全表专题

11GR2下基于CBO全表扫描cost计算
########################################################## ##11gr2下基于cbo优化器,在不做系统统计信息收集下全表扫描的成本计算#### ########################################################## CBO的成本计算设计到非工作负载下的系统统计信息 CPUSPEEDNW=>系统

用合适的索引避免不必要的全表扫描
Oracle 数据库里大部分SQL优化的问题都可以增加或减少索引的方式来解决,但这绝不是全部。当目标SQL语句所要查询的只是目标表中的一部分数据时,通过创建合 适的索引就能够避免在没有索引的情况下为查询这一小部分数据而不得不采用全表扫描的操作,这样就降低了目标SQL语句的资源消耗,同时也会缩短了执行时 间。创建一张测试表及创建一个普通的单键值B树索引: 复制代码 复制代码 SQL> c

MySQL 全表扫描
Server层 -- db1.t有200GBmysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file 查询数据 InnoDB的数据是保存在主键索引上,全表扫描实际上是直接扫描表t的主键索引获取一行,写到net_buffer中,默认为16K,控制参数为net_buffer_length重复获

程序员面试之MySQL索引失效,索引失效的原因可能有多种,表数据量过大,当表中的数据量过大时,即使有合适的索引,MySQL仍可能选择全表扫描的方式进行查询,从而导致索引失效,实际情况还可能有其他因素
AI:please wait… MySQL索引失效的原因可能有多种,以下是一些常见的原因: 索引选择性不好:索引的选择性是指索引中不同值的个数与表中记录数的比值。如果索引选择性较差,即不同值较少,那么使用该索引进行查询可能会导致大量的数据读取,进而导致索引失效。索引列类型不匹配:如果索引列的数据类型与查询条件中的数据类型不匹配,那么MySQL可能无法使用该索引进行查询,从而导致索引失效。表数据量

Oracle count的优化-避免全表扫描
Oracle count的优化-避免全表扫描 select count(*) from t1; 这句话比较简单,但很有玄机!对这句话运行的理解,反映了你对数据库的理解深度! 建立实验的大表他t1 SQL> conn scott/tiger 已连接。 SQL> drop table t1 purge; 表已删除。 SQL> create table t1 as select * fro

你写的每条SQL都是全表扫描吗
你写的每条SQL都是全表扫描吗?如果是,那MySQL可太感谢你了,每一次SQL执行都是在给MySQL上压力、上对抗。MySQL有苦难言:你不知道索引吗?你写的SQL索引都失效了不知道吗?慢查询不懂啊?建那么多索引干嘛呢。。。 文章目录 1. 慢查询2. SQL优化2.1 表设计优化2.2 SQL语句优化2.3 索引如何设计 未完待续。。。 1. 慢查询 面试官:知道My

MYSQL性能调优03_在什么情况下会导致索引失效从而进行全表扫描
口诀: (1). 值匹配我最爱,最左前缀要遵守 (2). 带头大哥不能死,中间兄弟不能断 文章目录 ①. 建表语句、建立环境②. 全值匹配我最爱③. 最左前缀法则③. 不在索引列上做任何操作④. 存储引擎不能使用索引中范围条件右边的列⑤. 尽量使用覆盖索引、减少select *⑥. mysql在使用不等于(!=或者<>)⑦. is null,is not null 一般情况下也无法使

Oracle 数据库 count的优化-避免全表扫描
Oracle 数据库 count的优化-避免全表扫描 select count(*) from t1; 这句话比较简单,但很有玄机!对这句话运行的理解,反映了你对数据库的理解深度! 建立实验的大表他t1 SQL> conn scott/tiger 已连接。 SQL> drop table t1 purge; 表已删除。 SQL> create table t1 as select * f

在Oracle中如何使用索引快速扫描优化全表扫描
在Oracle数据库中,索引快速扫描(Index Fast Full Scan,简称IFFS)是对索引进行类似全表扫描的操作,它主要用来加速那些需要访问大量数据并且这些数据可以通过索引有效地获取的情况。以下是如何在特定场景下使用索引快速扫描优化全表扫描的策略: 索引覆盖查询: 如果查询所需要的列都包含在某个索引中(即索引覆盖查询),那么可以尝试通过创建一个包含所有查询列的复合索引,并确保查询仅

