yolov3专题

目标检测-YOLOv3
YOLOv3介绍 YOLOv3 (You Only Look Once, Version 3) 是 YOLO 系列目标检测模型的第三个版本,相较于 YOLOv2 有了显著的改进和增强,尤其在检测速度和精度上表现优异。YOLOv3 的设计目标是在保持高速的前提下提升检测的准确性和稳定性。下面是对 YOLOv3 改进和优势的介绍,以及 YOLOv3 核心部分的代码展示。 相比 YOLOv2 的改进
828华为云征文|采用华为云Flexus云服务器X实例部署YOLOv3算法完成目标检测
文章目录 一、前言1.1 开发需求1.2 Flexus云服务器介绍1.3 YOLOv3目标检测算法1.4 客户端开发思路1.5 客户端运行效果 二、服务器选购2.1 登录官网2.2 选购服务器2.3 选择服务器区域2.4 选择服务器规格2.5 选择系统镜像2.6 选择存储盘2.7 配置密码2.8 配置云备份2.9 确认配置2.10 立即购买2.10 后台控制台 三、服务器登录3.1 查看服务

深度学习从入门到精通——yolov3算法介绍
YOLO v3 论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf论文:YOLOv3: An Incremental Improvement 先验框 (10×13),(16×30),(33×23),(30×61),(62×45),(59× 119), (116 × 90), (156 × 198),(373 × 326) ,顺序

【目标检测】YOLOV3
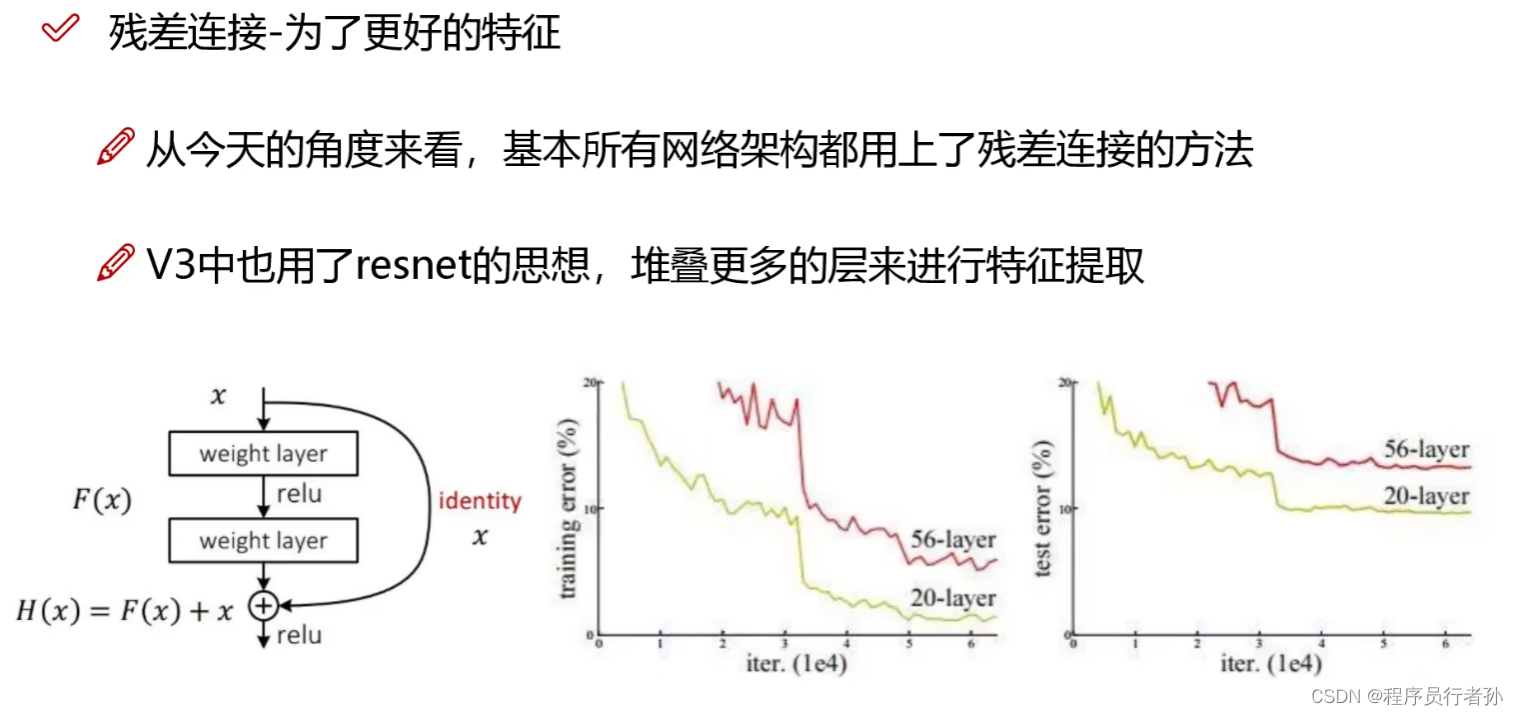
