本文主要是介绍目标检测算法YOLOv3简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLOv3由Joseph Redmon等人于2018年提出,论文名为:《YOLOv3: An Incremental Improvement》,论文见:https://arxiv.org/pdf/1804.02767.pdf ,项目网页:https://pjreddie.com/darknet/yolo/ 。YOLOv3是对YOLOv2的改进。
以下内容主要来自论文:
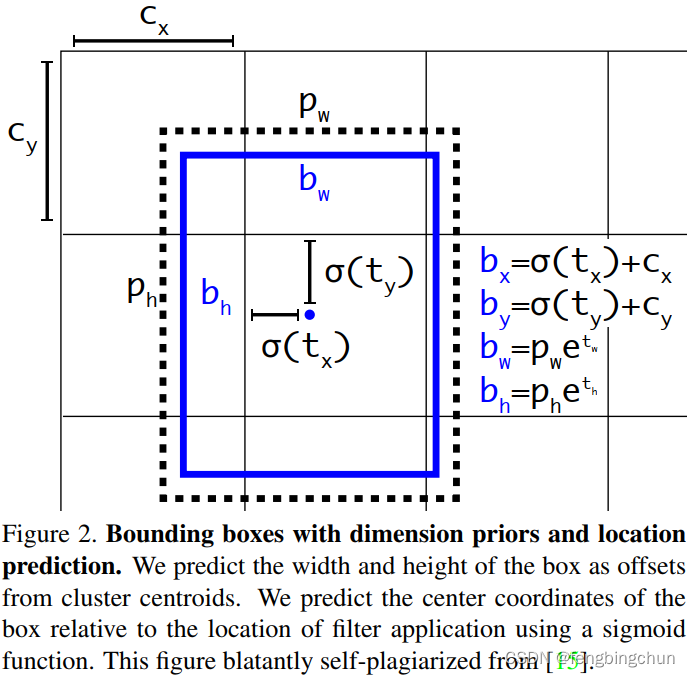
1.Bounding Box Prediction:遵循YOLO9000,我们的系统使用维度簇(dimension clusters)作为锚框来预测边界框。网络为每个边界框预测4个坐标:tx、ty、tw、th,如下图所示。在训练过程中,我们使用误差平方和损失(sum of squared error loss)。YOLOv3使用逻辑回归预测每个边界框的目标得分(objectness score)。如果先验边界框(bounding box prior)与真实目标(ground truth object)框的重叠程度超过任何其他先验边界框,则该值应该为1。如果先验边界框不是最好的,但确实与真实目标框重叠超过某个阈值,我们将忽略预测。我们使用0.5的阈值。我们的系统只为每个真实目标分配一个先验边界框。如果先验边界框未分配给真实目标,则不会导致坐标或类别预测损失,只会损失目标性(objectness,描述了某个图像区域是否可能包含一个目标的可能性)。
2.Class Prediction:每个框使用多标签分类(multilabel classification)来预测边界框可能包含的类别。我们不使用softmax,因为我们发现它对于良好的性能来说是不必要的,而是简单地使用独立的逻辑分类器(logistic classifiers)。在训练过程中,我们使用二元交叉熵损失(binary cross-entropy loss)进行类别预测。多标签方法可以更好地对数据进行建模。
3.Predictions Across Scales: YOLOv3预测3个不同尺度的框。我们的系统使用与特征金字塔网络(feature pyramid networks)类似的概念从这些尺度中提取特征。从我们的基本特征提取器中,我们添加了几个卷积层。最后一个预测3-d张量编码边界框、目标性和类别预测。在我们使用COCO的实验中,我们在每个尺度上预测 3个框,因此对于4个边界框偏移(bounding box offsets)、1个对象性预测和80个类别预测,张量为N*N*[3∗(4+1+80)]。接下来,我们从前2层获取特征图(feature map),并将其上采样2倍。我们还从网络的早期获取特征图,并使用串联(concatenation)将其与我们的上采样特征合并。这种方法使我们能够从上采样的特征中获得更有意义的语义信息(semantic information),并从早期的特征图中获得更细粒度(finer-grained)的信息。然后,我们添加更多的卷积层来处理这个组合特征图,并最终预测一个类似的张量(tensor),尽管现在大小是原来的两倍。我们再次执行相同的设计来预测最终尺度的框。