本文主要是介绍oracle全表扫描优化,优化Oracle with全表扫描的问题(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
http://blog.itpub.net/29254281/viewspace-1242731/
尽信书不如无书
Oracle的优化器也不是万能的。
还是上次的SQL,开发说有时候执行时间超过3s。
我又查了查执行计划,发现有全表扫描和索引快速全扫描。这个是不符合预期的。
抽象问题如下:
create tableempas select * fromhr.employees;
create indexinx_hire_dateonemp(hire_date);
create indexinx_emp_idonemp(employee_id);
create indexinx_mgr_idonemp(manager_id);
查询主管号码为108的最近入职的3个雇员,并按照入职时间倒序排序,
SELECTt2.*
FROM (
SELECTrid
FROM (
SELECTemp.rowid ASrid,emp.employee_idASuser_id
FROMemp, (
SELECTemployee_id
FROMemp
WHEREmanager_id=108
)t
WHEREt.employee_id=emp.employee_id
ORDER BYhire_dateDESC
)
WHERE rownum <3
)t1,emp t2
WHEREt1.rid=t2.rowid
ORDER BYt2.hire_dateDESC;
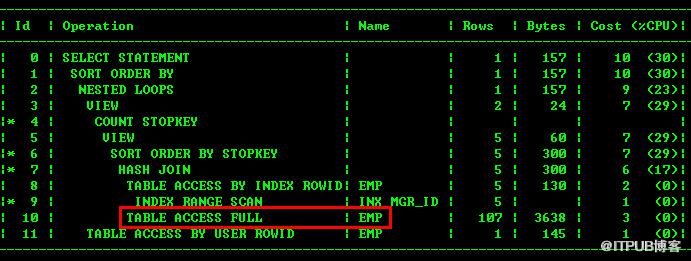
全表扫描,哈希连接
使用Hint指定连接方式
SELECT /*+use_nl(t1,t2)*/t2.*
FROM (
SELECTrid
FROM (
SELECT /*+use_nl(t,emp)*/emp.rowid ASrid,emp.employee_idASuser_id
FROMemp, (
SELECTemployee_id
FROMemp
WHEREmanager_id=108
)t
WHEREt.employee_id=emp.employee_id
ORDER BYhire_dateDESC
)
WHERE rownum <3
)t1,emp t2
WHEREt1.rid=t2.rowid
ORDER BYt2.hire_dateDESC;
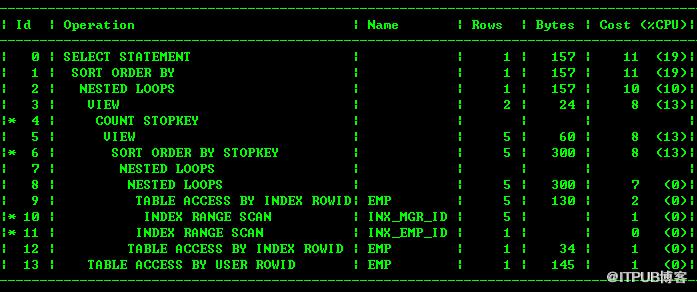
看来这个不是with的问题,而是优化器对于复杂的SQL不能正确的选择路径。
将原来的SQL修改如下,一致性读降为1000左右。
WITH t1
AS (SELECT to_userid
FROM friend_list f
WHERE f.userid = 411602438),
t2
AS (SELECT 'fc' AS t, rid, operTime
FROM ( SELECT/*+use_nl(t1,mc)*/
mc.ROWID rid, mc.operTime
FROM music_cover mc, t1
WHERE mc.userid = t1.to_userid
AND mc.opus_stat > 0
AND operTime IS NOT NULL
AND SYNC_FLAG = 1
ORDER BY mc.operTime DESC)
WHERE ROWNUM < 50
UNION ALL
SELECT 'yc', rid, operTime
FROM ( SELECT/*+use_nl(t1,mo)*/
mo.ROWID rid, mo.operTime
FROM music_original mo, t1
WHERE mo.userid = t1.to_userid
AND mo.opus_stat > 0
AND operTime IS NOT NULL
AND SYNC_FLAG = 1
ORDER BY mo.operTime DESC)
WHERE ROWNUM < 50
UNION ALL
SELECT 'sp', rid, operTime
FROM ( SELECT/*+use_nl(t1,mv)*/
mv.ROWID rid, mv.operTime
FROM music_video mv, t1
WHERE mv.userid = t1.to_userid
AND mv.opus_stat > 0
AND operTime IS NOT NULL
AND SYNC_FLAG = 1
ORDER BY mv.operTime DESC)
WHERE ROWNUM < 50
UNION ALL
SELECT 'bz', rid, operTime
FROM ( SELECT/*+use_nl(t1,ma)*/
ma.ROWID rid, ma.operTime
FROM music_accompany ma, t1
WHERE ma.userid = t1.to_userid
AND ma.opus_stat > 0
AND operTime IS NOT NULL
AND SYNC_FLAG = 1
ORDER BY ma.operTime DESC)
WHERE ROWNUM < 50
UNION ALL
SELECT 'rz', rid, operTime
FROM ( SELECT/*+use_nl(t1,bl)*/
bl.ROWID rid, bl.operTime
FROM blog_list bl, t1
WHERE bl.userid = t1.to_userid
AND bl.opus_stat > 0
AND operTime IS NOT NULL