YOLOv3: An Incremental Improvement 1、YOLO V3 Structure YOLO V3 网络结构借鉴类似 ResNet(残差网络结构)和 FPN(Feature Pyramid Networks)网络结构方式。 残差网络:残差网络通过在网络中引入跳跃连接(shortcut connections)来构建残差块(residual blocks)。这
yolov3 上生产
1、在生产环境上编译darknet,执行make命令就好哦。 通过以后,拿到libdarknet.so 2、改一改../python/darknet.py文件 3、把darknet里的四个模型文件地址改一改就可以了 后面我会写一篇详细的,今天我要回家了
12_YouOnlyLookOnce(YOLOv3)新一代实时目标检测技术
1.1 回顾V1和V2 V1:05_YouOnlyLookOnce(YOLOV1)目标检测领域的革命性突破-CSDN博客 V2:07_YouOnlyLookOnce(YOLOv2)Better,Faster,Stronger-CSDN博客 1.2 简介 YOLOv3(You Only Look Once version 3)是YOLO系列目标检测算法的第三代版本,由Joseph Redmo

9.1.3 简单介绍单阶段模型YOLO、YOLOv2、YOLO9000、YOLOv3的发展过程
9.1.3 简单介绍单阶段模型YOLO、YOLOv2、YOLO9000、YOLOv3的发展过程 前情回顾:9.1.2 简单介绍两阶段模型R-CNN、SPPNet、Fast R-CNN、Faster R-CNN的发展过程 摘要 YOLOYOLOv2YOLO9000YOLOv3基本思想使用一个端到端的卷积神经网络直接预测目标的类别和位置针对YOLOv1的两个缺点进行改进可以实时地检测超过9

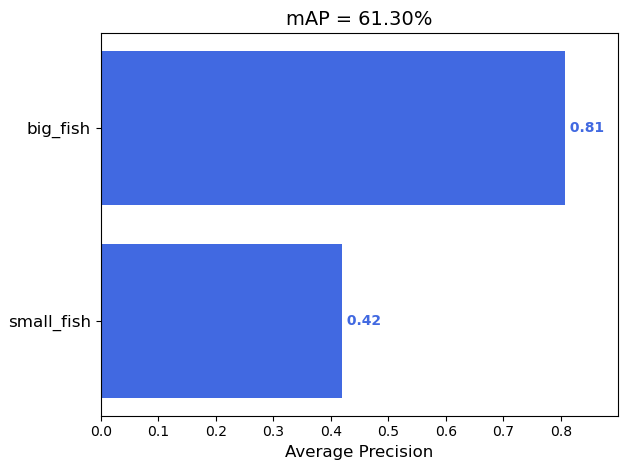
