本文主要是介绍Python 爬取 3 万条游戏评分数据,找到了程序员最爱玩的游戏(附代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文爬取了游戏网站上所有可见的游戏评分数据进行分析,全文包括以下几个部分:
- 数据获取
- 数据总览
- 游戏类型分析
- 游戏平台分析
- 游戏名称分析
- 高分游戏汇总
- 代码汇总
全文数据获取及分析均基于python3.6完成。
数据获取过程
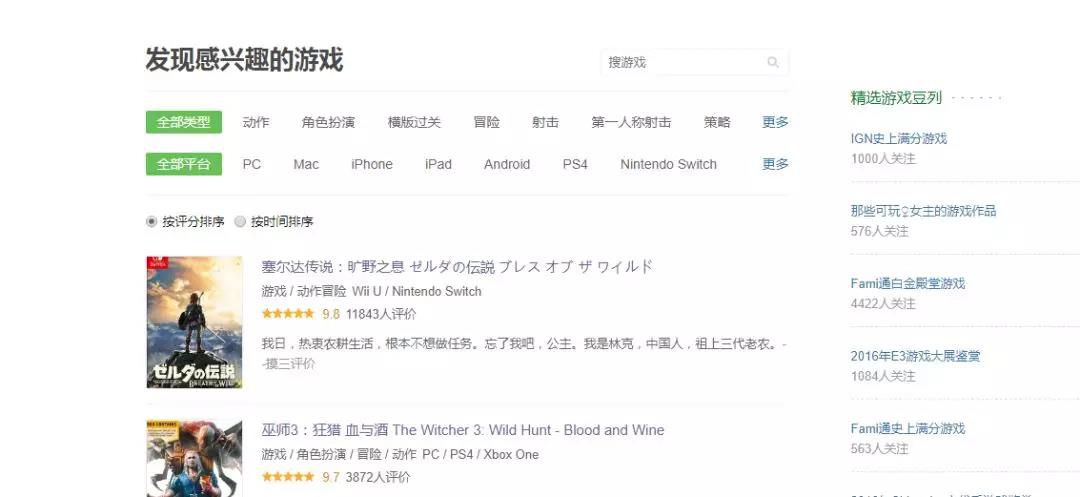
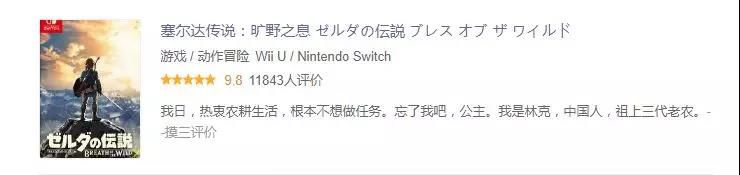
页面内一条游戏数据展示如下,显示出来的一条评论是游戏的点赞数最多的评论,我们分析需要的数据包括游戏名称、游戏类型、游戏平台、游戏评分、游戏评价人数及最热评价。
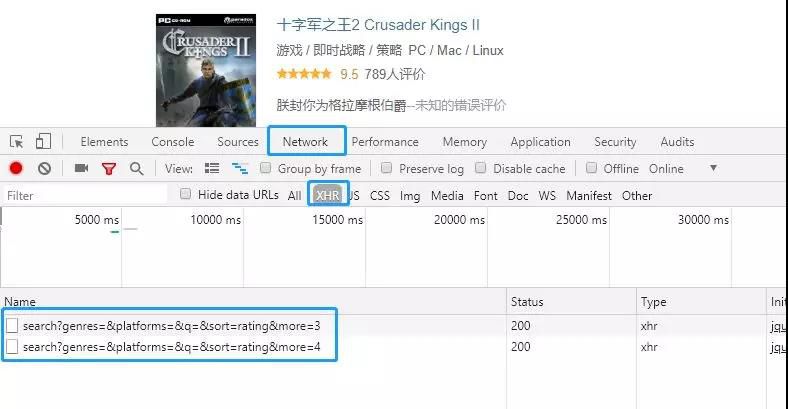
浏览器中按F12打开开发者工具,选择NetWork-XHR,页面拉倒底部点显示更多,可以看到获取到的数据文件。
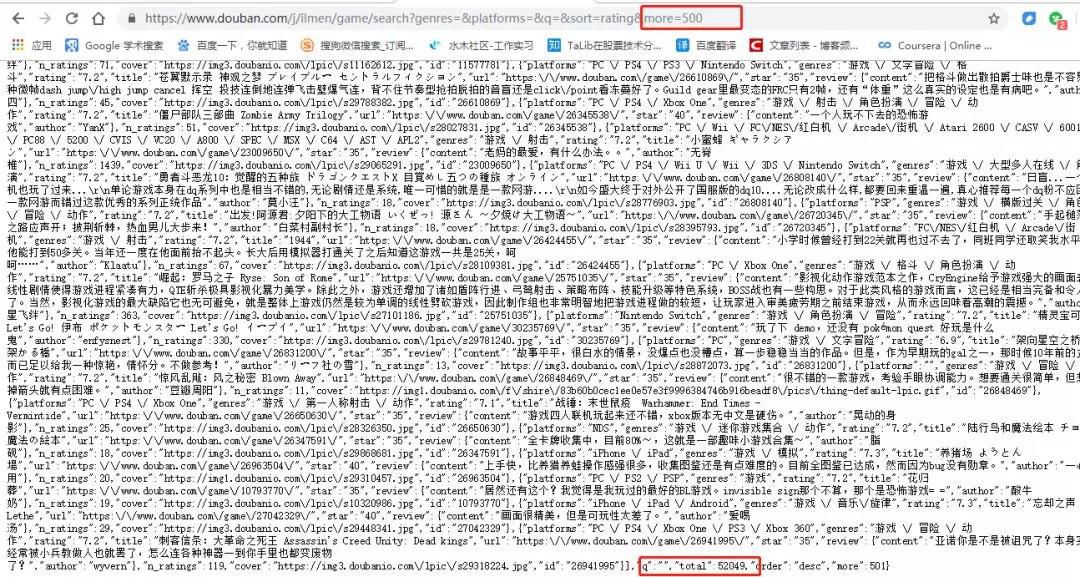
右键打开后看到是游戏的信息,通过改变网址中more后面的数字,可以获取更多数据。但尝试之后发现,每次可以获取20条数据,more后面的数字最大可以设置为500,超过500后获取不到数据,也就是说最多能获取10000条数据,但底部total字段显示总的游戏数据有52049条。
所以为了获取更多数据,我们分类型爬取数据,每次选中一个类型,重复上述过程,可以得到数据,观察后发现每个类型下的游戏数据都不超过10000条,这样每个类型的数据都能全部获取,最后把所有数据拼到一起即可。

