万条专题

前端10万条数据优化方案
1. 虚拟化技术 使用虚拟化技术可以只渲染可见区域的数据,而不是将所有数据一次性渲染到 DOM 中。这可以大幅减少 DOM 元素的数量,从而提升渲染性能和页面响应速度。 react-virtualized 或 react-window:这些库可以帮助实现虚拟化长列表或大数据集。它们会根据滚动位置动态地渲染可见的数据项,而不是将所有数据项一次性渲染到 DOM 中。 2. 分页加载 将数据

Mybatis快速批量插入10万条数据实战
使用Mybatis大概有以下4种常见插入方法 1.使用for循环,每次执行一次insert插入(效率低不推荐) 2.使用MyBatis的标签遍历插入(效率低不推荐) 3.使用Mybatis,纯sql插入(推荐,效率最高) 4.使用 SqlSessionFactory,每一批数据执行一次提交(重点推荐) 下面直接推荐两种快速高效的方法,第一种需要手动拼写sql,比较麻烦,但是效率高一些,建议直接

我们用Python分析了B站4万条数据评论,揭秘本山大叔《念诗之王》大热原因!...
来源:恋习Python 本文约2000字,建议阅读10分钟。 我们通过Python大法通过获取B站:【春晚鬼畜】赵本山:我就是念诗之王!4万条数据评论,与大家一起看看其背后火起来的原因。 1990年本山老师首次登上中央电视台春节联欢晚会舞台,在春晚舞台给我们留下很多深入人心的作品如《相亲》,《我想有个家》,《昨天今天明天》,到2011年最后一次在春晚舞台表演小品,,22个年头陪我们度过了
Python爬取近10万条程序员招聘数据,告诉你哪类人才和技能最受热捧!
来源:凹凸数据 本文约5800字,建议阅读15分钟 本文带你了解当下企业究竟需要招聘什么样的人才?需要什么样的技能? 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得很有必要。 本文基于这个问题,针对51job招聘网站,爬
Python 100万条数据到MySQL数据库逐步写出到多个Excel
Python插入100万条数据到MySQL数据库 步骤一:导入所需模块和库 首先,我们需要导入 MySQL 连接器模块和 Faker 模块。MySQL 连接器模块用于连接到 MySQL 数据库,而 Faker 模块用于生成虚假数据。 import mysql.connector # 导入 MySQL 连接器模块from faker import Faker # 导入 Faker 模块,

分析 100 万条招聘数据发现,平均月薪最高的不是阿里、滴滴和腾讯
(点击上方公众号,可快速关注) 作者:八爪盒子,来源:CSDN 通过对各大招聘网站上的100万条招聘数据对比分析发现,在过去的7月份中,共计有26140条知名互联网公司职位招聘信息发布(其中剔除了销售、行政等非常规互联网职位以及非知名公司)。 与5月、6月相比,人才需求下降幅度由15%增加到了27%。7月份虽是招聘淡季,但人才流动仍十分频繁,人才需求也同样非常强烈。而对于所有程序员来讲,最
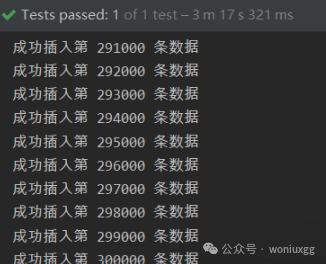
13 秒插入 30 万条数据,这才是 Java 批量插入正确的姿势!
本文主要讲述通过MyBatis、JDBC等做大数据量数据插入的案例和结果。 30万条数据插入插入数据库验证 实体类、mapper和配置文件定义 User实体 mapper接口 mapper.xml文件 jdbc.properties sqlMapConfig.xml 不分批次直接梭哈 循环逐条插入 MyBatis实现插入30万条数据 JDBC实现插入30万条数据 总结
一次性插入10万条数据,该如何操作?
参考:10万条数据批量插入,到底怎么做才快? - 知乎 (zhihu.com) 首先一般有两种方式:1.使用jdbc批处理模式 2.使用insert into values方式 第一种方式:他的优势是jdbc会帮我们进行预编译,然后把预编译结果缓存起来(我对这个预编译的理解是,一条sql到了mysql的sever层,需要进行词法分析,语法分析,构建语法树,然后检查字段是否有错,把*替换成所有

