本文主要是介绍yolov3 详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、yolov3原理
- 2、损失函数
- 3、yolov3改进
- 4、使用opencv实现yolov3
- 5、卷积神经网络工作原理
1、yolov3原理
参考视频
darknet53:52个卷积层和1个全联接层
输入图像为416416
1313 -》 下采样32倍
2626 -》 下采样16倍
5252 -》 下采样8倍
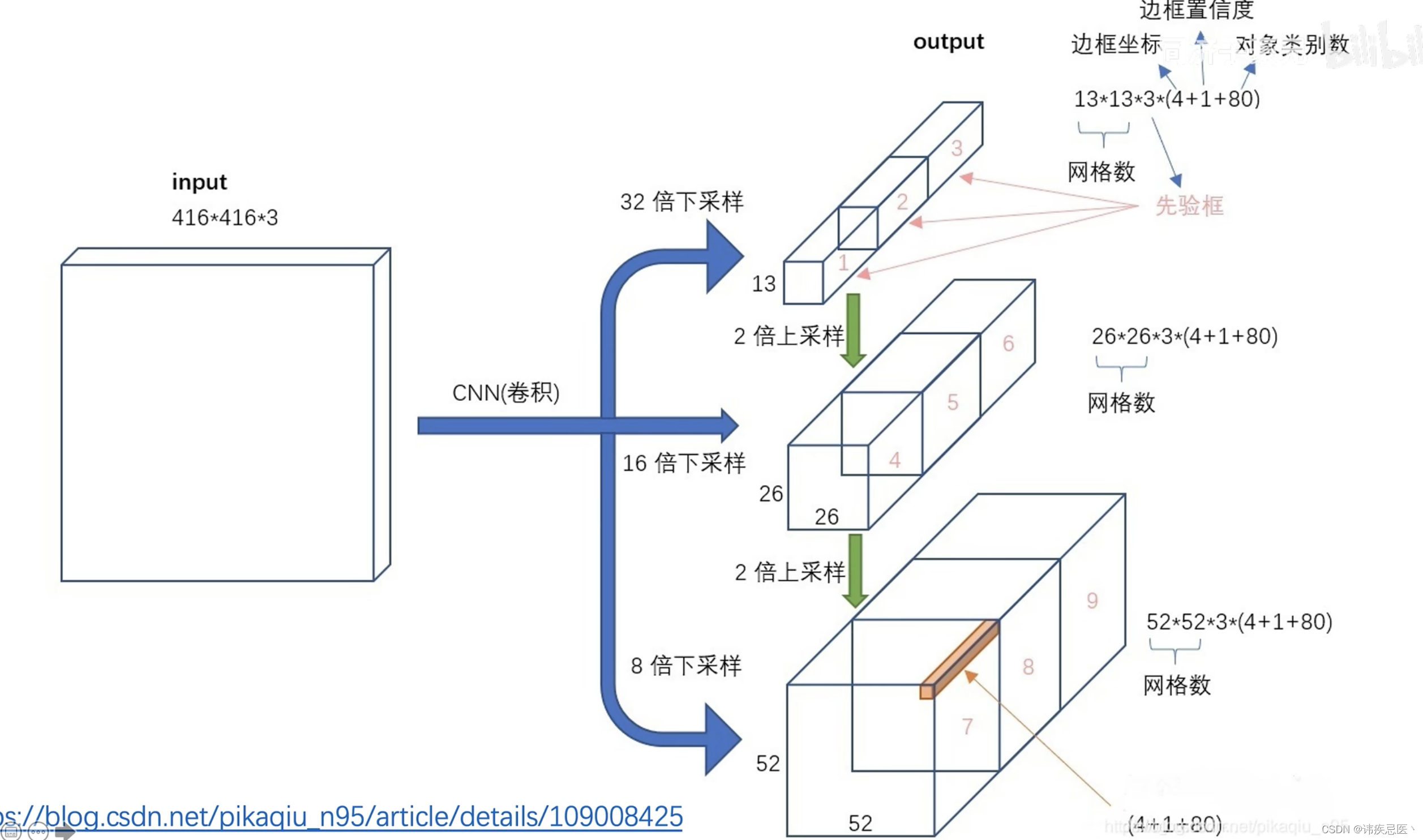
由标注框中心点落在的grid cell中与9个anchors,IOU最大那个去预测,也称正样本,其他非最大的就不是正样本。
正样本:anchors和标记框的IOU最大,他就是正样本
不参与:anchors和标记框的IOU高于某一个阈值,但是不是最大的就忽略
负样本:一个anchors和标记框的IOU小于某一个阈值,负样本
正样本会在所有项中计算损失产生贡献(定位、置信度、分类)
负样本产生贡献(置信度)

2、损失函数
1、每个格子是一个grid cell
2、虚线的黑框是anchors
3、实线的蓝框是预测框是以anchors为基准偏移的(以旁边公式)
由tx、ty、th、tw反向推理出来最终结果,sigmoid函数的意义保证输出是0-1之间
cx、cy是归一化之后的长宽
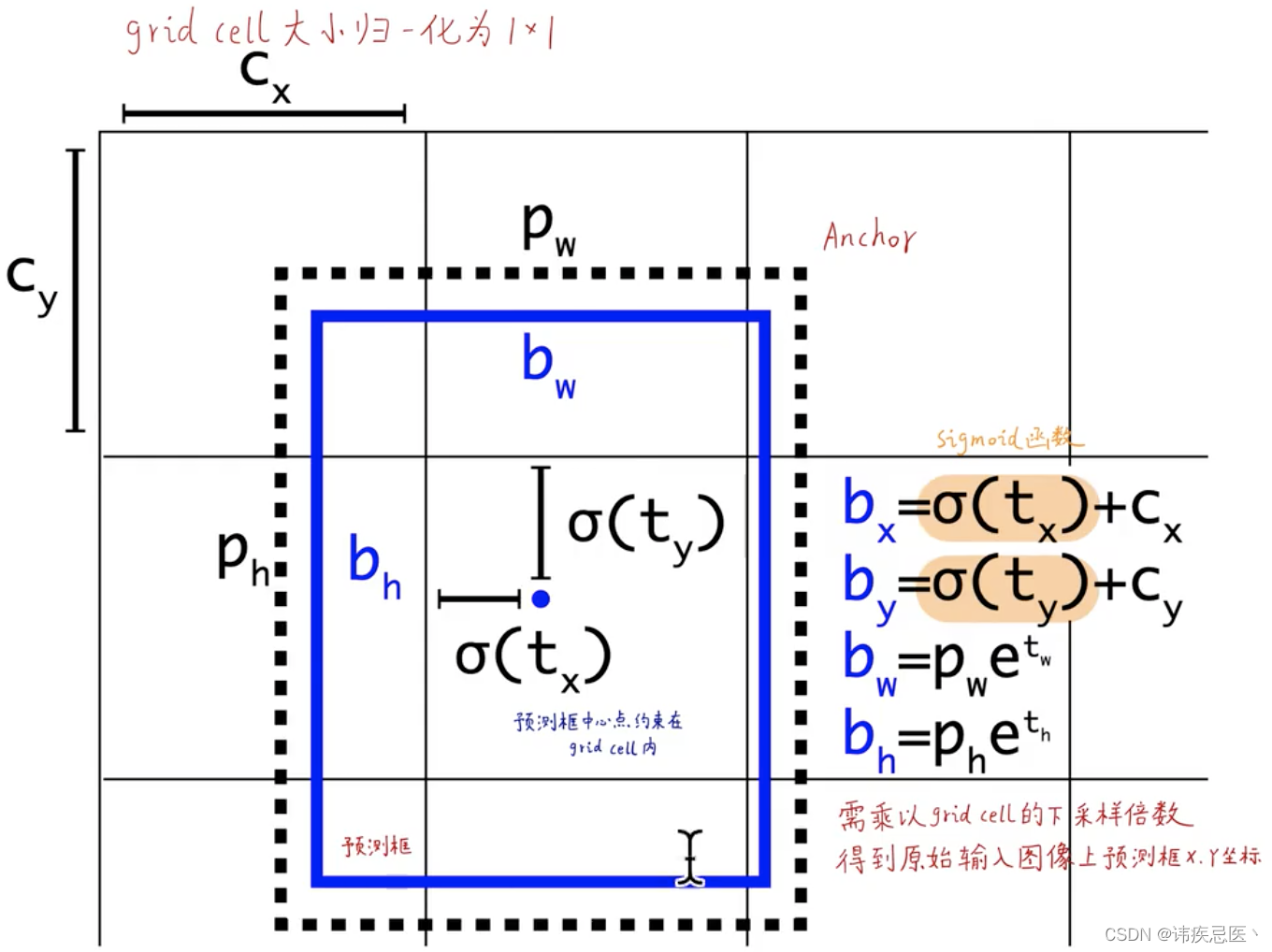
(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
σ:激活函数,论文作者用的是sigmoid函数,[0,1]之间概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值 ,图解如下

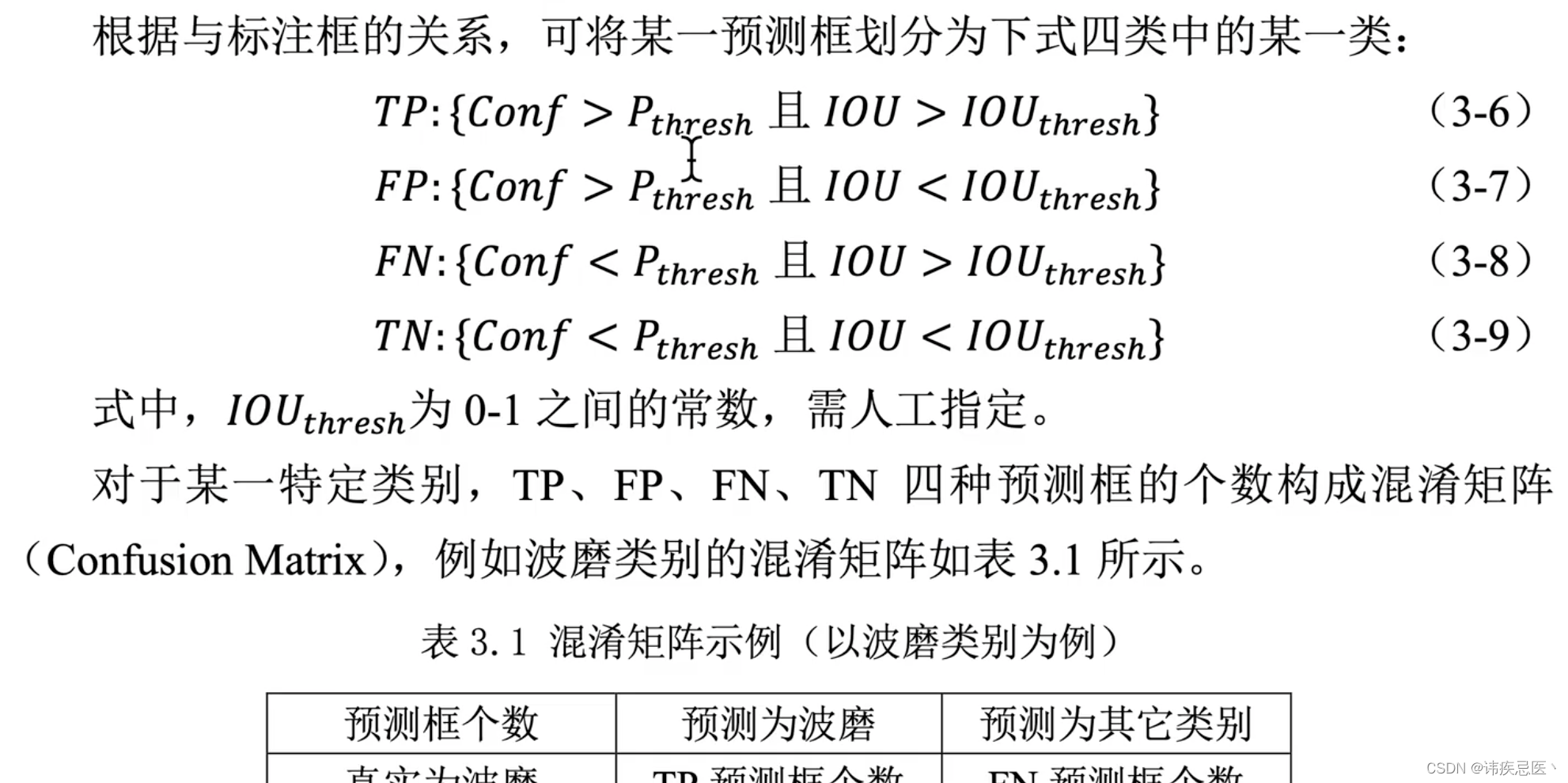