以动作类游戏为例:
多尝试几次之后能看出规律:genres后面是游戏类型,动作类型对应的genres=1,platforms后面是平台类型,q后面的是游戏名称关键字,sort后面是排序方式,默认是按评分排序,more后面是页码。
所以我们需要知道每个游戏类型对应的数字,可以在开发者工具中选Element,用小箭头进行定位,快速获取所有游戏类型对应的数字:
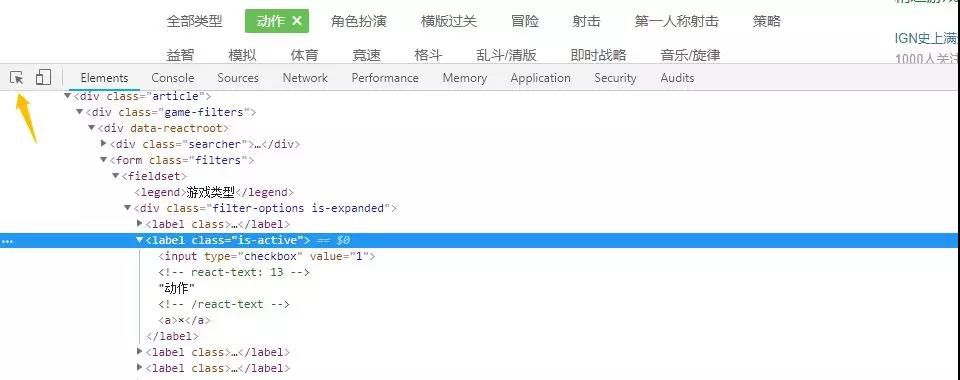
定位后发现,每种类型包含在一个class内,动作类型对应的数字在values里。
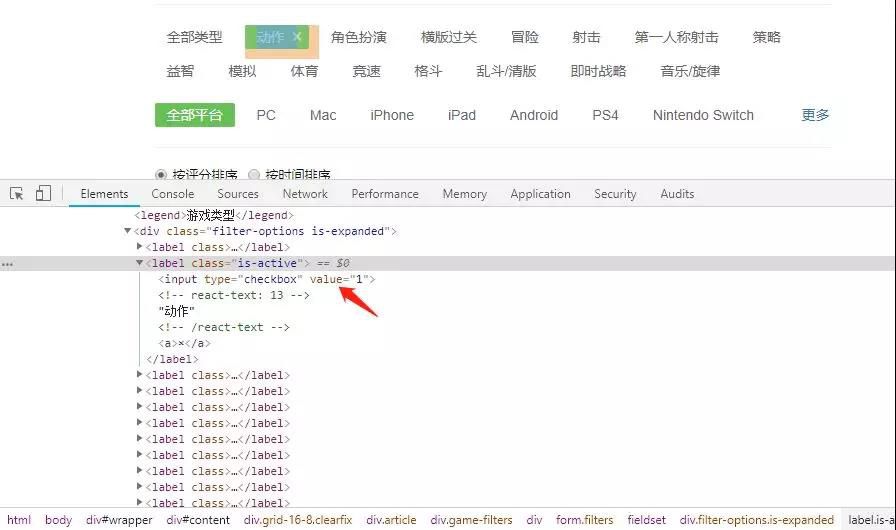
依次点开每个class,获取每个类型对应的数字,整理如下:
{1:"动作",5:"角色扮演",41:"横版过关",4:"冒险",48:"射击",32:"第一人称射击",2:"策略",18:"益智",7:"模拟",3:"体育",6:"竞速",9:"格斗",37:"乱斗/清版",12:"即时战略",19:"音乐/旋律"}
之后就可以用python中的request+json包循环获取数据了,代码附在最后。爬到的一条游戏数据样式如下:
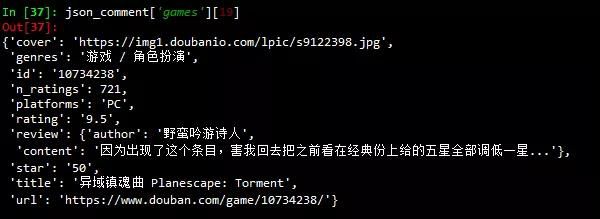
需要的数据包括:
- n_ratings:评分人数
- platforms:平台
- rating:评分
- star:星级
- title:游戏名称
- content:最热评论
游戏类型因为已经我们已经分类型爬取,所以每次爬完之后用代码加上对应的类型即可,但能看到一个游戏可能对应多种类型,或者在多个平台上同时发布,所以在后面的分析中需要处理,其他字段分析中用不到。