ORDER BY bl.operTime DESC)
WHERE ROWNUM < 50
UNION ALL
SELECT 'xc', rid, operTime
FROM ( SELECT/*+use_nl(t1,pl)*/
pl.ROWID rid, pl.operTime
FROM photo_list pl, t1
WHERE pl.userid = t1.to_userid
AND pl.opus_stat > 0
AND operTime IS NOT NULL
ORDER BY pl.operTime DESC)
WHERE ROWNUM < 50),
t3
AS (SELECT *
FROM (SELECT TT.*, ROWNUM RN
FROM ( SELECT *
FROM t2
ORDER BY operTime DESC) TT
WHERE ROWNUM < 50)
WHERE RN >= 0),
t4
AS (SELECT/*+use_nl(t3,mc,ma,mo,mv,bl,pl)*/
t3.t opusType,
DECODE (t3.t,
'fc', 2,
'yc', 2,
'sp', 2,
'bz', 2,
'xc', 4,
'rz', 5)
type_code,
mc.userid
|| mo.userid
|| mv.userid
|| ma.userid
|| bl.userid
|| pl.userid
userId,
mc.file_url
|| mo.file_url
|| mv.file_url
|| ma.file_url
|| bl.file_url
|| pl.file_url
fileUrl,
mc.opus_Name
|| mo.opus_Name
|| mv.opus_name
|| ma.opus_name
|| bl.opus_name
|| pl.opus_name
opusName,
mc.opus_id
|| mo.opus_id
|| mv.opus_id
|| ma.opus_id
|| bl.opus_id
|| pl.opus_id
opusId,
TO_DATE (
TO_CHAR (mc.operTime, 'yyyy-mm-dd HH24:mi:ss')
|| TO_CHAR (mo.operTime, 'yyyy-mm-dd HH24:mi:ss')
|| TO_CHAR (mv.operTime, 'yyyy-mm-dd HH24:mi:ss')
|| TO_CHAR (ma.operTime, 'yyyy-mm-dd HH24:mi:ss')
|| TO_CHAR (bl.operTime, 'yyyy-mm-dd HH24:mi:ss')
|| TO_CHAR (pl.operTime, 'yyyy-mm-dd HH24:mi:ss'),
'yyyy-mm-dd HH24:mi:ss')
operTime,
mv.opus_desc
|| mo.opus_desc
|| mc.opus_desc
|| ma.opus_desc
|| bl.opus_desc
|| pl.opus_desc
opusDesc,
mv.album_id
|| mo.album_id
|| mc.album_id
|| ma.album_id
|| bl.album_id
|| pl.album_id
albumId,
mv.visit_num
|| mo.visit_num
|| mc.visit_num
|| ma.visit_num
|| bl.visit_num
|| pl.visit_num
visitNum
FROM t3
LEFT JOIN music_cover mc ON (t3.rid = mc.ROWID)
LEFT JOIN music_accompany ma ON (t3.rid = ma.ROWID)
LEFT JOIN music_original mo ON (t3.rid = mo.ROWID)
LEFT JOIN music_video mv ON (t3.rid = mv.ROWID)
LEFT JOIN blog_list bl ON (t3.rid = bl.ROWID)
LEFT JOIN photo_list pl ON (t3.rid = pl.ROWID))
SELECT/*+ ordered use_nl(t4,base) */
base.nickname,
base.showing,
DECODE (t4.type_code,
2, (SELECT al.album_name
FROM music_album al
WHERE al.album_id = t4.albumId),
4, (SELECT al.album_name
FROM photo_album al
WHERE al.album_id = t4.albumId),
5, (SELECT al.album_name
FROM blog_album al
WHERE al.album_id = t4.albumId))
albumName,
(SELECT COUNT (*)
FROM user_comment com
WHERE com.typeid = t4.type_code
AND t4.opusId = com.to_id
AND status >= 0)
commentTotal,
t4.*
FROM t4, mvbox_user.user_baseinfo base
WHERE base.userid = t4.userId
ORDER BY t4.operTime DESC;
这篇关于oracle全表扫描优化,优化Oracle with全表扫描的问题(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









