本文主要是介绍MySQL-32:全表扫描,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全表扫描的概念: 数据库服务器用来搜寻表的每一条记录的过程,直到所有符合给定条件的记录返回为止。
32.1 全表扫描流程
例如,我们执行如下sql,对表t进行全表扫描,这条sql的目的就是将全表的结果发送给客户端。
select * from t
流程如下:
- 服务端内存中有个net_buffer,大小由参数net_buffer_length控制,默认大小为16K。
- 读取一行,写入net_buffer中,直到写满,调用网络接口发送出去。
- 如果发送成功,则清空net_buffer,重复上述动作。
- 如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK,就表示本地网络栈写满了,进入等待。直到网络栈重新可写,再继续发送。
这样子,就是说MySQL在进行全表扫描的时候,是边读边发的,最大的内存使用为net_buffer。
Sending to client 与 Sending data:
- Sending data :可能处理执行器中的任意阶段,也就是语句正在执行中的意思。
- Sending to client:表示服务端的网络栈写满了
一条查询语句的状态变化如下:
- MySQL 查询语句进入执行阶段后,首先把状态设置成“Sending data”;
- 发送执行结果的列相关的信息给客户端;
- 再继续执行语句的流程;执行完成后,把状态设置成空字符串。
32.2 全表扫描对 InnoDB 的影响