数据总览
最终爬下来数据有31574条,还是没拿到所有5万条,这已经是最大可见数据条数了,数据样式如下:
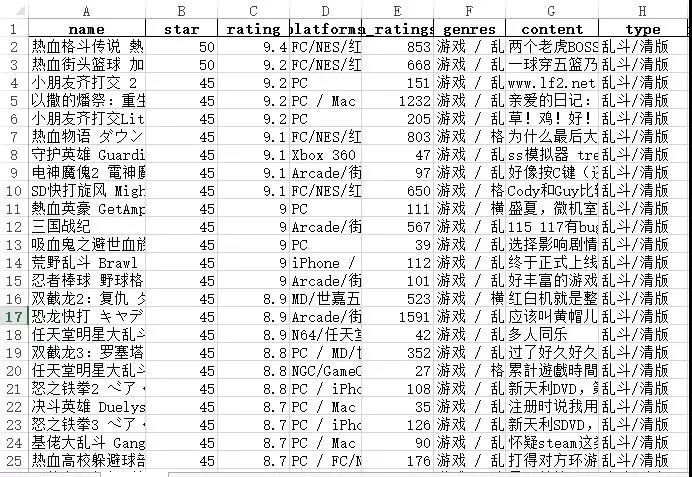
genres是网站上给的类型,type是爬取过程中加上去的类型,后文的分析都用type。
简单统计后发现,31574条数据中有17751条数据都是没有评分的,此外,由于一种游戏可能属于多个类别,所以一部分游戏是重复出现的,只有type不同。
首先对数据整体做一个统计描述,对于没有评分的数据采用两种方法处理,视为评分为0和删除数据。
视为评分为0时:
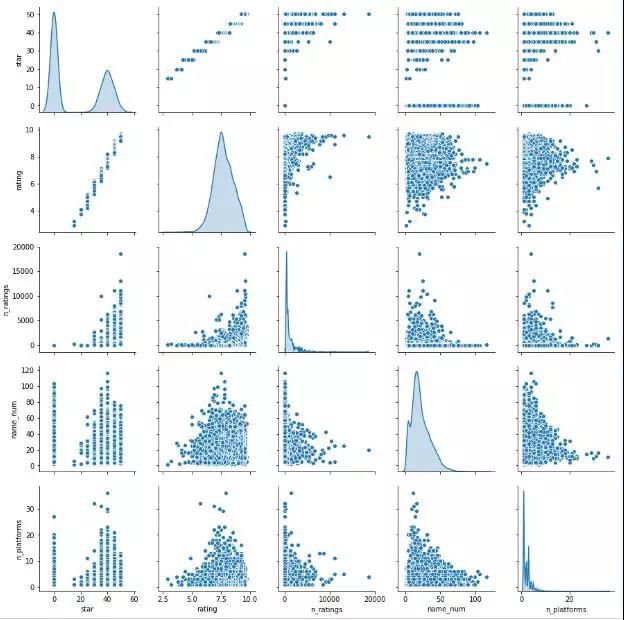
删除没有评分的数据:
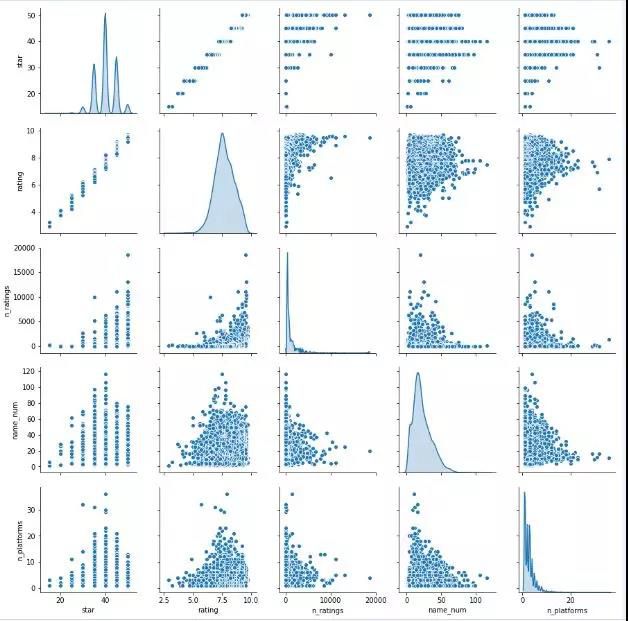
两幅图的5个变量(从左往右、从上至下)均为:星级、评分、评分人数、游戏名称长度、游戏发行平台数,加入游戏名称长度和发行平台数是想探究游戏名称的长度以及发行的平台数是否和游戏评分有一定的关系。
从这两幅分布图能得到一些结论:
- 星级(star)和评分(rating)是严格单调关系的,星级是分级靠档后的评分,所以之后的分析中只考虑星级不考虑评分。
- 两种评分处理方法下,各变量的分布基本不变,大部分游戏评分集中在7.5左右,评分跟发行平台数、游戏名称长度关系不是非常明显。
游戏类型分析
各类型游戏数:
豆瓣给出的游戏共有15类,各类型游戏数统计如下:
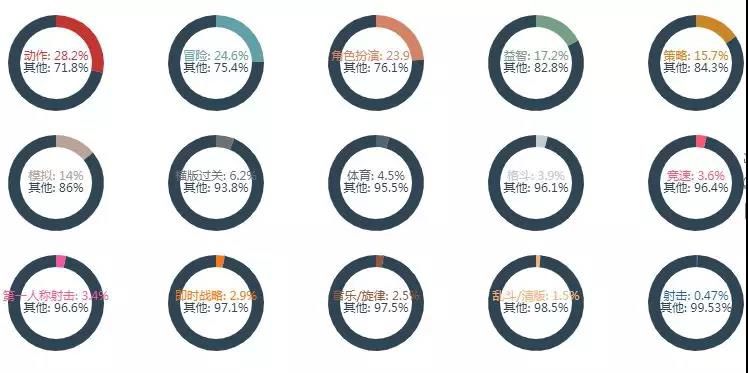
