本文主要是介绍MySQL 插入10万条数据性能分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL 插入10万条数据性能分析
一、背景
笔者想复现一个索引失效的场景,故需要一定规模的数据作支撑,所以需要向数据库中插入大约一百万条数据。那问题就来了,我们应该怎样插入才能使插入的速度最快呢?
为了更加贴合实际,下面的演示只考虑使用 Mybaits 作为 ORM 框架的情况,不使用原生的 JDBC。下面,我们只向数据库中插入十万条数据作为演示。
二、实现
1. 使用 Mybaits 直接插入
Java 代码为:
public void insertByMybatis() {for (int i = 0; i < 100000; i++) {InvoiceOrder invoiceOrder = new InvoiceOrder();invoiceOrder.setOrderId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceName("test" + i);invoiceOrder.setInvoiceDate(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));invoiceOrder.setOrderTime(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));orderMapper.insertSelective(invoiceOrder);}
}
插入结果:

同步插入10万条数据的耗时为 242s
2. 使用 Mybatis 直接插入数据,取消事务自动提交
@Autowired
private DataSourceTransactionManager transactionManager;public void insertByMybatisWithNoTransaction() {DefaultTransactionDefinition def = new DefaultTransactionDefinition();def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);TransactionStatus status = transactionManager.getTransaction(def);for (int i = 0; i < 100000; i++) {InvoiceOrder invoiceOrder = new InvoiceOrder();invoiceOrder.setOrderId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceName("test" + i);invoiceOrder.setInvoiceDate(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));invoiceOrder.setOrderTime(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));orderMapper.insertSelective(invoiceOrder);}transactionManager.commit(status);
}
插入结果:

直接插入数据,并取消事务自动提交,耗时为 28s
3. 使用 Mybatis 批量插入数据
Java 代码为:
/*** Mybatis批量插入*/
public void batchInsertByMybatis() {List<InvoiceOrder> invoiceOrders = new ArrayList<>();for (int i = 0; i < 100000; i++) {InvoiceOrder invoiceOrder = new InvoiceOrder();invoiceOrder.setOrderId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceName("test" + i);invoiceOrder.setInvoiceDate(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));invoiceOrder.setOrderTime(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));invoiceOrders.add(invoiceOrder);if (i % 1500 == 0) {orderMapper.insertBatch(invoiceOrders);invoiceOrders = new ArrayList<>();}}// 最后插入剩下的数据orderMapper.insertBatch(invoiceOrders);
}
结果:

批量插入10条数据耗时 4s
4. 使用 Mybatis 批量插入数据,取消事务自动提交
@Autowired
private DataSourceTransactionManager transactionManager;public void batchInsertByMybatisWithNoTransaction() {DefaultTransactionDefinition def = new DefaultTransactionDefinition();def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);TransactionStatus status = transactionManager.getTransaction(def);List<InvoiceOrder> invoiceOrders = new ArrayList<>();for (int i = 0; i < 100000; i++) {InvoiceOrder invoiceOrder = new InvoiceOrder();invoiceOrder.setOrderId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceName("test" + i);invoiceOrder.setInvoiceDate(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));invoiceOrder.setOrderTime(DateUtil.date().offset(DateField.HOUR_OF_DAY, -i));invoiceOrders.add(invoiceOrder);if ( i % 10000 == 0) {orderMapper.insertBatch(invoiceOrders);invoiceOrders = new ArrayList<>();}}// 最后插入剩下的数据orderMapper.insertBatch(invoiceOrders);transactionManager.commit(status);
}
结果为:

耗时4s,与批量插入自动提交事务方式的耗时相差不大
5. 使用多线程批量插入数据
public void asyncInsertTest() throws InterruptedException {for (int i = 0; i < THREAD_COUNT; i++) {int finalI = i;threadPoolExecutor.submit(new Runnable() {@Overridepublic void run() {List<InvoiceOrder> invoiceOrders = new ArrayList<>();int begin = finalI * 20000;int end = 20000 * (finalI + 1);for (int id = begin; id < end; id++) {InvoiceOrder invoiceOrder = new InvoiceOrder();invoiceOrder.setId((long) id);invoiceOrder.setOrderId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceId(UUID.randomUUID().toString().replace("-", ""));invoiceOrder.setInvoiceName("test" + id);invoiceOrder.setInvoiceDate(DateUtil.date().offset(DateField.HOUR_OF_DAY, -id));invoiceOrder.setOrderTime(DateUtil.date().offset(DateField.HOUR_OF_DAY, -id));invoiceOrders.add(invoiceOrder);}orderMapper.insertBatch(invoiceOrders);}});}threadPoolExecutor.shutdown();while (!threadPoolExecutor.isTerminated()) {Thread.sleep(100); // 等待线程池中的任务执行完毕}}
结果为:

