本文主要是介绍YOLOv3+mAP实现金鱼检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLOv3+mAP实现金鱼检测
Git源码地址:传送门
准备数据集
- 按帧数读取视频保存图片 video2frame.py
- 使用labelimg标注工具对图片进行标注
- 统一图片大小为 416x416,并把标签等信息写成
.xml文件 conver_point.py - 读取缩放后的标签图片,转为左上角右下角坐标信息 voc2yolo_v3.py
自定义数据集
分析
- 准备数据集
- 使用标注工具(labelimg)给图片标注标签,转换为YOLO可用的格式
- 标签框信息:类别 + 中心点坐标 + 宽高
- cls, cx, cy, w, h
- 准备锚框
- 自定义锚框,3类检测目标各3种锚框,共9种锚框
- 获取锚框宽高 anchor_w, anchor_h,用于tw, th的制作
- 标签形状更换
- C H W --> H W C
- 如:使用13x13,四分类
- 13, 13, 27 --> (情况1) 13, 13, 3, 9 (情况2) 3, 13, 13, 9
- 填值(one-hot编码)
- tx, ty, tw, th, one-hot
- tx = 坐标x偏移量
- ty = 坐标y偏移量
- tw = torch.log(gt_w / anchor_w)
- th = torch.log(gt_h / anchor_h)
实现结构
- dataset.py
- init
- 读取特征文件,获得目标宽高所有信息
- 特征文件保存信息格式
- 文件名 类别 中心点坐标 宽高
- img_name, cls, cx, cy, gt_w, gt_h
- len
- 返回文件信息的长度
- gititem
- 根据索引读取指定行信息 img_name, cls, cx, cy, gt_w, gt_h
- 切割获得图片名字 img_name、标签框信息 cls, cx, cy, gt_w, gt_h
- 图片转为张量 img_name --> img_tensor
- 通道变换保存标签 H W 27 --> H W 3 9
- 标签框切割计算获取 cx, tx, cy, ty
- gt_w, gt_h和锚框宽高计算 tw th
- 类别cls和类别数创建one-hot编码
- 填值 label[cx, cy, feature_idx] = conf tx ty tw th one_hot
- init
完整代码
dataset.py
import math
import os.pathimport cv2
import numpy as np
import torch
from torch.utils.data import Dataset
from config import cfg
from util import util
import torch.nn.functional as Fclass ODDateset(Dataset):def __init__(self):super().__init__()with open(cfg.BASE_LABEL_PATH, 'r', encoding='utf-8') as f:self.lines = f.readlines()def __len__(self):return len(self.lines)def __getitem__(self, index):""":param index: 索引:return: 三种特征大小标签值、图片张量1. 根据索引读取指定行信息 img_name, cls, cx, cy, gt_w, gt_h2. 切割获得图片名字 img_name、标签框信息 cls, cx, cy, gt_w, gt_h3. 图片转为张量 img_name --> img_tensor4. 通道变换保存标签 H W 27 --> H W 3 95. 标签框切割计算获取 cx, tx, cy, ty6. gt_w, gt_h和锚框宽高计算 tw th7. 类别cls和类别数创建one-hot编码8. 填值 label[cx, cy, feature_idx] = conf tx ty tw th one_hot"""infos = self.lines[index].strip().split()img_name = infos[:1][0]# '1.jpg'img_path = os.path.join(cfg.BASE_IMG_PATH, img_name)img = cv2.imread(img_path)img_tensor = util.t(img)box_info = infos[1:]# ['2', '163', '218', '228', '246', '1', '288', '205', '159', '263']boxes = np.split(np.array(box_info, dtype=np.float_), len(box_info) // 5)# 0 = {ndarray: (5,)} [ 2. 163. 218. 228. 246.]# 1 = {ndarray: (5,)} [ 1. 288. 205. 159. 263.]label_dic = {}for feature, anchors in cfg.ANCHORS_GROUP.items():# H W 3 9label = torch.zeros((feature, feature, 3, 5 + cfg.CLASS_NUM))scale_factor = cfg.IMG_ORI_SIZE / feature# 416 / 13 = 32for box in boxes:cls, cx, cy, gt_w, gt_h = box# [ 2. 163. 218. 228. 246.]offset_x, cx_idx = math.modf(cx / scale_factor)# 0 = {float} 0.09375# 1 = {float} 5.0offset_y, cy_idx = math.modf(cy / scale_factor)for idx, anchor in enumerate(anchors):anchor_w, anchor_h = torch.tensor(anchor)# torch.log 加速收敛速度tw = torch.log(gt_w / anchor_w)th = torch.log(gt_h / anchor_h)one_hot = F.one_hot(torch.tensor(int(cls), dtype=torch.int64), num_classes=cfg.CLASS_NUM)# tensor([0, 0, 1, 0])conf = 1label[int(cy_idx), int(cx_idx), idx] = torch.tensor([conf, offset_x, offset_y, tw, th, *one_hot])# h w clabel_dic[feature] = labelf1, f2, f3 = cfg.ANCHORS_GROUP.keys()# 13 26 52return label_dic[f1], label_dic[f2], label_dic[f3], img_tensorif __name__ == '__main__':dataset = ODDateset()print(dataset[0])pass
