Python计算:连续型自定义分布数学期望的计算(一)
对自定义的连续型随机变量 X X X,设其概率密度函数为 f ( x ) f(x) f(x),我们可以定义一个概率密度为 f ( x ) f(x) f(x)的rv_continuos的子类(详见博文《自定义连续型分布》)然后调用该子类对象的expect函数计算指定函数 g ( X ) g(X) g(X)的数学期望 E ( g ( X ) ) E(g(X)) E(g(X))。 例1 设在某一规定的