动作、冒险、角色扮演、益智、策略类的游戏数量排到前5,第一人称射击、即时战略、音乐、乱斗/清版、射击类排到后5。
豆瓣把第一人称射击、射击分成两类,乱斗跟冒险、动作的区别似乎不是很大?这里不是很理解。
不过射击类的游戏模式太过单一,数量确实比较少,高质量的射击游戏不外乎这两年火起来的吃鸡游戏,还有很早之前的CS系列。
而动作、冒险、角色扮演类的游戏从世界观设定、剧情设计上都可以有很多新意,时不时会有一些让人眼前一亮的新作品,也很容易做成一个系列。
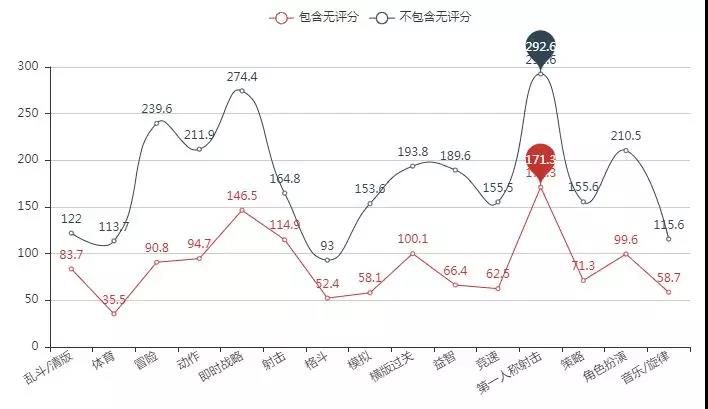
各类型游戏平均评分人数:
评分人数最多的是第一人称射击类游戏,冒险、即时战略类也较多。
各类型游戏均分:
各类型游戏的均分如下,无评分视为0时,由于各种游戏数量的差别,导致游戏数较少的类型平均分更高,但删掉无评分数据后,各种类型的评分基本是持平的,在7.5分上下波动。
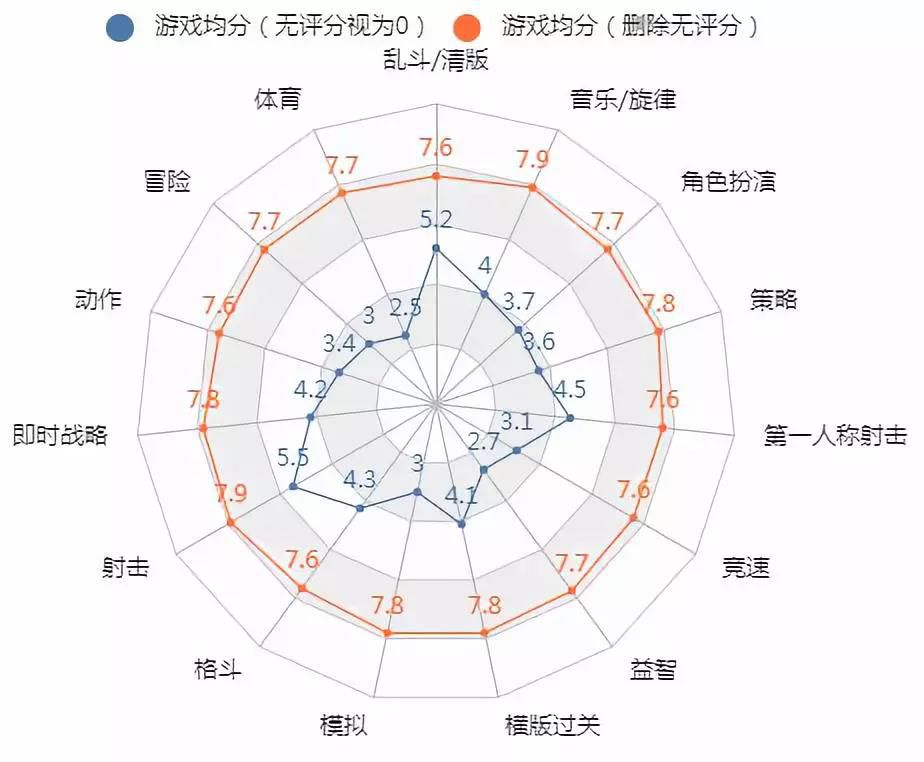
总体来看,各种类型游戏的平均质量基本是一样的,只是各种类型的用户基数差别大一些。
游戏类型关联分析:
之前提到,一个游戏可能属于多个类别,比如仙剑同时属于角色扮演和冒险。对所有的游戏类别进行交叉分析,统计同时属于两个类别的游戏个数,结果如下:
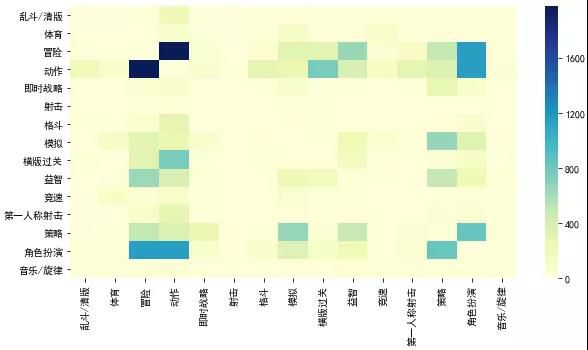
可以看到,动作+冒险,角色扮演+动作/冒险、横版过关+动作/冒险、益智+冒险组合的游戏都是非常多的,动作、冒险大概是万能类别了。
音乐旋律、竞速类的游戏跟其他类别交叉几乎没有,这两种类型游戏形式比较单一,大部分都是拼手速操作,各种游戏同质性比较高。侠盗飞车是其中少有的融合了动作冒险的经典竞速类游戏,但当年玩罪恶都市的快感似乎跟竞速没啥关系。