构建网络模型
网络结构
- 主干网络 backbone
- 卷积层 CBL
- Conv
- BN
- LeakReLu
- 残差单元 ResUnit
- 下采样 DownSample
- 卷积层 CBL
- neck
- 卷积集合 ConvolutionSet
- 卷积层 CBL
- 上采样 UpSample
- 拼接操作 torch.cat
- head
- 卷积层 CBL
- 全卷积预测
- 类别 x 锚框
- ( 1 + 4 + 4 ) x 3

实现结构
- module.py
- 卷积层 CBL
- 残差单元 ResUnit
- 下采样 DownSample
- 上采样 UpSample
- 卷积集合 ConvolutionSet
- data.yaml
- 保存主干网络结构的参数:通道数、残差块数量
- darknet53.py
- 实现主干网络结构,输出out_13x13, out_26x26, out_52x52
- yolov3.py
- 初始化主干网络,实现neck、head网络结构,输出detect_13_out, detect_26_out, detect_52_out
完整代码
module.py
"""
网络结构
- backbone- 卷积层 CBL- Conv- BN- LeakReLu- 残差单元 ResUnit- 下采样 DownSample
- neck- 卷积集合 ConvolutionSet- 上采样 UpSample- 拼接操作 torch.cat"""
import torch
from torch import nnclass CBL(nn.Module):# Conv+BN+LeakReLudef __init__(self, c_in, c_out, k, s):super().__init__()self.cnn_layer = nn.Sequential(nn.Conv2d(c_in, c_out, kernel_size=k, stride=s, padding=k // 2, bias=False),nn.BatchNorm2d(c_out),nn.LeakyReLU())def forward(self, x):return self.cnn_layer(x)class ResUnit(nn.Module):# 残差单元def __init__(self, c_num):super().__init__()self.block = nn.Sequential(CBL(c_num, c_num // 2, 1, 1),CBL(c_num // 2, c_num, 3, 1))def forward(self, x):return self.block(x) + xclass DownSample(nn.Module):# 下采样def __init__(self, c_in, c_out):super().__init__()self.down_sample = nn.Sequential(CBL(c_in, c_out, 3, 2))def forward(self, x):return self.down_sample(x)class ConvolutionSet(nn.Module):# 卷积集合def __init__(self, c_in, c_out):super().__init__()self.cnn_set = nn.Sequential(CBL(c_in, c_out, 1, 1),CBL(c_out, c_in, 3, 1),CBL(c_in, c_out, 1, 1),CBL(c_out, c_in, 3, 1),CBL(c_in, c_out, 1, 1))def forward(self, x):return self.cnn_set(x)class UpSample(nn.Module):# 上采样def __init__(self):super().__init__()self.up_sample = nn.Upsample(scale_factor=2, mode='nearest')def forward(self, x):return self.up_sample(x)if __name__ == '__main__':# data = torch.randn(1, 3, 416, 416)# cnn = nn.Sequential(# CBL(3, 32, 3, 1),# DownSample(32, 64)# )# res = ResUnit(64)## cnn_out = cnn(data)# res_out = res(cnn_out)# print(cnn_out.shape)# # torch.Size([1, 64, 208, 208])# print(res_out.shape)# # torch.Size([1, 64, 208, 208])data = torch.randn(1, 1024, 13, 13)con_set = ConvolutionSet(1024, 512)cnn = CBL(512, 256, 1, 1)up_sample = UpSample()P0_out = up_sample(cnn(con_set(data)))print(P0_out.shape)# torch.Size([1, 256, 26, 26])pass
data.yaml
block_nums:
- 1
- 2
- 8
- 8
- 4
channels:
- 32
- 64
- 128
- 256
- 512
- 1024
darknet53.py
import torch
import yaml
from torch import nn