YOLOv3+mAP实现金鱼检测
YOLOv3+mAP实现金鱼检测 Git源码地址:传送门 准备数据集 按帧数读取视频保存图片 video2frame.py使用labelimg标注工具对图片进行标注统一图片大小为 416x416,并把标签等信息写成.xml文件 conver_point.py读取缩放后的标签图片,转为左上角右下角坐标信息 voc2yolo_v3.py 自定义数据集 分析 准备数据集 使用标注工具(
探索YoloV3源码
文章目录 准备数据训练参数创建模型模型优化保存模型学习率早期停止 样本数量训练 模型入口逻辑 网络网络Darknet特征图**13x13检测图****26x26检测图****52x52检测图** 真值fit_generator数据生成器图片和标注框真值y_true Loss损失层参数预测数据损失函数 预测**检测函数**YOLO参数输出封装YOLO评估检测方法 补充1. IoU2. 冻结网

YOLOv3实践darknet跑voc数据集的问题
最近在用YOLOv3的darknet训练VOC数据集,初学小白的我对参数,源码还在了解层面,但是结果已经训练开始之后发现IoU出现了nan值循环。所以就开始网上寻找。总结在下: 参考:https://blog.csdn.net/lilai619/article/details/79695109#commentsedit 如何训练自己的数据 说明: (1)平台 linux + 作者官方代码

YOLOv3配置文件源码详解
YOLOv3的配置文件,其中需要注意的是数据增强的方式,有两个,一个是 角度旋转+饱和度+曝光量+色调,外加jitter,随即调整宽高比的范围。之后需要注意的就是 3个尺度的box的mask。后续要知道他们是怎么整合起来的 [net]# Testing# batch=1# subdivisions=1# Trainingbatch=64 #训练样本样本数subdivisions=1
