本文主要是介绍MySQL - 全表分组后,获取组内排序首条数据信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 性能
- 不详!!! 不详!!! 不详!!! 请谨慎使用!!!
- 环境
- MySQL服务: 8.0+版本;
- 思路
- 使用8.0+版本的新函数特性:
- row_number(): 序号函数; 顾名思义, 就是给每组中的元素从1开始按顺序加上序号;
- over(): 其中两个语法如下
- partition: 按某字段分组;
- order by: 按某字段排序;
- 注意: 两函数详细使用方法可自行查询;
- 使用8.0+版本的新函数特性:
- 第一步建表:
CREATE TABLE `t_score` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '姓名',`sex` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '性别',`score` double(20, 2) NULL DEFAULT NULL COMMENT '成绩',`subject` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '科目',`create_time` datetime NULL DEFAULT NULL,`update_time` datetime NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;- 第二步加数据:
INSERT INTO `t_score` VALUES (1, '张三', '男', 63.00, '语文', '2023-09-06 10:06:22', '2023-09-26 10:06:25');
INSERT INTO `t_score` VALUES (2, '李四', '男', 75.00, '语文', '2023-09-26 10:06:32', '2023-09-26 10:06:36');
INSERT INTO `t_score` VALUES (3, '小美', '女', 89.00, '语文', '2023-09-26 10:06:46', '2023-09-26 10:06:48');
INSERT INTO `t_score` VALUES (4, '张三', '男', 78.00, '数学', '2023-09-06 10:06:22', '2023-09-26 10:06:25');
INSERT INTO `t_score` VALUES (5, '李四', '男', 79.00, '数学', '2023-09-26 10:06:32', '2023-09-26 10:06:36');
INSERT INTO `t_score` VALUES (6, '小美', '女', 94.00, '数学', '2023-09-26 10:06:46', '2023-09-26 10:06:48');
INSERT INTO `t_score` VALUES (7, '张三', '男', 45.00, '英语', '2023-09-06 10:06:22', '2023-09-26 10:06:25');
INSERT INTO `t_score` VALUES (8, '李四', '男', 34.00, '英语', '2023-09-26 10:06:32', '2023-09-26 10:06:36');
INSERT INTO `t_score` VALUES (9, '小美', '女', 99.00, '英语', '2023-09-26 10:06:46', '2023-09-26 10:06:48');- 第三步看两函数效果:
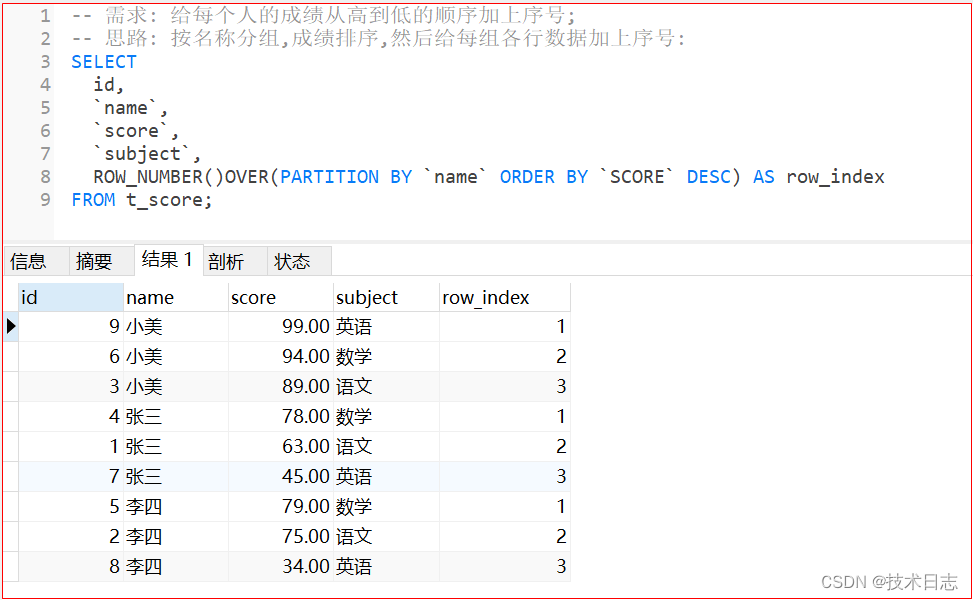
- 需求: 把每个人的成绩, 按照从高到低的顺序加上序号;
- 思路: 按名称分组, 成绩排序, 然后给每组各行数据加上序号;
-
SELECT id, `name`, `score`,`subject`, ROW_NUMBER()OVER(PARTITION BY `name` ORDER BY `SCORE` DESC) AS row_index FROM t_score;效果:
-
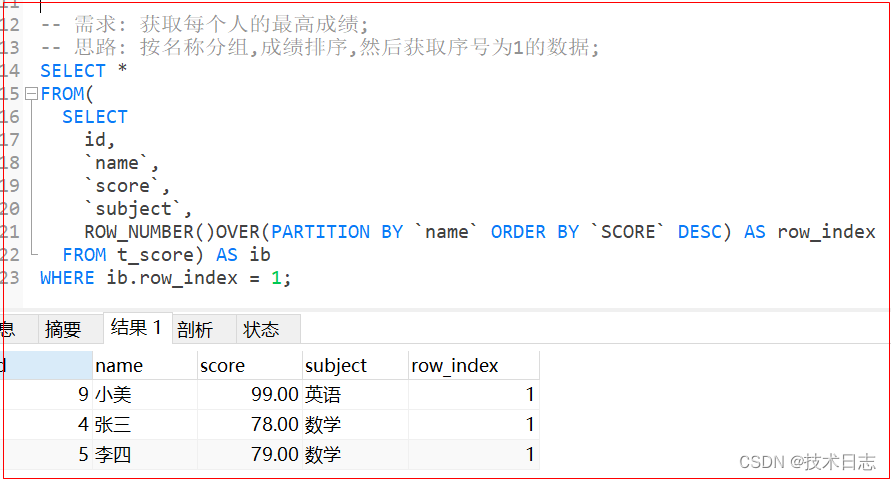
- 第四部实现最终需求:
- 思路: 按名称分组,成绩排序,然后获取序号为1的数据;
- 脚本:
-
SELECT * FROM(SELECT id, `name`, `score`,`subject`, ROW_NUMBER()OVER(PARTITION BY `name` ORDER BY `SCORE` DESC) AS row_index FROM t_score) AS ib WHERE ib.row_index = 1;
-
- 效果:
这篇关于MySQL - 全表分组后,获取组内排序首条数据信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