from module import CBL, ResUnit, DownSampleclass DarkNet53(nn.Module):def __init__(self):super().__init__()self.input_layer = nn.Sequential(CBL(3, 32, 3, 1))# # 方式1# self.hidden_layer = nn.Sequential(# DownSample(32, 64),# ResUnit(64),## DownSample(64, 128),# ResUnit(128),# ResUnit(128),## DownSample(128, 256),# ResUnit(256),# ResUnit(256),# ResUnit(256),# ResUnit(256),# ResUnit(256),# ResUnit(256),# ResUnit(256),# ResUnit(256),## DownSample(256, 512),# ResUnit(512),# ResUnit(512),# ResUnit(512),# ResUnit(512),# ResUnit(512),# ResUnit(512),# ResUnit(512),# ResUnit(512),## DownSample(512, 1024),# ResUnit(1024),# ResUnit(1024),# ResUnit(1024),# ResUnit(1024)# )# 方式2layers = []with open('data.yaml', 'r', encoding='utf-8') as file:dic = yaml.safe_load(file)channels = dic['channels']block_nums = dic['block_nums']for idx, block_num in enumerate(block_nums):layers.append(self.make_layer(channels[idx], channels[idx + 1], block_num))self.hidden_layer = nn.Sequential(*layers)def make_layer(self, c_in, c_out, block_num):units = [DownSample(c_in, c_out)]for _ in range(block_num):units.append(ResUnit(c_out))return nn.Sequential(*units)def forward(self, x):x = self.input_layer(x)unit52_out = self.hidden_layer[:3](x)unit26_out = self.hidden_layer[3](unit52_out)unit13_out = self.hidden_layer[4](unit26_out)return unit52_out, unit26_out, unit13_outif __name__ == '__main__':data = torch.randn(1, 3, 416, 416)net = DarkNet53()# out = net(data)# print(out.shape)# # torch.Size([1, 1024, 13, 13])outs = net(data)for out in outs:print(out.shape)# torch.Size([1, 256, 52, 52])# torch.Size([1, 512, 26, 26])# torch.Size([1, 1024, 13, 13])# darknet_hidden_param = {# 'channels': [32, 64, 128, 256, 512, 1024],# 'block_nums': [1, 2, 8, 8, 4]# }# with open('data.yaml', 'r', encoding='utf-8') as file:# # yaml.safe_dump(darknet_hidden_param, file)# dic = yaml.safe_load(file)# channels = dic['channels']# block_nums = dic['block_nums']# print(dic)# # {'block_nums': [1, 2, 8, 8, 4], 'channels': [32, 64, 128, 256, 512, 1024]}# print(channels)# # [32, 64, 128, 256, 512, 1024]# print(block_nums)# # [1, 2, 8, 8, 4]pass
yolov3.py
import torch
from torch import nn
from darknet53 import DarkNet53
from module import ConvolutionSet, CBL, UpSampleclass YoLov3(nn.Module):def __init__(self):super().__init__()self.backbone = DarkNet53()self.conv1 = nn.Sequential(ConvolutionSet(1024, 512))self.detect_13 = nn.Sequential(CBL(512, 256, 3, 1),# 4分类 * 锚框: (1 + 4 + 4) * 3CBL(256, 27, 1, 1))self.neck_hidden1 = nn.Sequential(CBL(512, 256, 1, 1),UpSample())self.conv2 = nn.Sequential(ConvolutionSet(256 + 512, 256))self.detect_26 = nn.Sequential(CBL(256, 128, 3, 1),CBL(128, 27, 1, 1))self.neck_hidden2 = nn.Sequential(CBL(256, 128, 1, 1),UpSample())self.conv3 = nn.Sequential(ConvolutionSet(128 + 256, 128))self.detect_52 = nn.Sequential(CBL(128, 64, 3, 1),CBL(64, 27, 1, 1))def forward(self, x):backbone_unit52_out, backbone_unit26_out, backbone_unit13_out = self.backbone(x)conv1_out = self.conv1(backbone_unit13_out)detect_13_out = self.detect_13(conv1_out)neck_hidden1_out = self.neck_hidden1(conv1_out)route26_out = torch.cat((neck_hidden1_out, backbone_unit26_out), dim=1)conv2_out = self.conv2(route26_out)detect_26_out = self.detect_26(conv2_out)neck_hidden2_out = self.neck_hidden2(conv2_out)route52_out = torch.cat((neck_hidden2_out, backbone_unit52_out), dim=1)conv3_out = self.conv3(route52_out)detect_52_out = self.detect_52(conv3_out)return detect_13_out, detect_26_out, detect_52_outif __name__ == '__main__':data = torch.randn(1, 3, 416, 416)yolov3 = YoLov3()outs = yolov3(data)for out in outs:print(out.shape)# torch.Size([1, 512, 13, 13])# torch.Size([1, 256, 26, 26])# torch.Size([1, 128, 52, 52])# P0 P1 P2: N 27 H W# 27: 类别(1 + 4 + 4) * 锚框3# torch.Size([1, 27, 13, 13])# torch.Size([1, 27, 26, 26])# torch.Size([1, 27, 52, 52])pass
训练模型
分析
- 准备数据dataset
- 初始化网络模型
- 损失函数
- 目标检测
- 正样本
- 置信度:二分类交叉熵
- 坐标:均方差损失
- 类别:交叉熵损失
- 负样本
- 置信度:二分类交叉熵
- 正样本
- 目标检测
- 优化器
实现结构
- train.py
- init
- 准备数据 dataset
- 初始化自定义数据集
- 数据加载器:批次、打乱次序
- 初始化网络模型 yolov3
- 切换设备
- 损失函数
- 置信度:二分类交叉熵BCEWithLogitsLoss
- 坐标:均方差损失MSELoss
- 类别:交叉熵损失CrossEntropyLoss
- 优化器 Adam
- 准备数据 dataset
- train
- 网络模型开启训练
- 遍历数据加载器获得三种特征大小标签值、图片张量,并切换设备
- 图片张量传入网络获得三种预期输出
- 三种标签值、对应预期输出值和正负样本因子传入loss_fn,计算获得对应损失,并求和获得模型损失
- 优化器进行梯度清零
- 模型损失反向传播
- 优化器进行梯度更新
- 累加模型损失计算平均损失
- 保存模型权重
- loss_fn
- 预期输出值更换通道 N 27 H W --> N H W 27 --> N H W 3 9
- 获取位置索引值
- 正样本数据位置 target[…, 0] > 0
- 负样本数据位置 target[…, 0] == 0
- 计算损失
- 正样本:置信度 坐标 类别
- 负样本:置信度
- 索引获取
- 0 置信度
- 1:5 坐标
- 5: 类别
- 正负样本乘上对应规模因子的累加和
- run
- 设定迭代次数,循环调用train训练模型
- init
完整代码
train.py
"""
分析1. 准备数据dataset
2. 初始化网络模型
3. 损失函数- 目标检测- 正样本- 置信度:二分类交叉熵- 坐标:均方差损失- 类别:交叉熵损失- 负样本- 置信度:二分类交叉熵4. 优化器
"""
import osimport torch.optim
from torch import nn
from torch.utils.data import DataLoader
from yolov3 import YoLov3
from dataset import ODDateset
from config import cfgdevice = cfg.deviceclass Train:def __init__(self):# 1. 准备数据datasetod_dataset = ODDateset()self.dataloader = DataLoader(od_dataset, batch_size=6, shuffle=True)# 2. 初始化网络模型self.net = YoLov3().to(device)# 加载参数# if os.path.exists(cfg.WEIGHT_PATH):# self.net.load_state_dict(torch.load(cfg.WEIGHT_PATH))# print('loading weights successfully')# 3. 损失函数# - 置信度:二分类交叉熵BCEWithLogitsLossself.conf_loss_fn = nn.BCEWithLogitsLoss()# - 坐标:均方差损失MSELossself.loc_loss_fn = nn.MSELoss()# - 类别:交叉熵损失CrossEntropyLossself.cls_loss_fn = nn.CrossEntropyLoss()# 4. 优化器self.opt = torch.optim.Adam(self.net.parameters())def train(self, epoch):""":param epoch: 迭代训练的次数:return: None1. 开启训练2. 遍历数据加载器获取三种特征大小标签值、图片张量,并切换设备3. 图片张量传入网络获得三种预期输出4. 三种标签值、对应预期输出值和正负样本因子传入loss_fn,计算获得对应损失,并求和获得模型损失5. 优化器进行梯度清零6. 模型损失反向传播7. 优化器进行梯度更新8. 累加模型损失计算平均损失9. 保存模型权重"""# 1. 开启训练self.net.train()# 累加损失sum_loss = 0for target_13, target_26, target_52, img in self.dataloader:# 2. 