游戏平台分析
游戏平台类型非常多,整体分为手机、电脑、游戏机三类,游戏机大部分是任天堂(Wii,GB)、索尼(PS)、微软(Xbox)的产品。

之前提到,一款游戏可能同时在多个平台上发布,这给分析过程带来了一定难度,观察后发现,豆瓣的平台分布是越靠前的平台越大众化,所以对于有多个平台的游戏,取第一个平台,视为他的主要发布平台进行分析。
各平台游戏数:
鉴于平台数太多,我们把所有游戏数目小于100的平台汇总,记为“其他”,各个平台游戏数分布如下:
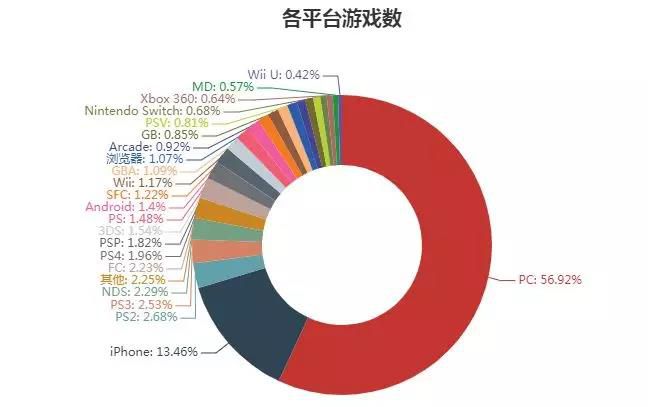
PC游戏数超过总数的50%,除此外,大部分游戏在iphone,PS2,PS3上,没有Android的原因在于豆瓣上对于游戏平台把iphone放在Android前面,大部分手游是在这两个操作系统上同时发布的,之前的处理方法导致Android数目非常少归到了“其他”中去。
各平台均分:
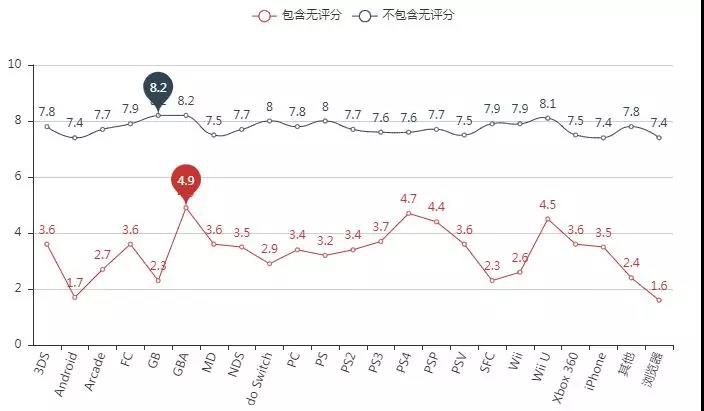
删除无评分数据游戏后,各平台均分基本一致。其中均分最高的GB是任天堂1989年推出的Game Boy游戏机,GBA是任天堂2001年推出的Game Boy Advanced游戏机。你可能没有用过这两款设备,但当中的经典游戏你一定玩过。
各平台平均评分人数:
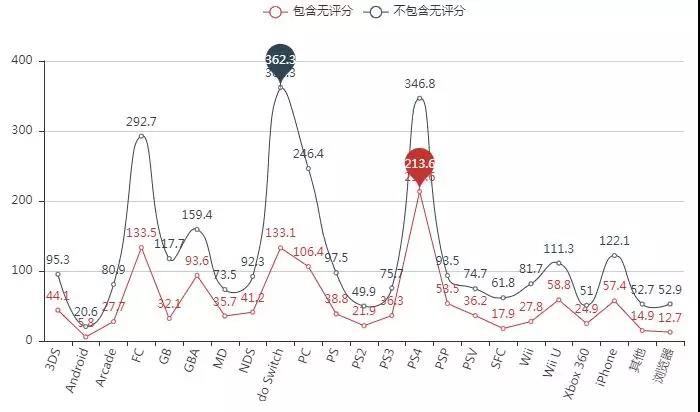
各平台评分总人数来说,PC占据绝对优势,但平均人均数来看,人数最多的是PS4和Nintendo Switch。
游戏名称分析
一个有意思的问题是,游戏都是怎样命名的呢?有没有什么规律?