Python 爬取了 1.7 万条房产数据,告诉你深圳生存压力有多大!
最近各大一二线城市的房租都有上涨,究竟整体上涨到什么程度呢?我们也不得而知,于是乎笔者为了一探究竟,便用 Python 爬取了房某下的深圳租房数据。以下是本次的样本数据: 除去【不限】的数据(因为可能会与后面重叠),总数据量为 16971 ,其中后半部分地区数据量偏少,是由于该区房源确实不足。 因此,此次调查也并非非常准确,权且当个娱乐项目,供大家观赏。 统计结果 我们且先看统计结果,然后
39万条数据生成Excel,内存溢出问题
1、OOM异常:发现一个查询账户交易明细写入Excel文件方法抛出异常,内存溢出。 2、服务器内存4G,根据日志查出内存占用对象,Excel 16列*592B*400000条数据=3788,800,000B~3.7G计算将近达到4G,内存溢出。 3、查询原因,数据库查询采用1000条一查,查询应该不回导致内存问题。后来生成Excel时候,大量对象在内存中没有释放。原因是使用了XSSFWo
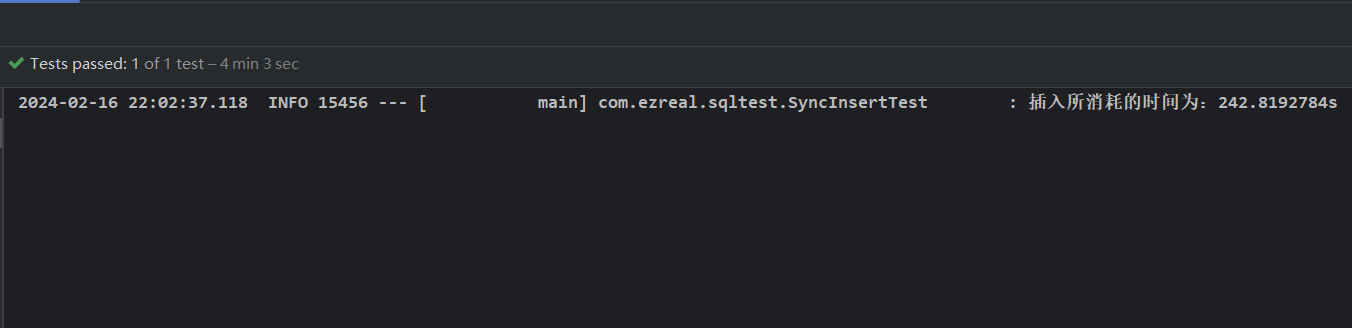
MySQL 插入10万条数据性能分析
MySQL 插入10万条数据性能分析 一、背景 笔者想复现一个索引失效的场景,故需要一定规模的数据作支撑,所以需要向数据库中插入大约一百万条数据。那问题就来了,我们应该怎样插入才能使插入的速度最快呢? 为了更加贴合实际,下面的演示只考虑使用 Mybaits 作为 ORM 框架的情况,不使用原生的 JDBC。下面,我们只向数据库中插入十万条数据作为演示。 二、实现 1. 使用 Mybait
《三十而已》火爆全网,我分析了21万条弹幕,发现了这些秘密
最近几周,在《隐秘的角落》热度落去后,《三十而已》又闯进了大家的视线中,被大家不停的讨论,想必没看过这部电视剧的小伙伴们也或多或少的从朋友那里听到过这部电视剧吧。 《三十而已》以三位三十岁的女性视角进行展开,或多或少的体现出现实中我们遇到的问题,更能引起大家的共鸣,因此走红也在情理之中。今天,小编爬取了腾讯视频的近21万条弹幕,看看大家是如何评价这部电视剧的。 1 弹幕的抓取 首先是弹幕的

爬取 Stackoverflow 100 万条问答并简单分析
打开 stackoverflow 主页,在 questions 页面下选择按 vote 排序,爬取前 20000 页,每页将问题数量设置为 50,共 1m 条,(实际上本来是想爬完 13m 条的,但 1m 条后面问题基本上都只有 1 个或 0 个回答,那就选取前 1m 就好吧) 实际上用数据库去重后只有 999654 条问答信息 对爬取数据进行简单分析 votes 分析 降序排列了 v
9 万条弹幕告诉你,谁才是《乘风破浪姐姐》里的真正 C 位!
公众号关注 “GitHubDaily” 设为 “星标”,每天带你逛 GitHub! 作者 | Mika 出品 | CDA 数据分析师(ID:cdacdacda) 今天我们来聊聊最近火到不行的综艺 ——《乘风破浪的姐姐》,Python 分析弹幕部分请看第四部分。点击下方视频,先睹为快: 如果说最近最热门的综艺,那《乘风破浪的姐姐》(下文简称《姐姐》)可谓实至名归。 30 位出道多年的姐姐辈女艺人
一次性往数据库中插入1万条数据的方法
MySQL开启事务需要消耗一定的时间,所以我们可以把这1万条插入的sql语句封装在同一个事务中,否则MySQL就会默认给每一条sql语句都开启一个事务,也就是开启1万个事务。 下面的例子中我们使用MySQL的存储过程来添加事务,MySQL中有一张表如下: CREATE TABLE `person` ( `id` int NOT NULL AUTO_INCREMENT, `name`