耗时 3s,与同步插入相比,有很大的性能提升,这里的每条线程都是使用批量插入的模式,一次事务提交。
6. 使用 第三方数据库连接池插入数据
SpringBoot 中默认使用的数据库连接池是 Hikari,这里我们换用 Druid 和 c3p0 连接池,同步插入10万条数据。
6.1 使用 Druid 连接池插入数据
Druid 依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version>
</dependency>
配置 Druid 文件信息
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/test_db?characterEncoding=utf-8&serverTimezone=Hongkong&useSSL=falseusername: rootpassword: ezrealtype: com.alibaba.druid.pool.DruidDataSourceserver:port: 8080
结果如下:
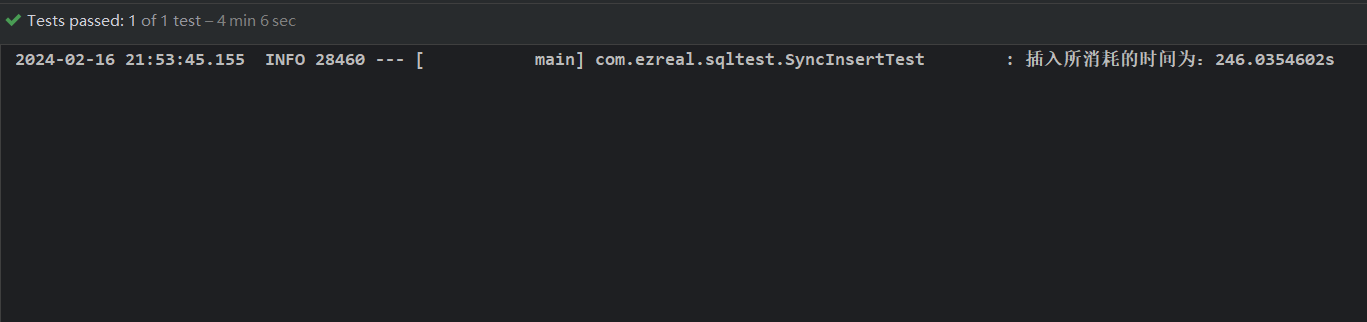
- 与使用 Hikari 连接池相比,Hikari 耗时 242s,Druid 耗时 246s 两者相差不大;
6.2 使用 c3p0 连接池插入数据
c3p0 依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version>
</dependency>
配置 c3p0 文件信息
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/test_db?characterEncoding=utf-8&serverTimezone=Hongkong&useSSL=falseusername: rootpassword: ezrealtype: com.alibaba.druid.pool.DruidDataSourceserver:port: 8080
结果为:
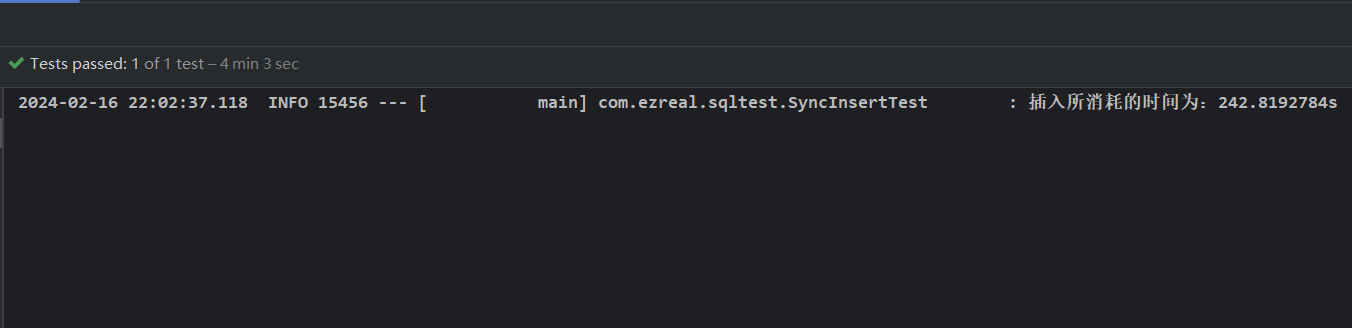
- 与使用 Hikari 连接池相比,Hikari 耗时 242s,c3p0 耗时 242s 两者相差不大;
三、结果比较分析
3.1 单次循环插入和批量插入
对比方式 1 和 方式 3,前者是单次循环插入,后者是批量插入,分别耗时 242s 和 4s,显然批量插入的效率高。
这个问题可以分三个方面网络、数据库交互、事务、索引分析:
- 网络:客户端每次与数据库交互,都要进行一次 TCP 三次握手和四次挥手,频繁的建立和释放数据库连接增加了数据库负担;
- 数据库交互:在建立网络连接后,数据库要进行一系列的准备工作:查询缓存、语法分析、词法分析、优化器分析、存储引擎执行 SQL;
- 事务:每次数据插入操作都会开启一个事务,频繁的开启和提交事务,也会增加数据库的负担;
- 索引:如果插入的字段存在对应的二级索引,那么就要在该二级索引上也要添加上对应的数据,涉及到大量的磁盘操作;
对于索引来说,可能会存在页分裂和页合并的情况,比如说插入时数据库的主键不是自增的。