爬取下来的游戏名称中大部分同时包含中文、英文,这里我们只分析中文,将所有游戏名称拼到一起用正则提取其中的中文,去掉长度为1的词,和词频小于10的词,对剩下的高频词按词频做词云如下:

词语能反映出游戏的世界观,大部分的游戏会用到战争、战士、传奇、联盟、幻想这样一些虚构的有奇幻色彩的词语,同时也不乏三国、火影等等一些源于历史、动漫、小说、电影作品的词。还有一些开门见山直接说明游戏形式的词语,比如迷宫、格斗、大战、足球等等。
高分游戏汇总
对游戏的整体分析只是统计分析的需要,但对一个游戏迷来说,只需要告诉他哪些游戏好就ok了,不好的游戏并不关注,我们提取所有游戏中评分超过9.5的部分,游戏类型分布如下:
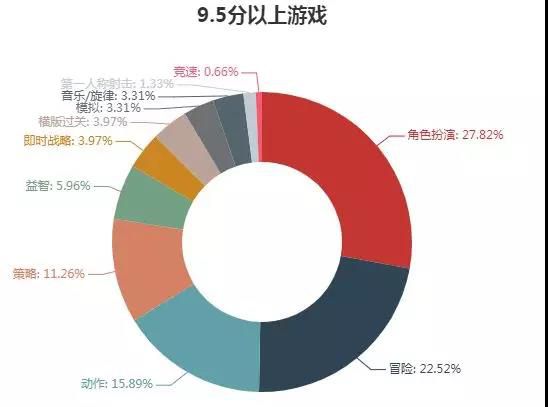
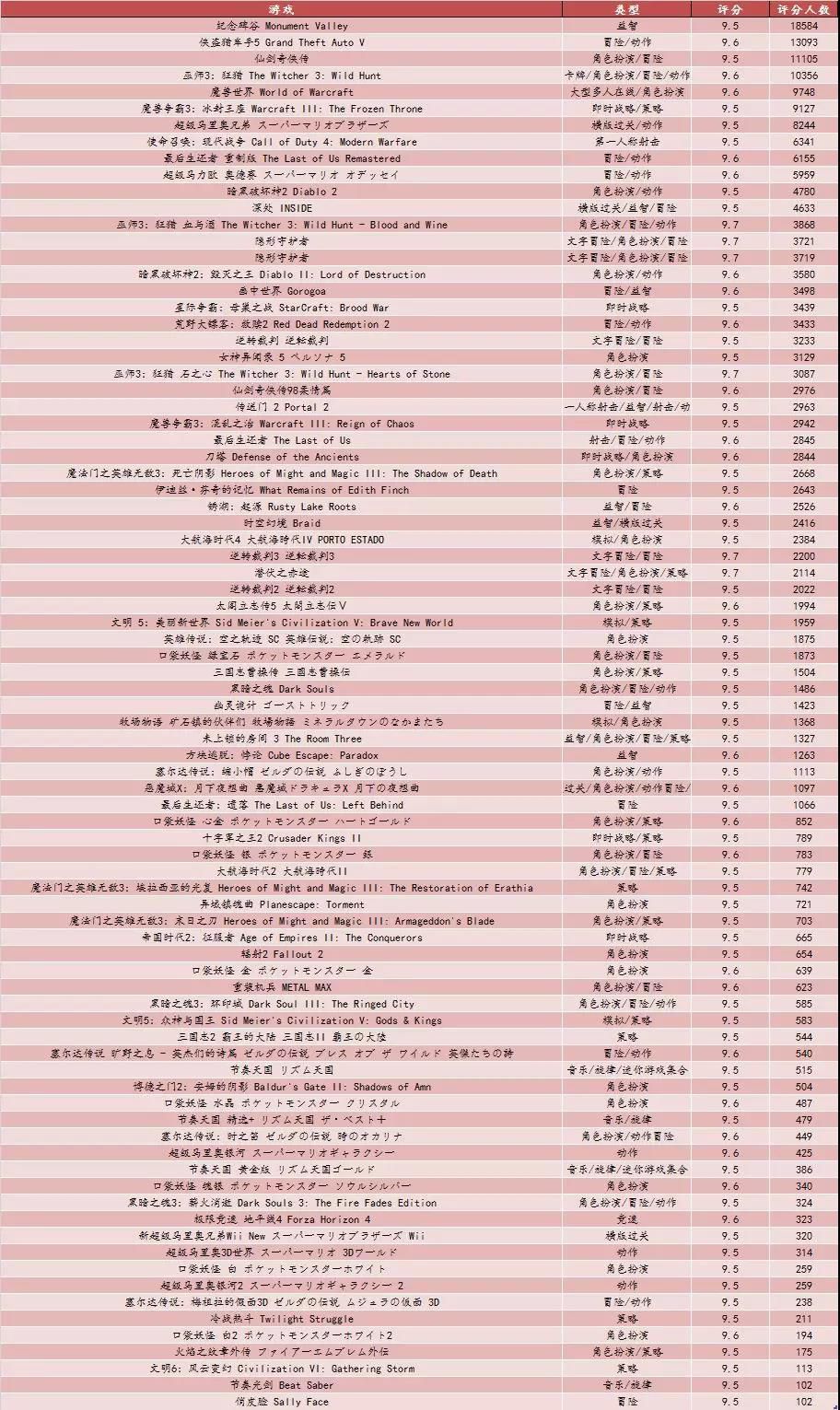
考虑到评分人数太少时,手机号出售平台评分结果不一定具有代表性,所以我们只选择其中评分人数超过100的部分,共84款游戏汇总如下,看看有没有你玩过or你想玩的呢?
