本文主要是介绍快速导入100万条Excel数据到MySql,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
因业务需要,将100万条Excel数据导入MySql
OS : CentOS7 , MySql 5.7
做了2个纯命令导入测试,不考虑phpmyadmin,navicate导入.
首先MySql调整全局变量
set max allowed packet =104857600 (100Mb)
set wait_timeout=288000
set interactive timeout=288000此次是直接在将文件放在server上,所以只调整上面三个.
远程调用可能还 需要调整,
bulk_insert_buffer_size=120M
MYISAM_SORT_BUFFER_SIZE=104857600 ;
KEY_BUFFER_SIZE=256217728
对于有主键的需要先关闭alter table ${table_name} disable keys;
1 将excel 做成sql批量数据插入语句,没错values后有100万条.
insert.txt 共有40MB. 生成sql语句格式如下
CONCATENATE("insert into 表名 (列1,列2,列3) values ('",A1,"','",B1,"','",C1,"');")
分别使用Myisam,Innodb引擎和Source命令
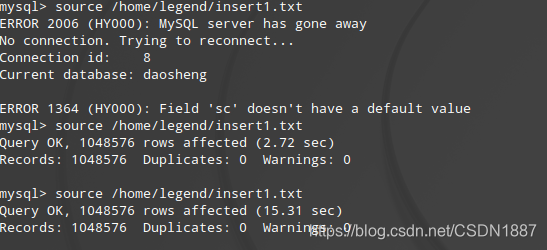
如果不修改 max allowed packet 默认值就会出现 Server gone away.
Myisam引擎具有明显优势,只花了2.72sec
2 将excel数据另存为csv, 使用Utf-8编码,生成insert2.csv 36Mb ,100万行 .
将insert2.csv拷贝到 /var/lib/mysql-file/
使用load data in file 导入
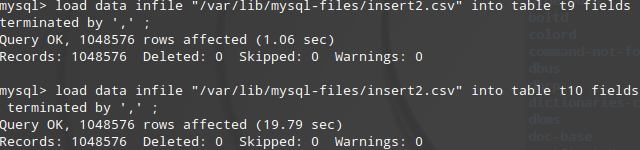
Myisam引擎依然具有明显优势,这次只花了1.06sec,
结论如下,导入数据时使用Myisam引擎更有优势,后多次测试load data 效率比 source耗时更短.
(仔细思考后觉得,命令执行也许不存在差距,关键在2种文件格式,csv更简洁)
这篇关于快速导入100万条Excel数据到MySql的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