mysql数据库100万条数据JDBC插入的各种方式效率对比。
mysql数据库100万条数据JDBC插入的各种方式效率对比 下面测试四个方式: 1 、一条一条插入 166秒/10万 2、jdbc采用事务提交 135秒/10万 3、batch方式(内部实现方式-拼接values) 12.73秒/10万 4、事务+batch方式 9.99秒/10万 package test.jbdc;import java.sql
docker 安装oracle 19C和Oracle数据库创建100万条数据
docker 安装oracle 19C #拉取oracle19c镜像 docker pull heartu41/oracle19c #创建挂载目录 mkdir -p /data/oracle/oracle19c/data #修改挂载目录权限 chmod 777 /data/oracle/oracle19c/data #启动容器 docker run -d -p 21521:1521 -e O
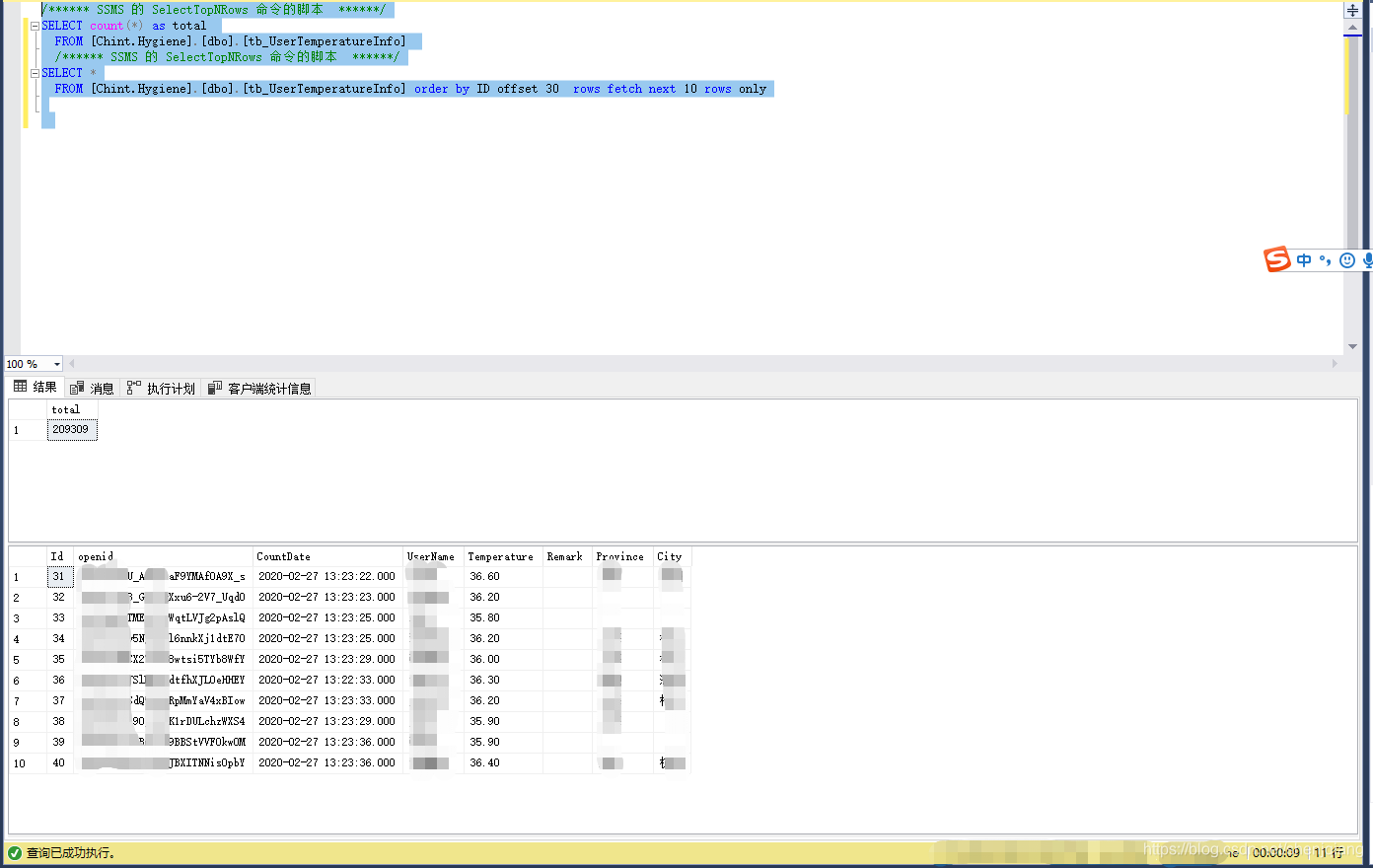
SQLServer 分页分页查询优化方案,1秒内查询20万条数据的表
最近在做sql分页查询的话,发现数据表中的数据量非常大的话,使用count(*)去统计行数的话,还是非常慢的。20多万条数据的表,用count查询,大概在9秒左右。 服务器是4核8G内存的。5秒左右的时间,还是比较难以接受的,9秒时间的SQL语句如下所示: /****** SSMS 的 SelectTopNRows 命令的脚本 ******/SELECT count(*) as total