代码汇总
爬虫代码:
- # -*- coding: utf-8 -*-
- import urllib
- import requests
- from fake_useragent import UserAgent
- import json
- import pandas as pd
- import time
- import datetime
- import os
- # 发送get请求
- """
- genres : 游戏类别
- n_ratings: 评分人数
- platforms: 平台
- rating : 评分
- content : 最热评论
- star : 星数
- title : 游戏名称
- """
- def getDoubanGame(genres):
- id_all1 = {1:"动作",5:"角色扮演",41:"横版过关",4:"冒险",48:"射击",32:"第一人称射击",
- 2:"策略",18:"益智",7:"模拟",3:"体育",6:"竞速",9:"格斗",37:"乱斗/清版",12:"即时战略",
- 19:"音乐/旋律"}
- comment_api = 'https://www.douban.com/j/ilmen/game/search?genres={}&platforms=&q=&sort=rating&more={}'
- headers = { "User-Agent": UserAgent(verify_ssl=False).random}
- response_comment = requests.get(comment_api.format(genres,1),headers = headers)
- json_comment = response_comment.text
- json_comment = json.loads(json_comment)
- col = ['name','star','rating','platforms','n_ratings','genres','content']
- dataall = pd.DataFrame()
- num = json_comment['total']
- print('{}类别共{}个游戏,开始爬取!'.format(id_all1[genres],num))
- i = 0
- while i < num:
- if i == 0:
- s = 1
- else:
- s = json_comment['more']
- response_comment = requests.get(comment_api.format(genres,s),headers = headers)
- json_comment = response_comment.text
- json_comment = json.loads(json_comment)
- n = len(json_comment['games'])
- datas = pd.DataFrame(index = range(n),columns = col)
- for j in range(n):
- datas.loc[j,'name'] = json_comment['games'][j]['title']
- datas.loc[j,'star'] = json_comment['games'][j]['star']
- datas.loc[j,'rating'] = json_comment['games'][j]['rating']
- datas.loc[j,'platforms'] = json_comment['games'][j]['platforms']
- datas.loc[j,'n_ratings'] = json_comment['games'][j]['n_ratings']
- datas.loc[j,'genres'] = json_comment['games'][j]['genres']
- datas.loc[j,'content'] = json_comment['games'][j]['review']['content']
- i += 1
- dataall = pd.concat([dataall,datas],axis = 0)
- print('已完成 {}% !'.format(round(i/num*100,2)))
- time.sleep(0.5)
- dataall = dataall.reset_index(drop = True)
- dataall['type'] = id_all1[genres]
- return dataall
- id_all = {"动作":1,"角色扮演" :5,"横版过关" :41,"冒险" :4,"射击": 48,"第一人称射击":32,
- "策略":2,"益智":18,"模拟":7,"体育":3,"竞速":6,"格斗":9,"乱斗/清版":37,"即时战略":12,"音乐/旋律":19}
- id_all1 = {1:"动作",5:"角色扮演",41:"横版过关",4:"冒险",48:"射击",32:"第一人称射击",
- 2:"策略",18:"益智",7:"模拟",3:"体育",6:"竞速",9:"格斗",37:"乱斗/清版",12:"即时战略",
- 19:"音乐/旋律"}
- for i in list(id_all.values()):
- dataall = getDoubanGame(i)
- filename = '游戏类别_' + id_all1[i] +'.xlsx'
- filename = filename.replace('/','')
- dataall.to_excel(filename)
数据总览:
- dataall['n_platforms'] = dataall.platforms.apply(lambda x:len(str(x).split('/')))
- dataall['platform'] = dataall.platforms.apply(lambda x:str(x).split('/')[0].strip())
- sns.pairplot(dataall,diag_kind = 'kde')
- plt.show()
- data2 = dataall.dropna()
- sns.pairplot(data2,diag_kind = 'kde')
- plt.show()
游戏类型分析:
- """
- 各类型游戏分析
- """
- # 各类型游戏数
- num = len(dataall.name.unique())
- result = dataall.groupby('type').count()['name'].reset_index().sort_values('name',ascending = False)
- attr = list(result.type)
- v = list(np.round(result.name/num,3))
- pie = Pie()
- style = Style()
- pie_style = style.add(
- label_pos="center",
- is_label_show=True,
- label_text_color=None,
- is_legend_show = False
- )
- pie.add("",[attr[0],"其他"],[v[0],1-v[0]],radius=[18, 24],center = [10,20],**pie_style)
- pie.add("",[attr[1],"其他"],[v[1],1-v[1]],radius=[18, 24],center = [30,20],**pie_style)
- pie.add("",[attr[2],"其他"],[v[2],1-v[2]],radius=[18, 24],center = [50,20],**pie_style)
- pie.add("",[attr[3],"其他"],[v[3],1-v[3]],radius=[18, 24],center = [70,20],**pie_style)
- pie.add("",[attr[4],"其他"],[v[4],1-v[4]],radius=[18, 24],center = [90,20],**pie_style)
- pie.add("",[attr[5],"其他"],[v[5],1-v[5]],radius=[18, 24],center = [10,50],**pie_style)
- pie.add("",[attr[6],"其他"],[v[6],1-v[6]],radius=[18, 24],center = [30,50],**pie_style)
- pie.add("",[attr[7],"其他"],[v[7],1-v[7]],radius=[18, 24],center = [50,50],**pie_style)
- pie.add("",[attr[8],"其他"],[v[8],1-v[8]],radius=[18, 24],center = [70,50],**pie_style)
- pie.add("",[attr[9],"其他"],[v[9],1-v[9]],radius=[18, 24],center = [90,50],**pie_style)
- pie.add("",[attr[10],"其他"],[v[10],1-v[10]],radius=[18, 24],center = [10,80],**pie_style)
- pie.add("",[attr[11],"其他"],[v[11],1-v[11]],radius=[18, 24],center = [30,80],**pie_style)
- pie.add("",[attr[12],"其他"],[v[12],1-v[12]],radius=[18, 24],center = [50,80],**pie_style)
- pie.add("",[attr[13],"其他"],[v[13],1-v[13]],radius=[18, 24],center = [70,80],**pie_style)
- pie.add("",[attr[14],"其他"],[v[14],1-v[4]],radius=[18, 24],center = [90,80],**pie_style)
- pie.render('各类型游戏数.html')
- # 各类型游戏均分
- c_schema= [( "乱斗/清版",10),
- ( "体育",10),
- ( "冒险",10),
- ( "动作",10),
- ( "即时战略",10),
- ( "射击",10),
- ( "格斗",10),
- ( "模拟",10),
- ( "横版过关",10),
- ( "益智",10),
- ( "竞速",10),
- ( "第一人称射击",10),
- ( "策略",10),
- ( "角色扮演",10),
- ( "音乐/旋律",10)]
- result1 = dataall.rating.fillna(0).groupby(dataall.type).mean().reset_index()