使用DeepStream5.0部署YOLOV3,并实现多路拉流、自定义模型
一、前言 本文介绍基于DeepStream5.0和YoloV3目标检测模型来实现车辆和行人检测的部署过程。在第二部分介绍依赖的环境;第三、四部分介绍YoloV3的样例工程和编译运行过程;第五部分介绍如何实现多路拉流;第六部分介绍如何自定义YOLOV3模型;最后是小结和参考资料。 希望本文尽可能的详细和清晰,让大家在动手尝试过程中少走弯路,一步到位。 二、环境准备 Cuda10.2Jetpa
YOLOv3模型在不同硬件平台上的性能表现有何差异?
YOLOv3模型在不同硬件平台上的性能表现可能会有显著差异,这主要受到以下因素的影响: 1. 计算能力:高性能的GPU(如NVIDIA的高端系列)或ASIC(如Google的TPU)可以更快地处理复杂的神经网络运算,从而提高YOLOv3的推理速度。 2. 硬件架构:不同的硬件架构(如CPU、GPU、FPGA、ASIC)对并行处理和浮点运算的支持程度不同,这会影响模型的运行效率。 3. 内存带
目标检测算法YOLOv3简介
YOLOv3由Joseph Redmon等人于2018年提出,论文名为:《YOLOv3: An Incremental Improvement》,论文见:https://arxiv.org/pdf/1804.02767.pdf ,项目网页:https://pjreddie.com/darknet/yolo/ 。YOLOv3是对YOLOv2的改进。 以下内容主要来自论文:
YOLOv3的NMS参数调整对模型的准确率和召回率分别有什么影响?