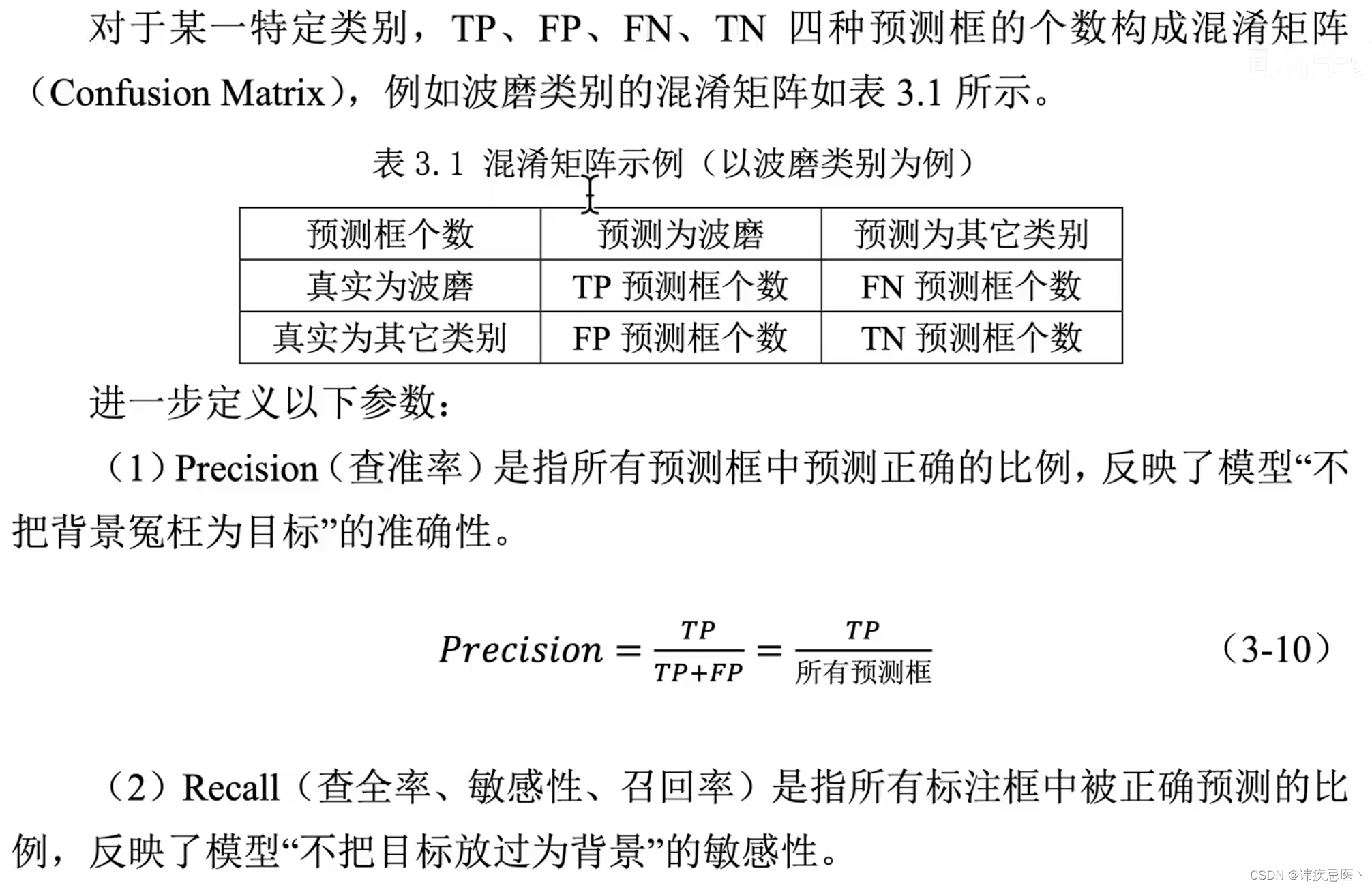
评估指标:yolov3精准定位较差,所以在map@0.5:0.95上较差
map@0.5:IOU阈值为0.5的时候,各个类别PR曲线面积的均值
置信度、IOU阈值
3、yolov3改进
多尺度目标检测:
输入任意尺度,输出3中尺度的feature map,yolov3通过多尺度融合,
改进了小物体和密集物体的检测问题:
1、增加了grid cell的个数
2、预先设置anchor
3、多尺度预测,及发挥了深层网络特化语义特征,又整合了浅层网络细腻度像素结构信息
4、损失函数惩罚小框项
5、网络结构(骨干网络、跨层连接)
4、使用opencv实现yolov3
import cv2
import numpy as np# 倒入python绘图函数
import matplotlib.pyplot as plt
# 使用ipython的魔术方法,将绘制出的图像直接嵌入在notebook单元格中
def look_img(img):# opencv读图片的是BGR、matplotlib是RGBimg_RGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)plt.imshow(img_RGB)plt.show()# 1、导入预训练YOLOv3模型
net = cv2.dnn.readNet('yolov3.weights','yolov3.cfg')# 2、导入coco数据集80个类别
with open('coco.names','r') as f:classes = f.read().splitlines()# 3、导入图像
img = cv2.imread('bus.jpg')
look_img(img)# 4、对图像预处理(将所有像素除以255,尺寸改成416,416,绿色通道和蓝色通道置换,不进行裁剪)