对于单次循环插入,每次都需要重复以上三个方面的内容,非常影响性能;而对于批量插入来说,每次操作大量的数据,减少网络、数据库交互、事务等操作,提高插入的效率;
3.2 事务自动提交分析
对比方式 1 和 方式 2,前者是每次插入就进行一次事务操作,而后者是提前开启事务,等到所有的数据都 insert 后,再提交事务,前者耗时 242s,后者耗时 28s,显然只进行一次事务操作的插入效率高。
3.2.1 事务执行流程
回答这个问题之前,我们需要了解一次事务执行的流程,以 insert 操作为例:
- 向 buffer pool 中写入数据,将数据写入到 flush 链表中,由后台线程定时同步到磁盘上;
- 记录 undo log buffer ,数据插入之前,InnoDB 会在 Undo Log 记录对应的 delete 语句,用于在生事务回滚的情况下,将修改操作回滚到插入前的状态,undo log 先写入到 undo log buffer 中,由后台线程定时落盘;
- 记录 redolog buffer,InnoDB 在 buffer pool 插入数据的同时,会把操作记录写入到 redolog buffer 中;
- 提交事务,InnoDB 会把 redo log 从 redolog buffer 写入到磁盘中(顺序写入),此时 redolog 处于 prepare 状态,接着执行器生成这个操作的 binlog 写入磁盘,最后把刚刚 redo log 改为 commit 状态,数据插入成功,这就是所谓的二阶段提交;
这里主要涉及到两处内存操作和两处磁盘操作:
-
将 undolog 写入到 undolog buffer 中;
-
将 redolog 写入到 redolog buffer 中;
-
在事务提交后,InnoDB 会把 redo log 从 redolog buffer 写入到磁盘中;
-
将该操作的 binlog 也写入到磁盘中
所以,对于方式1,每一次插入数据都要进行两次的磁盘 IO,然而磁盘的读取速度是非常耗时的,大量的磁盘 IO就会影响插入的性能。如果能够减少大量的磁盘 IO,即减少事务开启的次数,那么就可以大大减少插入的耗时。
3.2.2 事务操作涉及到的锁
涉及到事务就可能会涉及到锁的竞争。一个事务在插入一条记录时需要判断一下插入位置是不是被别的事务加了所谓的 gap lock,如果有的话,插入操作就需要等待,直到拥有 gap lock 的事务释放了锁。
InnoDB 规定,在上述等待过程中,会在内存中生成一个锁结构,表明有事务想在间隙中插入一条新记录,但是现在在等待。所以 InnoDB 就把这种类型的锁名称命名为
Insert Intention Locks,我们称为插入意向锁。
3.3 多线程插入优化
通过并发执行多个插入操作来提高数据插入效率:
- 并发执行:利用多核处理器的优势,通过多个线程并发执行插入操作,提高系统的吞吐量;
- 减少锁竞争:多个线程批量插入,类似分段的思想,不同线程只会操作不同的数据段,减少不同线程的锁竞争;
3.4 数据库连接池的选择
至于数据库连接池的选择,这里提供一份大佬写的文章,里面详细比较了常见数据库连接池的性能测试。
这篇关于MySQL 插入10万条数据性能分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