38万条数据,用python分析保险产品交叉销售相关因素!
CDA数据分析师 出品 作者:真达、Mika 数据:真达 【导读】今天的内容是一期Python实战训练,我们来手把手教你用Python分析保险产品交叉销售和哪些因素有关。 01、实战背景 首先介绍下实战的背景, 这次的数据集来自kaggle: https://www.kaggle.com/anmolkumar/health-insurance-cross-sell-pred
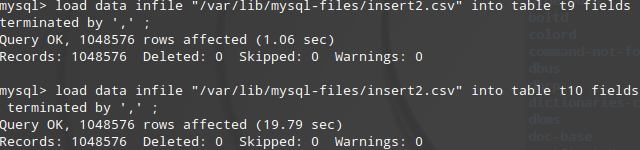
快速导入100万条Excel数据到MySql
因业务需要,将100万条Excel数据导入MySql OS : CentOS7 , MySql 5.7 做了2个纯命令导入测试,不考虑phpmyadmin,navicate导入. 首先MySql调整全局变量 set max allowed packet =104857600 (100Mb)set wait_timeout=288000set interactive timeout=28
豆瓣9.2分!17万条弹幕告诉你《沉默的真相》凭什么口碑高开暴走!
公众号后台回复“图书“,了解更多号主新书内容 作者:CDA数据分析师 来源:CDA数据分析师 CDA数据分析师 出品 作者:Mika 数据:真达 【导读】 今天教大家用Python分析《沉默的真相》的17万条弹幕。公众号后台,回复关键字“沉默”获取完整数据。 距离上一部国产良心剧《隐秘的角落》刷屏还不到2个月,“秃头梗”、“爬山梗”还让人记忆犹新。 紧接着又一部爆款国产剧来了