blob = cv2.dnn.blobFromImage(img,1/255,(416,416),(0,0,0),swapRB=True,crop=False)
blob.shape# 5、输入到网络
net.setInput(blob)# 获取网络所有层名字
net.getLayerNames()# 获取三个尺寸输出层的索引号
net.getUnconnectedOutLayers()#. 获取三个尺度输出层的名称
layerNames = net.getLayerNames()
output_layers_names = [layerNames[i - 1] for i in net.getUnconnectedOutLayers()]
output_layers_names# 6、输入yolov3神经网络,前向推断预测
prediction = net.forward(output_layers_names)# 7、获取yolov3三个尺度的输出结果
prediction[0].shape# 8、从三个尺度输出结果中解析所有预测框信息
# 存放预测框坐标
boxes = []# 存放置信度
objectness = []# 存放类别概率
class_probs = []# 存放预测框类别索引号
class_ids = []# 存放预测框类别名称
class_names = []for scale in prediction: # 遍历三种尺度for bbox in scale: # 遍历每个预测框obj = bbox[4] # 获取该预测框的confidence)(objectness)class_scores = bbox[5:] # 获取该预测框coco数据集80个类别的概率class_id = np.argmax(class_scores) # 获取概率最高类别的索引号class_name = classes[class_id] # 获取概率最高类别名称class_prob = class_scores[class_id] # 获取概率最高类别的概率# 获取预测框中心点坐标,预测框宽高if np.isnan(bbox[0]):bbox[0] = 0if np.isnan(bbox[1]):bbox[1] = 0if np.isnan(bbox[2]):bbox[2] = 0if np.isnan(bbox[3]):bbox[3] = 0center_x = int(bbox[0] * width)center_y = int(bbox[1] * height)w = int(bbox[2]*width)h = int(bbox[3]*height)# 计算预测框左上角坐标x = int(center_x - w/2)y = int(center_y - h/2)# 将每个预测框的结果存放至上面的列表中boxes.append([x,y,w,h])objectness.append(float(obj))class_ids.append(class_id)class_names.append(class_name)class_probs.append(class_prob)len(boxes)# 将预测框置信度objectness与各类别置信度class_pred相乘,获得最终该预测框的置信度confidence
confidences = np.array(class_probs) * np.array(objectness)
len(confidences)# objectness、class_pred、confidence三者的关系
plt.plot(objectness,label='objectness')
plt.plot(class_probs,label='class_probs')