YOLOv3中的非极大值抑制(Non-Maximum Suppression, NMS)是一种关键的后处理步骤,用于从模型的预测中去除重叠的边界框,从而提高检测的准确性。NMS参数的调整直接影响到模型的准确率(Precision)和召回率(Recall),具体如下: 1. NMS阈值(`nms_thresh`): - 提高NMS阈值:会减少被抑制的边界框数量,从而保留更多的边界框。这可能会

YOLOv3_目标检测
YOLOv3_目标检测 YOLOv1最初是由Joseph Redmon实现的,和大型NLP transformers不同,YOLOv1设计的很小,可为设备上的部署提供实时检测速度。 YOLO-9000是Joseph Redmon实现的第二个版本YOLOv2目标检测器,它对YOLOv1做了很多技巧上的改进,并强调该检测器能够推广到检测世界上的任何物体。 YOLOv3对YOLOv2做了进一步的改
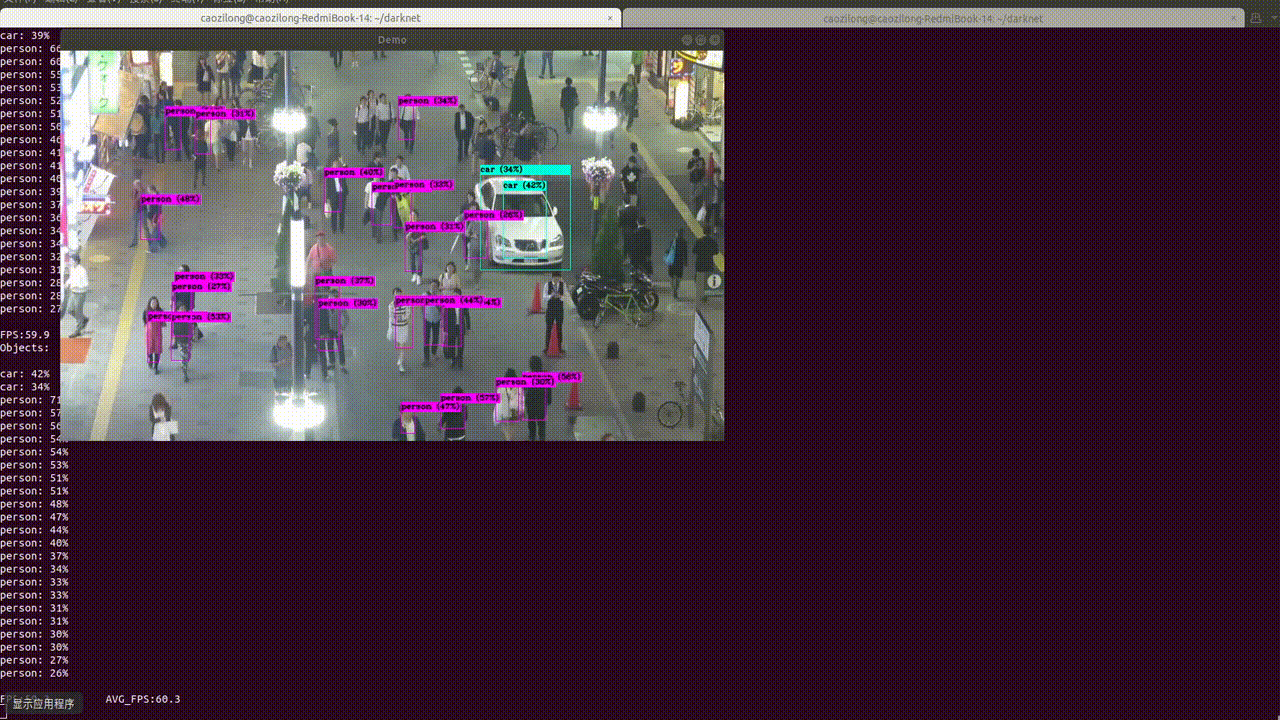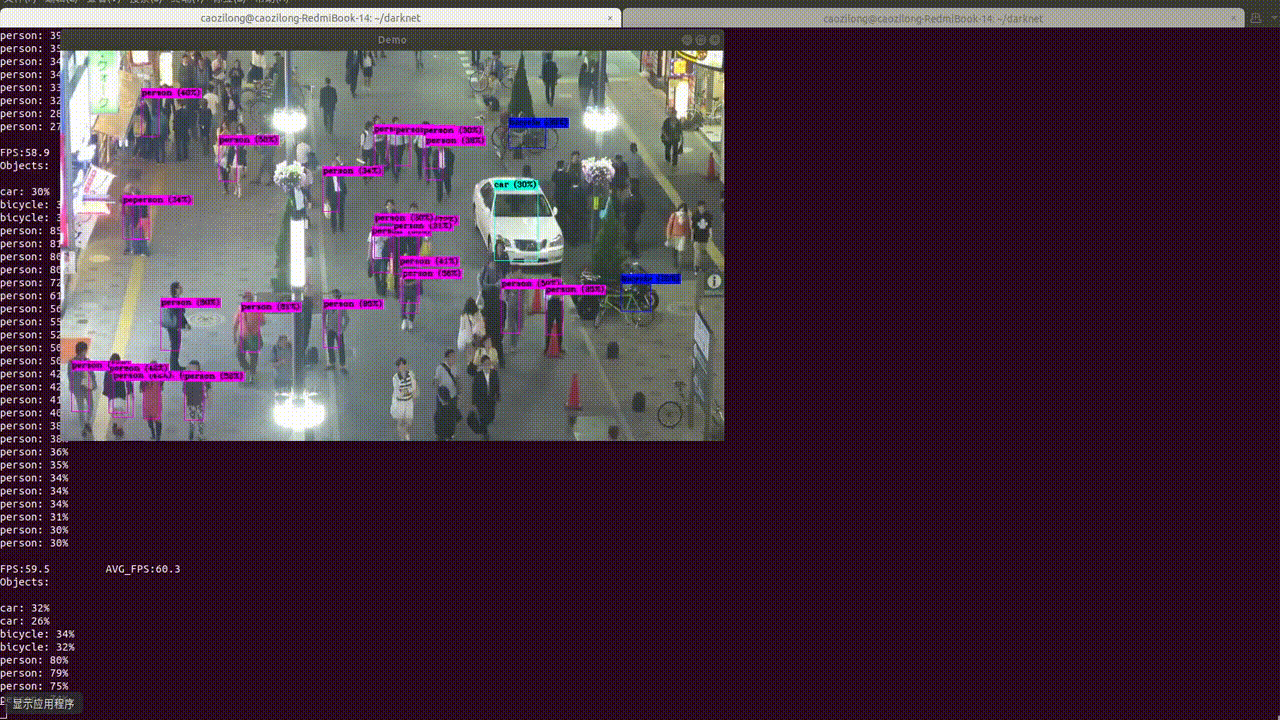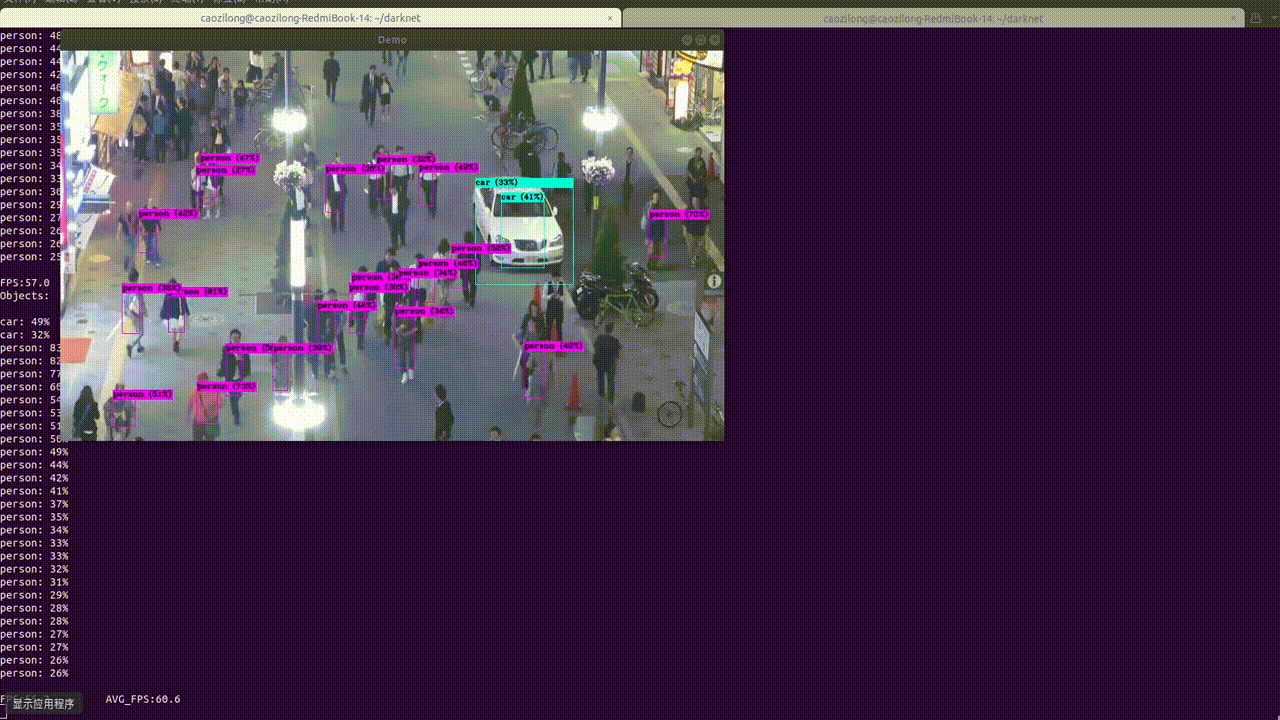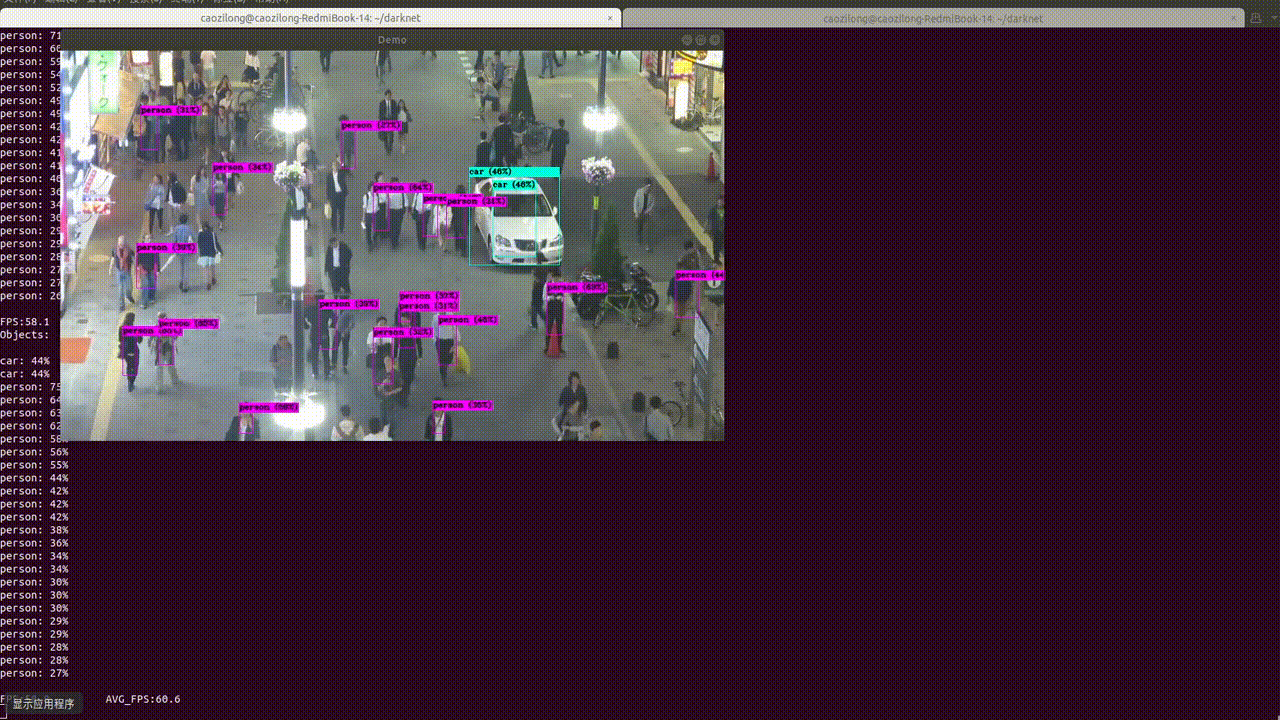
Yolov3框架目标检测推理环境测试
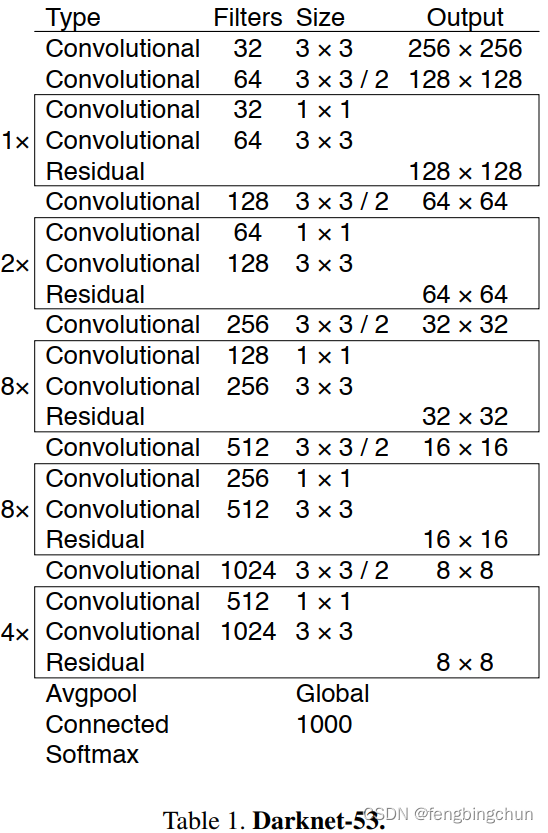
YOLO v3整体是一个106层的全卷积网络,包括了残差模块,上采样模块,检测模块。 1.Get darknet 代码 $ git clone https://github.com/pjreddie/darknet 我们暂时先不开GPU,先做推理,安装GPU环境是一个痛苦的过程: $ cd darknet$ make caozilong@caozilong-Vostro-3268:

YOLOv3没有比这详细的了吧
YOLOv3:目标检测基于YOLOv2的改进 在目标检测领域,YOLO(You Only Look Once)系列以其出色的性能和速度而闻名。YOLOv3作为该系列的第三个版本,不仅继承了前身YOLOv2的优势,还在多个方面进行了创新和改进。本文将深入探讨YOLOv3的架构、关键技术以及与YOLOv2相比所做的改进。 YOLOv3:在座的都是trash,不是针对谁,这图画的过分了?!! YOL
yolov3算法中关于loss={'yolo_loss': lambda y_true, y_pred: y_pred}的理解
yolov3算法中关于loss={‘yolo_loss’: lambda y_true, y_pred: y_pred}的理解 参考文献: (1)https://www.jianshu.com/p/7e45586c44be (2)https://blog.csdn.net/wangdongwei0/article/details/82563689?depth_1-utm_source=distr

调试yolov3代码如何进入 Lambda中的yolo_loss函数
调试yolov3代码如何进入 Lambda中的yolo_loss函数 参考文献:https://www.jianshu.com/p/6f8c86ac1fef 所用的yolov3代码: https://github.com/qqwweee/keras-yolo3 ,解压之后用pycharm打开。 理解代码一个很好的方法是调试程序,看看函数之间的调用关系以及各变量的变化。 在调试train.py代码
yolov3 代码中@wraps(Conv2D)的作用