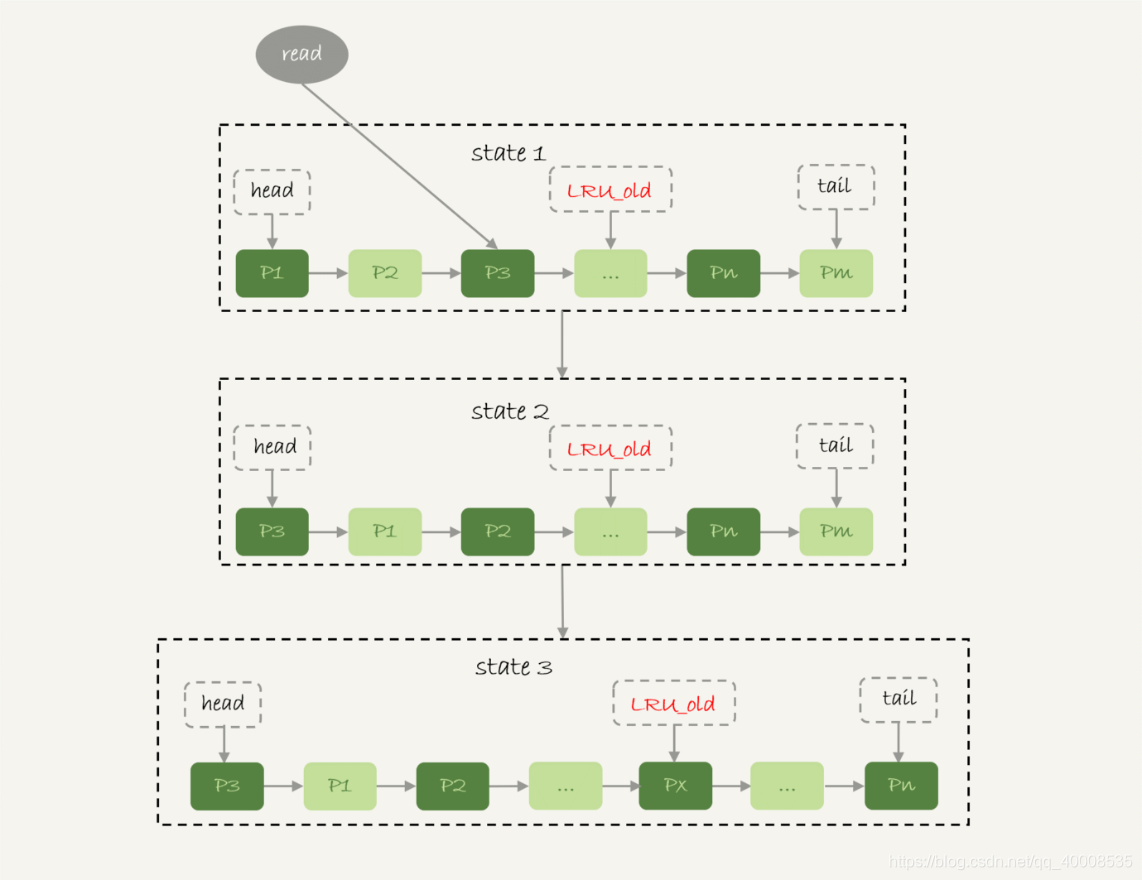
MySQL-32:全表扫描
全表扫描的概念: 数据库服务器用来搜寻表的每一条记录的过程,直到所有符合给定条件的记录返回为止。 32.1 全表扫描流程 例如,我们执行如下sql,对表t进行全表扫描,这条sql的目的就是将全表的结果发送给客户端。 select * from t 流程如下: 服务端内存中有个net_buffer,大小由参数net_buffer_length控制,默认大小为16K。读取一行,写入net_
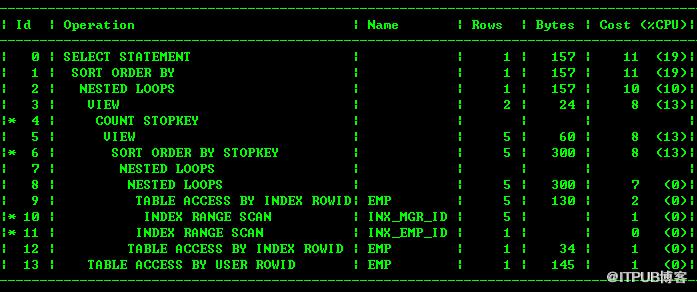
oracle全表扫描优化,优化Oracle with全表扫描的问题(二)
http://blog.itpub.net/29254281/viewspace-1242731/ 尽信书不如无书 Oracle的优化器也不是万能的。 还是上次的SQL,开发说有时候执行时间超过3s。 我又查了查执行计划,发现有全表扫描和索引快速全扫描。这个是不符合预期的。 抽象问题如下: create tableempas select * fromhr.employees; create i
【转】 【概念】为什么有时全表扫描比通过索引扫描效率更高
【概念】为什么有时全表扫描比通过索引扫描效率更高 http://space.itpub.net/519536/viewspace-612715 伟大的Oracle SQL优化器可以判断出在某些情况下,使用全表扫描比使用索引扫描能更快的得到数据结果。有没有想过,她是怎么做到的呢?背后的原理是什么呢?举一个非常好理解的场景(scenario:通过索引读取表中20%的数据)解释一下这个有趣的概

MySQL全表扫描:性能杀手的隐患与优化策略
MySQL全表扫描:性能杀手的隐患与优化策略 MySQL数据库作为常用的关系型数据库管理系统之一,全表扫描问题一直困扰着开发者。本文将深入剖析MySQL全表扫描的原理、其对性能的严重影响,同时提供一系列优化策略,助您高效应对MySQL性能杀手。 MySQL全表扫描的原理 MySQL全表扫描是指数据库在执行查询操作时,需要逐行遍历表中的记录,进行过滤和匹配,直到找到满足查询条件的