plt.plot(confidences,label='confidences')
plt.legend()
plt.show()# 置信度过滤、非极大值抑制NMS
CONF_THRES = 0.1 # 制定置信度阈值、阈值越大、置信度过滤越强(小于这个阈值的所有框剔除掉)
NMS_THRES = 0.4 # 指定NMS阈值,阈值越小,NMS越强(IOU大于这个阈值的框,其中较小的剔除掉,减少重复预测)indexes = cv2.dnn.NMSBoxes(boxes,confidences,CONF_THRES,NMS_THRES)# 过滤完剩下的框
len(indexes.flatten())# 随机给每个预测框生成一种颜色
colors = [[255,0,255],[0,0,255],[0,255,0],[255,0,0]]# 遍历留下的每一个预测框,可视化
for i in indexes.flatten():# 获取坐标x,y,w,h = boxes[i]# 获取置信度confidence = str(round(confidence[i],2))# 获取颜色,画框color = colors[i%len(colors)]cv2.rectangle(img,(x,y),(x+w,y+h),color,8)# 写类别名称置信度# 图片、添加的文字、左上角坐标、字体、字体大小、颜色、字体粗细string = '{} {}'.format(class_names[i],confidence)cv2.putText(img,string,(x,y+20),cv2.FONT_HERSHEY_PLAIN,3,(255,255,255),5)
5、卷积神经网络工作原理
卷积核(是一种特征)对原图进行卷积,是把原图中包含这种特征提取出来
1、卷积计算(通过卷积核在图像上滑动计算,相乘、求和、取平均)结果等于1表示滤框中的值和卷积核的值完全一样
计算padding填充多少?