标题yolov3 代码中@wraps(Conv2D)的作用 参考文献:https://blog.csdn.net/ltfdsy/article/details/81357280 在 keras-yolo3-master\yolo3\model.py 中,有如下代码: @wraps(Conv2D) def DarknetConv2D(*args, **kwargs): “”“Wrapper to

yolov3训练过程中输出参数详解
Region 16, Region 20表示两个不同尺度上检测的结果。 16卷积层为最大的预测尺度, 可以预测出较小的物体; 20卷积层为最小的预测尺度, 可以预测出较大的物体。 我们发现每次迭代都有两组Region 16, Region 20。 因为在darknet中,所有训练图片中的一个批次(batch)又被分成subdivision份来进行计算,而该训练过程 .cfg 文件中设置的bat
yolov3 darknet cfg配置文件参数详解
Darknet的cfg配置文件中,[xxx]表示网络的一层,其后的内容为该层的参数配置,[net]为特殊的层,用于配置整个网络,包含学习率,衰减系数等一系列超参数。 [net] # Testing# batch=1 #测试时,batch和subdivisions都必须设置为1,否则会出错# subdivisions=1# Trainingbatch

缺陷检测项目 | 基于YOLOv3实现的铝块表面缺陷检测算法
项目应用场景 面向铝板表面缺陷检测场景,使用深度学习算法来实现,项目检出效果好,检出缺陷种类丰富,支持不导电、擦花、角位漏底、桔皮、漏底、喷流、漆泡、起坑、杂色、脏点等十种缺陷。 项目效果 项目细节 ==> 具体参见项目 README.md (1) 数据集,来自 Alibaba Cloud TIANCHI (2) 主要的检测算法 ==> YOLOv3 (3) 数据增