面试题:SELECT COUNT(*) 会造成全表扫描吗 ?
文章目录 前言SQL 选用索引的执行成本如何计算实例说明总结 前言 SELECT COUNT(*)会不会导致全表扫描引起慢查询呢? SELECT COUNT(*) FROM SomeTable 网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高,这种说法对不对呢
mybatis-plus阻止全表更新与删除
BlockAttackInnerInterceptor 是mybatis-plus的一个内置拦截器,用于防止恶意的全表更新或删除操作。当你添加了这个拦截器后,它会检查即将执行的 sql语句,如果有尝试进行全表更新或删除的语句,该拦截器会阻止这些操作。 <!-- mybatis-plus --><dependency><groupId>com.baomidou</groupId><

mybatis实现business的全表查询(三种方法)
实现business的全表查询 select * from business 方法一: 1.定义父接口 package com.neusoft.Idao;import com.neusoft.pojo.Business;import java.util.List;public interface OpBusinessDao {public List<Business> findBusi();

mysql全表扫描会涉及到io吗_我说 SELECT COUNT(*) 会造成全表扫描,面试官让我回去等通知...
上篇SQL 进阶技巧(下)中提到使用以下 sql 会导致慢查询SELECT COUNT(*) FROM SomeTableSELECT COUNT(1) FROM SomeTable 原因是会造成全表扫描,有位读者说这种说法是有问题的,实际上针对无 where_clause 的COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高,这位读者的说法对不对
我说 SELECT COUNT(*) 会造成全表扫描,面试官让我回去等通知!
文章来源于码海 ,作者码海 前言 有人提到使用以下 sql 会导致慢查询 SELECT COUNT(*) FROM SomeTableSELECT COUNT(1) FROM SomeTable 原因是会造成全表扫描,有位读者说这种说法是有问题的,实际上针对无 where_clause 的 COUNT()*,MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实

SELECT COUNT(*) 会造成全表扫描吗?
前言 SELECT COUNT(*)会不会导致全表扫描引起慢查询呢? SELECT COUNT(*) FROM SomeTable 网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高,这种说法对不对呢 针对这个疑问,我首先去生产上找了一个千万级别的表使用 EXPLAIN 来查询了一
MySQL分库分表多维度查询——全表冗余
分表分库面临的问题 MySQL分库分表,一般只能按照一个维度进行查询. 以订单表为例, 按照用户ID mod 64 分成 64个数据库. 按照用户的维度查询很快,因为最终的查询落在一台服务器上. 非分区逻辑字段查询 但是如果按照商户的维度查询,则代价非常高. 需要查询全部64台服务器. 分页查询 在分页的情况下,更加恶化. 比如某个商户查询第10页的数据(按照订单的创建时间).需要在每台
Oracle11gR2 全表扫描成本计算(工作量模式-workload)
昨天测试了非工作量模式下Oracle11gR2全表扫描的成本计算,现在测试一下在工作量模式下Oracle11gR2全表扫描的成本计算 首先讲表blocks增加到10003个 SQL> select owner,blocks from dba_tables where table_name='TEST' and owner='TEST'; OWNER
Oracle11gR2 全表扫描成本计算(非工作量模式-noworkload)
数据库版本Oracle11gR2SQL> select * from v$version where rownum=1; BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.
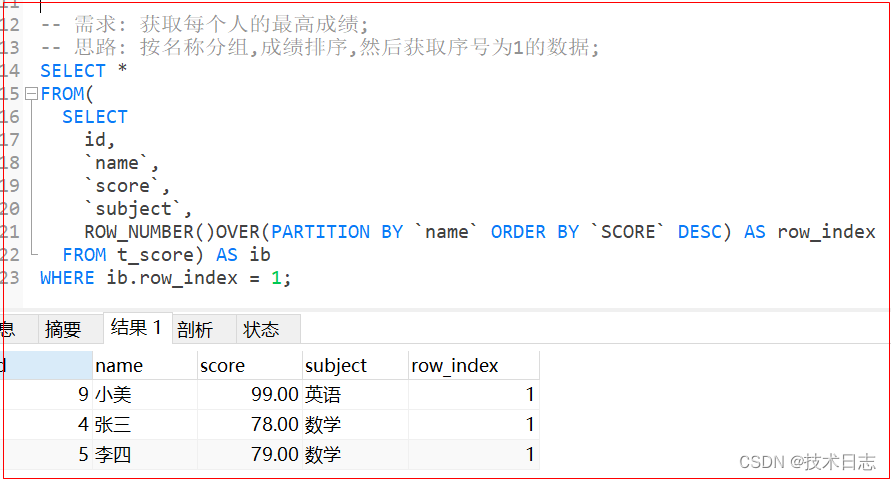
MySQL - 全表分组后,获取组内排序首条数据信息
性能 不详!!! 不详!!! 不详!!! 请谨慎使用!!!环境 MySQL服务: 8.0+版本;思路 使用8.0+版本的新函数特性: row_number(): 序号函数; 顾名思义, 就是给每组中的元素从1开始按顺序加上序号;over(): 其中两个语法如下 partition: 按某字段分组;order by: 按某字段排序;注意: 两函数详细使用方法可自行查询;第一步建表: CREATE