h2是卷积之后的高度,h1是原图像高度,f卷积核高度,p是填充多少,s是卷积核步长
h2 = (h1 - F + 2p)/s + 1
计算一下
// 在不进行填充的情况下,5*5的图像,在经过3*3卷积之后的结果就变成3*3了
(5-3+0)/1 + 1 = 3// 如果想保证原图像不变就需要进行padding操作
5 = (5-3+2p)/1 + 1
p = 1
// 所以需要在原图像周围补充一圈,具体补充什么值可以通过borderType进行设置
对原图整个做一遍扫描就得到这个图feature map
原图中包含卷积核的特征提取到这个feature map中来


池化
我们对原图提取出来的feature map进行池化(选取区域内最大值作为这个卷积核的值)

ReLUs将图中负数磨成0(激活函数)

经过卷积->磨0->池化之后就是这个样子了


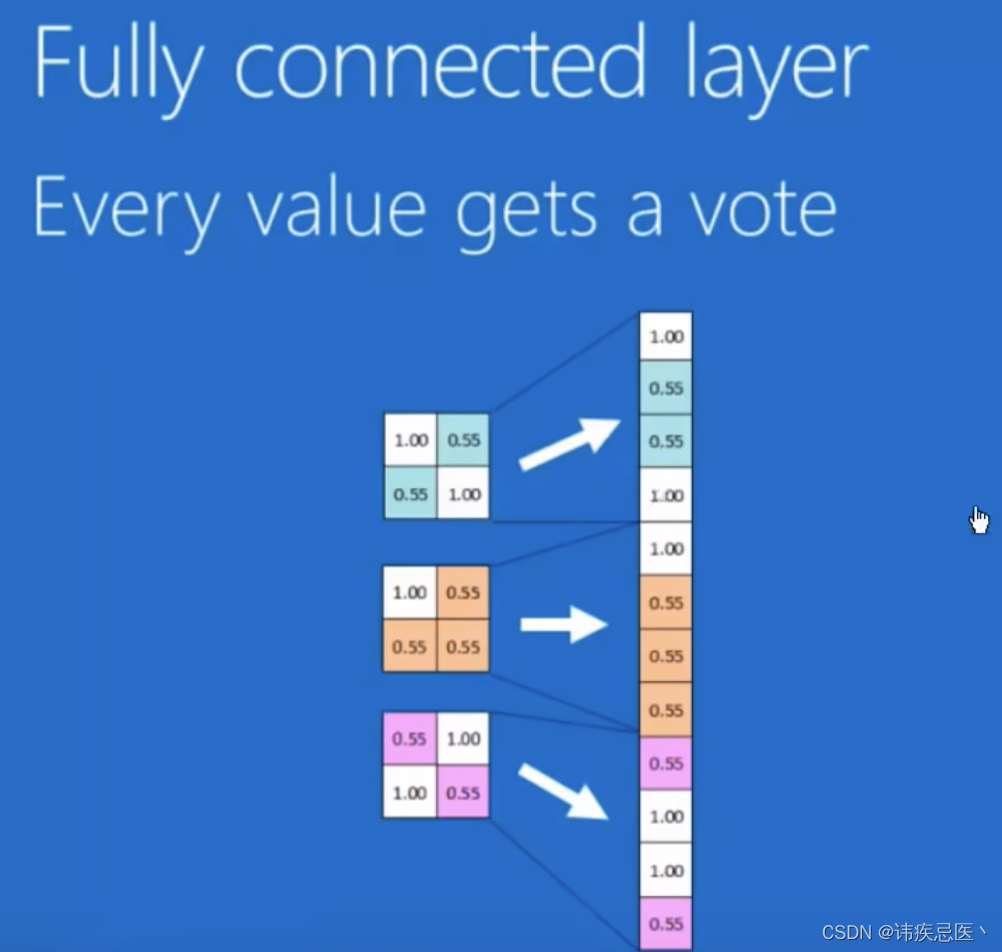
全连接层
将feature map进行排序,将每一个乘上不同权重最终得到结果
通过大量图片去训练这个模型,通过反向传播的方法,神经网络的到一个结果,将其和真实的结果进行比较误差计算(损失函数),我们的目标就是将损失函数降到最低,通过修改卷积核的参数和全连接每一层的权重来进行微调,使得损失函数最小。


这篇关于yolov3 详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