因此,我们对第三个尺度的预测受益于所有先前的计算以及网络早期的细粒度特征(finegrained features)。我们仍然使用k均值聚类来确定边界框先验。我们只是任意选择9个簇(clusters)和3个尺度,然后在尺度上均匀地划分簇。在COCO数据集上,9个簇是:(10*13), (16*30), (33*23), (30*61), (62*45), (59*119), (116*90), (156*198), (373*326)。
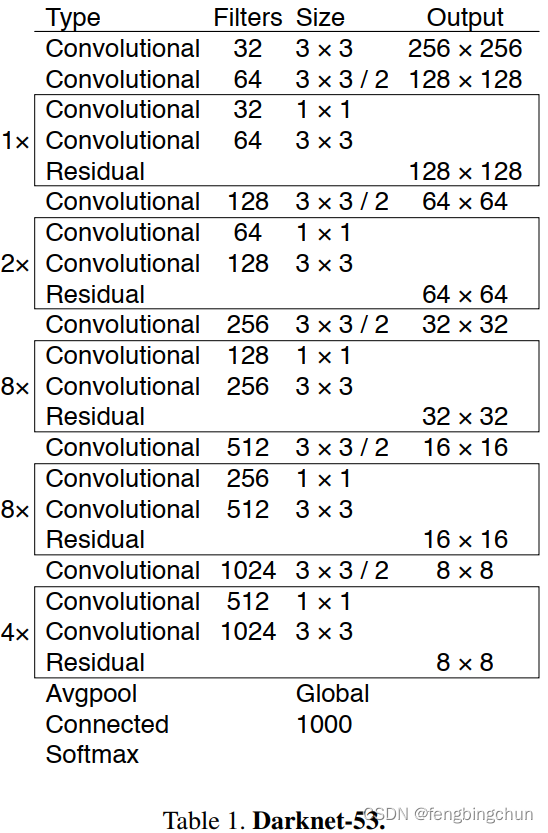
4.Feature Extractor:我们使用新的网络来执行特征提取。我们的新网络是YOLOv2、Darknet-19中使用的网络和新奇的残差网络(residual network)之间的混合方法。我们的网络使用连续的3*3和1*1卷积层,但现在也有一些快捷连接(shortcut connections),并且尺寸明显更大。它有53个卷积层,所以我们称之为Darknet-53,如下图所示:
过去,YOLO在处理小目标时遇到了困难。然而,现在我们看到这种趋势发生了逆转。通过新的多尺度预测,我们看到YOLOv3具有相对较高的AP性能。然而,它在中等和较大尺寸目标上的性能相对较差。
Things We Tried That Didn't Work:在开发YOLOv3时,我们尝试了很多东西。很多都没有效果。这是我们可以记住的东西。
1.锚框x,y偏移预测:我们尝试使用普通的锚框预测机制,你可以使用线性激活(linear activation)将x,y偏移量预测为框宽度或高度的倍数。我们发现这种公式降低了模型稳定性并且效果不佳。
2.线性x,y预测而不是逻辑预测:我们尝试使用线性激活来直接预测x,y偏移,而不是逻辑激活。这导致mAP下降了几个点。
3.焦点损失(focal loss):我们尝试使用焦点损失。它使我们的mAP下降了约2点。YOLOv3可能已经对焦点损失试图解决的问题具有鲁棒性(robust),因为它具有单独的对象性预测(objectness predictions)和条件类别预测。因此,对于大多数例子来说,类别预测没有损失?或者其他的东西?我们并不完全确定。
4.双IOU阈值和真值分配:Faster RCNN在训练期间使用两个IOU阈值。如果预测与真实情况重叠0.7,则为正例;如果预测与真实值重叠[.3−.7],则会被忽略;对于所有真实值目标,如果预测与真实值重叠小于0.3,则为负例。
我们非常喜欢我们当前的表述(formulation),它似乎至少处于局部最优。其中一些技术可能最终会产生良好的结果,也许它们只需要一些调整来稳定训练。
YOLOv3是一个很好的检测器。它很快,而且很准确。在0.5到0.95 IOU指标之间的COCO平均AP上,它并不那么好。但它在0.5 IOU的旧检测指标上非常好。
YOLOv3配置文件:https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
GitHub:https://github.com/fengbingchun/NN_Test
这篇关于目标检测算法YOLOv3简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