如何在4万条数据中快速高效删除excel表指定的2500条数据?
准备工作: 1、编写删除脏数据的sql DELETE FROMequipment_info WHEREid IN (SELECTt.id FROM(SELECTi.id FROMequipment_info iLEFT JOIN base_district d ON i.district_id = d.idLEFT JOIN base_street s ON i.street
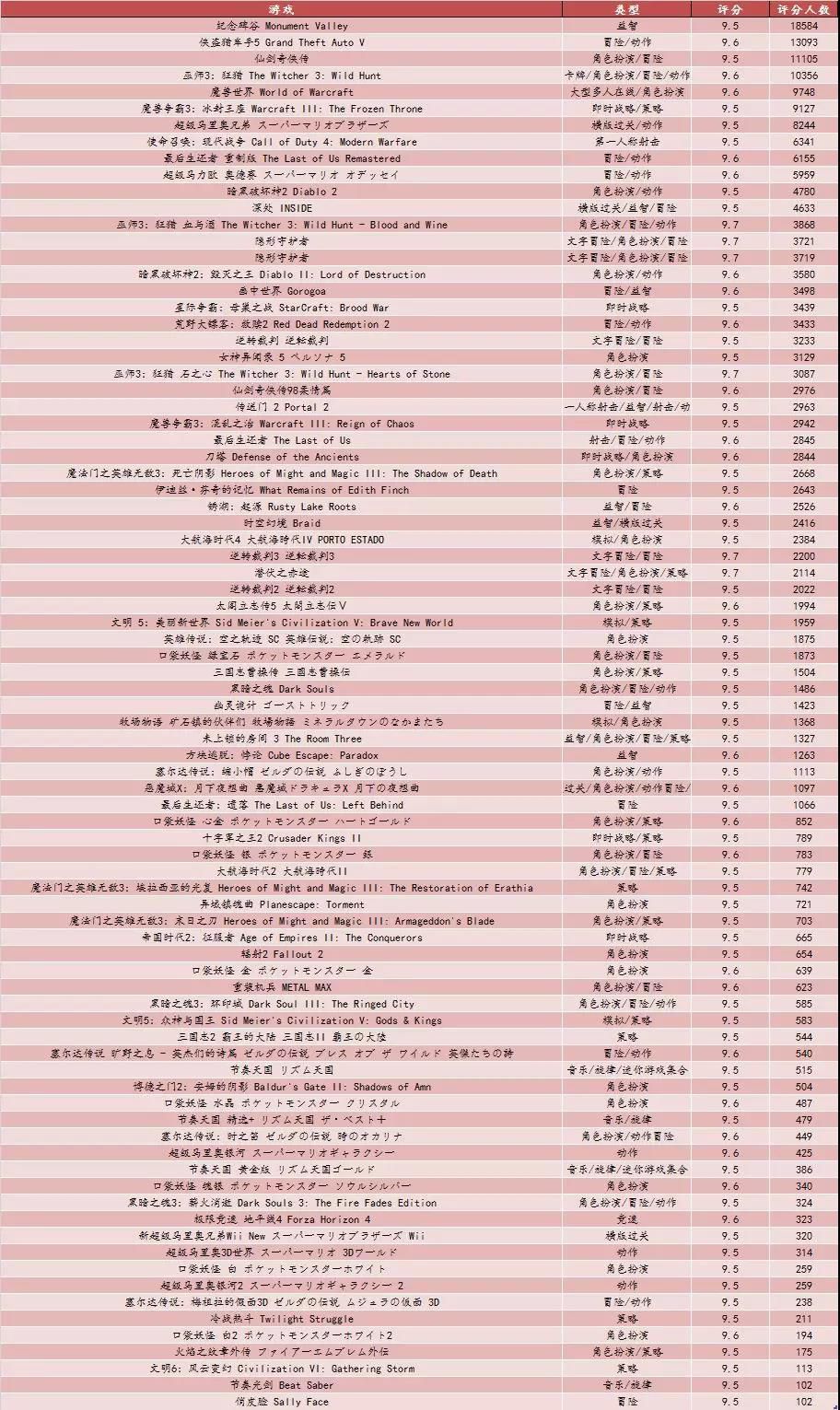
Python 爬取 3 万条游戏评分数据,找到了程序员最爱玩的游戏(附代码)
本文爬取了游戏网站上所有可见的游戏评分数据进行分析,全文包括以下几个部分: 数据获取数据总览游戏类型分析游戏平台分析游戏名称分析高分游戏汇总代码汇总 全文数据获取及分析均基于python3.6完成。数据获取过程 页面内一条游戏数据展示如下,显示出来的一条评论是游戏的点赞数最多的评论,我们分析需要的数据包括游戏名称、游戏类型、游戏平台、游戏评分、游戏评价人数及最热评价。
26万条抖音数据背后的推荐逻辑|为什么小哥哥更受欢迎
这次是26W条数据,应该可以说明更多问题。 和往常一样,先给出分析结论,希望你能引起你的兴趣: 首次推荐分水岭应该在5000人,点赞不过百基本凉了;抖音红利似乎在消失,用户越来越不喜欢点赞了;15s不一定是最好的,可以试试10s;男女比例严重失调,小哥哥的视频更受喜爱;“生活化”是抖音内容的主体,年轻人乐于表达爱和喜欢;90后是抖音的主力军,94年小哥哥小姐姐最多;一些小技巧,比如
用Python分析9万条数据告诉你复仇者联盟谁才是绝对C 位!
01 抓取数据 业界朋友们,在电影分析中,使用猫眼的数据比较多。在本文中,笔者也使用了猫眼的接口来获取数据,方便处理,数据量也比较多。 有关接口,大家可以自己去猫眼的网站上看,也可以使用如下地址: http://m.maoyan.com/mmdb/comments/movie/248172.json?_v_=yes&offset=20&startTime=2019-04-24%2002:
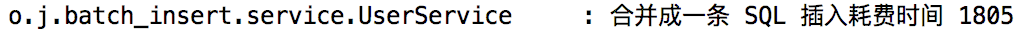
10万条数据批量插入,到底怎么做才快?
文章目录 1. 思路分析2. 数据测试2.1 方案一测试2.2 方案二测试2.3 对比分析 3. MP 怎么做的?4. 小结 上周松哥转载了一个数据批量插入的文章,里边和大家聊了一下数据批量插入的问题,批量插入到底怎么做才快。 有个小伙伴看了文章后提出了不同的意见: 松哥认真和 BUG 同学聊了下,基本上明白了这个小伙伴的意思,于是我自己也写了个测试案例,重新整理了今天