本文主要是介绍SQLServer 分页分页查询优化方案,1秒内查询20万条数据的表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在做sql分页查询的话,发现数据表中的数据量非常大的话,使用count(*)去统计行数的话,还是非常慢的。20多万条数据的表,用count查询,大概在9秒左右。
服务器是4核8G内存的。5秒左右的时间,还是比较难以接受的,9秒时间的SQL语句如下所示:
/****** SSMS 的 SelectTopNRows 命令的脚本 ******/
SELECT count(*) as total FROM [Chint.Hygiene].[dbo].[tb_UserTemperatureInfo] /****** SSMS 的 SelectTopNRows 命令的脚本 ******/
SELECT *FROM [Chint.Hygiene].[dbo].[tb_UserTemperatureInfo] order by ID offset 30 rows fetch next 100 rows only上面这个SQL查询效果如下图所示:
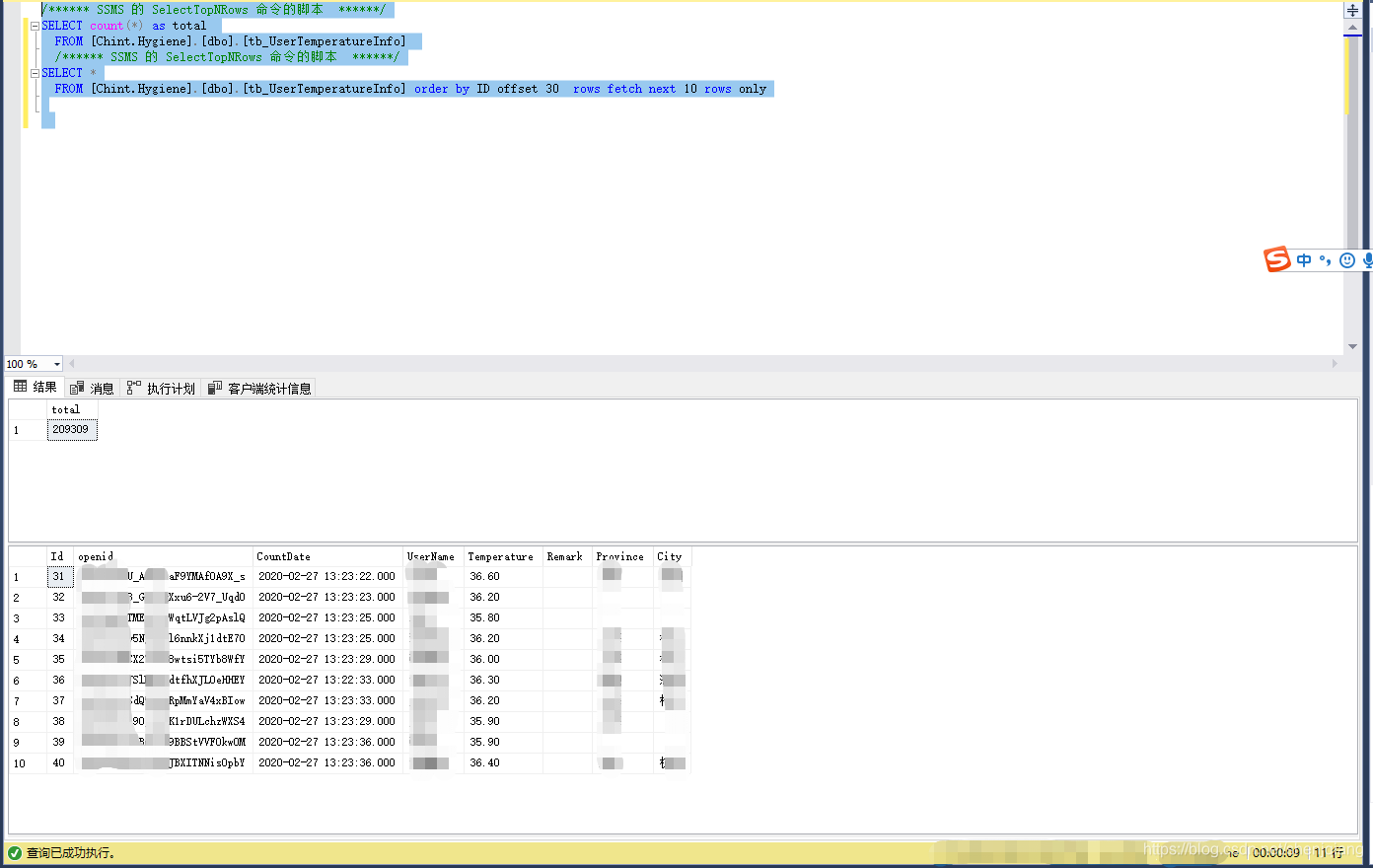
上图可以看出,20多万条的数据,使用上面的语句写的话,用了9秒的时间,下面我们来看看上面的SQL的执行计划:
这篇关于SQLServer 分页分页查询优化方案,1秒内查询20万条数据的表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