- result2 = dataall.rating.dropna().groupby(dataall.dropna().type).mean().reset_index()
- v1 = [result1.rating.apply(lambda x:round(x,1)).tolist()]
- v2 = [result2.rating.apply(lambda x:round(x,1)).tolist()]
- radar = Radar()
- radar.config(c_schema)
- radar.add("游戏均分(无评分视为0)", v1, is_splitline=True, is_axisline_show=True,is_label_show = True)
- radar.add("游戏均分(删除无评分)", v2, label_color=["#4e79a7"],item_color="#f9713c",is_label_show = True)
- radar.render('各类型游戏评分.html')
- # 各类型游戏评分人数
- result1 = dataall.n_ratings.fillna(0).groupby(dataall.type).mean().reset_index()
- result2 = dataall.n_ratings.dropna().groupby(dataall.dropna().type).mean().reset_index()
- attr = result1.type.tolist()
- v1 = np.round(result1.n_ratings.tolist(),1)
- v2 = np.round(result2.n_ratings.tolist(),1)
- line = Line()
- #line.add(x_axis = attr,y_axis = xaxis_type = 'category')
- line.add("包含无评分", attr, v1, mark_point=["max"],is_label_show = True)
- line.add("不包含无评分", attr, v2, is_smooth=True, mark_point=["max"],is_label_show = True,xaxis_rotate = 30)
- line.render('各类型游戏-评分人数.html')
游戏平台分析:
- """
- 游戏平台分析
- """
- # 各平台游戏数
- num = len(dataall.name.unique())
- result = dataall.groupby('platform').count()['name'].reset_index()
- name = result.platform.tolist()
- value = result.name.tolist()
- wordcloud = WordCloud(width=1300, height=620)
- wordcloud.add("", name, value, word_size_range=[20, 120])
- wordcloud.render('游戏平台.html')
- platforms = result.loc[result.name >100,'platform'].tolist()
- dataall.platform = dataall.platform.apply(lambda x:x if x in platforms else '其他')
- result = dataall.groupby('platform').count()['name'].reset_index().sort_values('name',ascending = False).reset_index(drop = True)
- attr = result.platform
- v1 = result.name
- pie = Pie('各平台游戏数',title_pos = 'center',title_text_size = 20)
- pie.add(
- "",
- attr,
- v1,
- radius=[40, 75],center = [50,60],
- label_text_color=None,is_legend_show = False,
- is_label_show=True
- )
- pie.render('各平台游戏数.html')
- # 各平台游戏评分人数
- result1 = dataall.n_ratings.fillna(0).groupby(dataall.platform).mean().reset_index()
- result2 = dataall.n_ratings.dropna().groupby(dataall.dropna().platform).mean().reset_index()
- attr = result1.platform.tolist()
- v1 = np.round(result1.n_ratings.tolist(),1)
- v2 = np.round(result2.n_ratings.tolist(),1)
- line = Line()
- #line.add(x_axis = attr,y_axis = xaxis_type = 'category')
- line.add("包含无评分", attr, v1, mark_point=["max"],is_label_show = True)
- line.add("不包含无评分", attr, v2, is_smooth=True, mark_point=["max"],is_label_show = True,xaxis_rotate = 70)
- line.render('各平台游戏-评分人数.html')
- # 各平台游戏均分
- result1 = dataall.rating.fillna(0).groupby(dataall.platform).mean().reset_index()
- result2 = dataall.rating.dropna().groupby(dataall.dropna().platform).mean().reset_index()
- attr = result1.platform.tolist()
- v1 = np.round(result1.rating.tolist(),1)
- v2 = np.round(result2.rating.tolist(),1)
- line = Line()
- #line.add(x_axis = attr,y_axis = xaxis_type = 'category')
- line.add("包含无评分", attr, v1, mark_point=["max"],is_label_show = True)
- line.add("不包含无评分", attr, v2, is_smooth=True, mark_point=["max"],is_label_show = True,xaxis_rotate = 70)
- line.render('各平台游戏-均分.html')
游戏名称分析:
- """
- 标题分析
- """
- # 分词
- import re
- stopwords = open('中文停用词表(比较全面,有1208个停用词).txt','r').read()
- stopwords = stopwords.split('\n')
- texts = ''.join(dataall.name.tolist())
- texts =''.join(re.findall(r'[\u4e00-\u9fa5]',texts))
- result = jieba.cut(texts,cut_all=False)
- allwords = [word for word in result if len(word)>1 and word not in stopwords]
- result = pd.DataFrame(allwords)
- result.columns =['word']
- res = result.word.groupby(result.word).count()
- res.index.name = 'text'
- res = res.reset_index()
- res = res.loc[res.word >= 10].reset_index(drop = True)
- # 标题词云
- name = res.text.tolist()
- value = res.word.tolist()
- wordcloud = WordCloud(width=1300, height=620)
- wordcloud.add("", name, value, word_size_range=[10, 80])
- wordcloud.render('游戏名称高频词.html')
高分游戏汇总:
- """
- 高rating游戏分析
- """
- data1 = dataall.loc[dataall.rating>=9.5]
- result = data1.groupby('type').count()['name'].reset_index().sort_values('name',ascending = False).reset_index(drop = True)
- attr = result.type
- v1 = result.name
- pie = Pie('9.5分以上游戏',title_pos = 'center',title_text_size = 20)
- pie.add(
- "",
- attr,
- v1,
- radius=[40, 75],center = [50,60],
- label_text_color=None,is_legend_show = False,
- is_label_show=True
- )
- pie.render('高评分游戏-分类型.html')
- data1['title'] = data1.name.apply(lambda x:str(x).split(':')[0].split(' ')[0])
- # 9.5以上评分,评分人数超过1000
- result = data1.loc[data1.n_ratings >= 100,['name','genres','content','platforms','rating','n_ratings']].drop_duplicates().reset_index(drop = True)
- result = result.sort_values(by = ['n_ratings','genres'],ascending = False).reset_index(drop = True)
- result.to_excel('评分9.5以上游戏.xlsx')
这篇关于Python 爬取 3 万条游戏评分数据,找到了程序员最爱玩的游戏(附代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