当一个更新语句过来,先更新内存中信息,再写binlog,后续有空再同步到磁盘,这就是WAL技术。但是这里有个内存命中率的问题,内存大小是有限的,但所有的数据也都已经在用时,是需要从在使用的内存页中选择一个出来,进行淘汰,这个选择的策略就是内存淘汰算法,MySQL使用的淘汰算法未LRU,最近未使用。
LRU:最近未使用淘汰算法 :使用链表来进行实现,将最近的使用的页面放在链表头,淘汰的时候,就会淘汰链表末尾的页面。示意图如下:
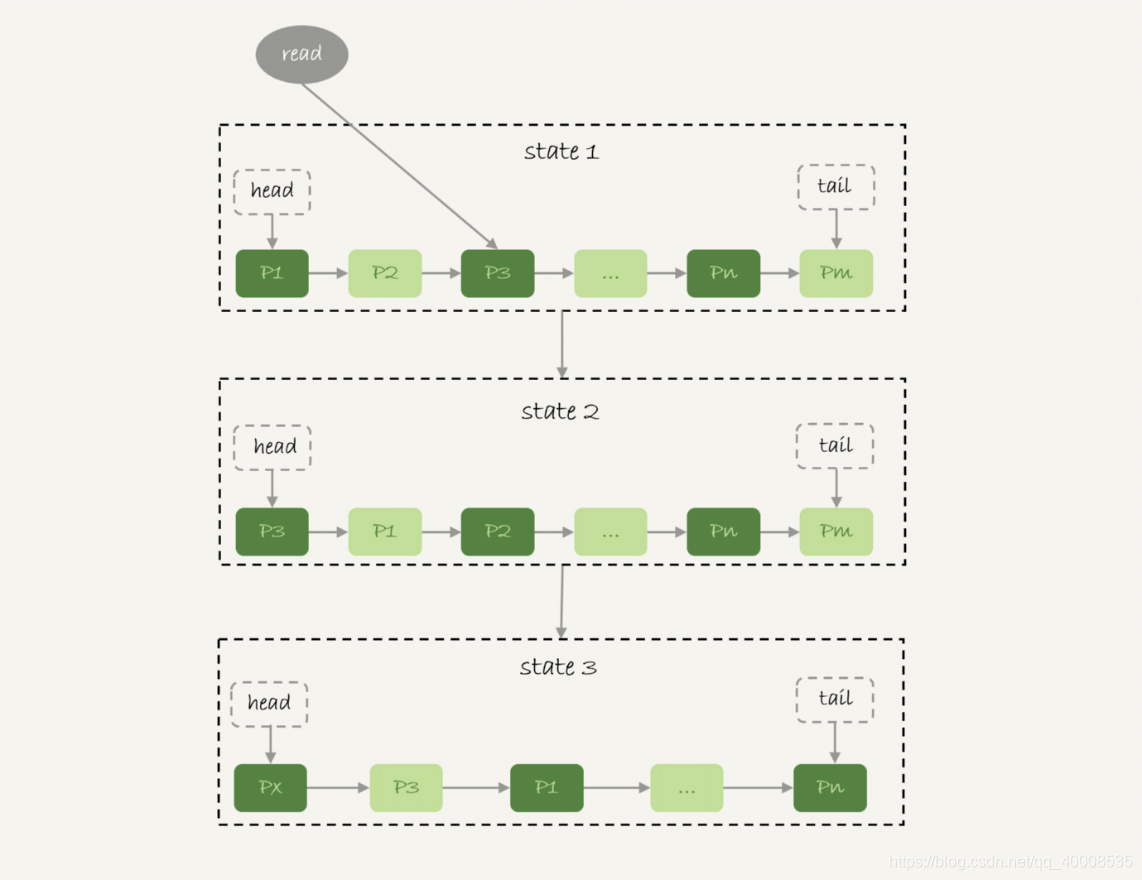
但是MySQL在进行全表扫描的时候,会导致内存命中率大大下降,也会导致内存页就行大换血。所以MySQL对LRU算法进行了改进。
将LRU的链表按照5:3的比例来进行分段,前面为young区域,后面未old区域,吼吼,怎么有点JVM的赶脚。
访问链表中节点方式如下:
-
访问young区域内的节点,则将该页面转移到链表头
-
访问old区域内的节点,需要进行如下判断
- 若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部;
- 如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
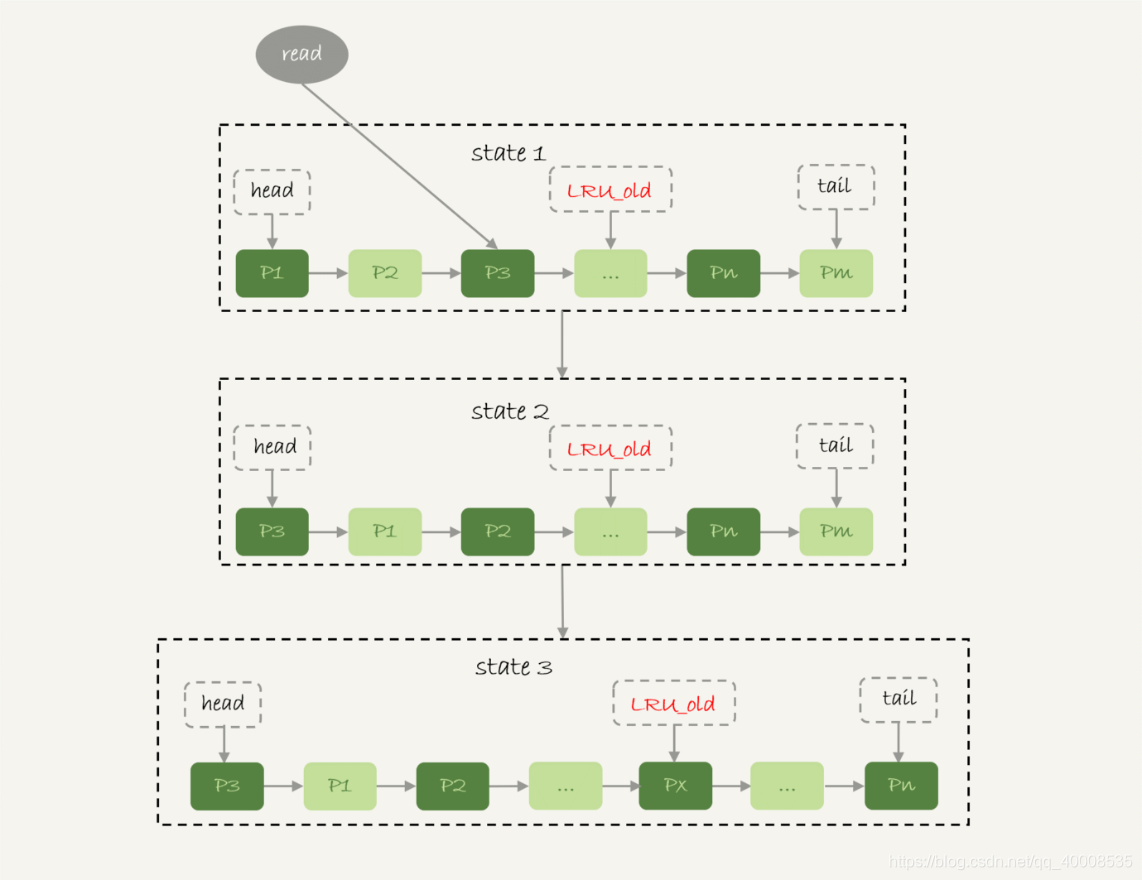
这个算法简直就是为全表扫描量身定做的啊,全表扫描为顺序访问,一个数据页的访问时间不会超过一秒钟,也不会进行young区域,也会很快地淘汰出去。
这个算法的思想也就是将一条链表切成两段,执行两种操作模式,在确保正常应用的情况,在额外添加上其它功能。
这篇关于MySQL-32:全表扫描的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