获取三种特征大小标签值、图片张量,并切换设备target_13, target_26, target_52 = target_13.to(device), target_26.to(device), target_52.to(device)img = img.to(device)# 3. 图片张量传入网络获得三种预期输出pred_out_13, pred_out_26, pred_out_52 = self.net(img)# 4.loss_13 = self.loss_fn(target_13, pred_out_13, scale_factor=cfg.SCALE_FACTOR_BIG)loss_26 = self.loss_fn(target_26, pred_out_26, scale_factor=cfg.SCALE_FACTOR_MID)loss_52 = self.loss_fn(target_52, pred_out_52, scale_factor=cfg.SCALE_FACTOR_SML)loss = loss_13 + loss_26 + loss_52# 5. 梯度清零self.opt.zero_grad()# 6. 反向传播loss.backward()# 7. 梯度更新self.opt.step()sum_loss += loss.item()avg_loss = sum_loss / len(self.dataloader)print(f'{epoch}\t{avg_loss}')if epoch % 10 == 0:print('save weight')torch.save(self.net.state_dict(), cfg.WEIGHT_PATH)def loss_fn(self, target, pre_out, scale_factor):""":param target: 标签:param pre_out: 预期输出:param scale_factor: 正负样本因子:return: 正负样本乘上对应规模因子的累加和1. 预期输出值更换通道 N 27 H W --> N H W 27 --> N H W 3 92. 获取位置索引值- 正样本数据位置 target[..., 0] > 0- 负样本数据位置 target[..., 0] == 03. 计算损失- 正样本:置信度 坐标 类别- 负样本:置信度- 索引获取- 0 置信度- 1:5 坐标- 5: 类别4. 正负样本乘上对应规模因子的累加和"""# 1. 预期输出值更换通道 N 27 H W --> N H W 27 --> N H W 3 9pre_out = pre_out.permute((0, 2, 3, 1))n, h, w, _ = pre_out.shapepre_out = torch.reshape(pre_out, (n, h, w, 3, -1))# 2. 获取位置索引值 正样本数据位置 target[..., 0] > 0 负样本数据位置 target[..., 0] == 0mask_obj = target[..., 0] > 0mask_noobj = target[..., 0] == 0# 3. 计算损失# 正样本:置信度 坐标 类别target_obj = target[mask_obj]output_obj = pre_out[mask_obj]conf_loss = self.conf_loss_fn(output_obj[:, 0], target_obj[:, 0])loc_loss = self.loc_loss_fn(output_obj[:, 1:5], target_obj[:, 1:5])cls_loss = self.cls_loss_fn(output_obj[:, 5:], torch.argmax(target_obj[:, 5:], dim=1))loss_obj = conf_loss + loc_loss + cls_loss# 负样本:置信度target_noobj = target[mask_noobj]output_noobj = pre_out[mask_noobj]loss_noobj = self.conf_loss_fn(output_noobj[:, 0], target_noobj[:, 0])# 4. 正负样本乘上对应规模因子的累加和return loss_obj * scale_factor + loss_noobj * (1 - scale_factor)def run(self):for epoch in range(500):self.train(epoch)passif __name__ == '__main__':train = Train()train.run()pass
推理预测
分析
- 网络初始化,加载权重参数 net
- 输入数据预处理(归一化) img_norm
- 前向传播获得输出,输出数据形状是 N C H W --> N 3(锚框数量 anchor_num) 9 H W
- 根据给定的阈值 thresh 获取符合阈值要求目标的索引
- idx = torch.where([:, :, 0, :, :] > thresh
- N: idx[0]
- anchor_num = idx[1]
- H(rows): idx[2]
- W(cols): idx[3]
- 解码中心点坐标 cx cy
- cx_idx = 2
- cy_idx = 1
- tx = [:, :, 1, :, :]
- ty = [:, :, 2, :, :]
- tw = [:, :, 3, :, :]
- th = [:, :, 4, :, :]
- cx = (cx_idx + tx) * 32
- cy = (cy_idx + ty) * 32
- pred_w = exp(tw) * anchor_w
- pred_h = exp(th) * anchor_h
实现结构
- detect.py
- init
- 初始化网络
- 网络开启验证
- 网络加载参数
- forward
- 图像预处理
- 图片转为张量
- 扩张维度,表示批次
- 图片张量传给网络获得检测输出
- 对检测输出进行解码 decode,获得检测框信息
- 拼接大中小目标框信息并返回
- 图像预处理
- decode
- 预期输出值更换通道 N 27 H W --> N H W 27 --> N H W 3 9
- 获取检测框的坐标索引 锚框数量
- 获取检测框的标签信息 [[conf, tx, ty, tw, th, cls], …]
- 方式1:label = pred_out[idx[0], idx[1], idx[2], idx[3], :]
- 方式2:label = pred_out[idx]
- 计算检测框的中心坐标 宽高
- 规模因子 = 原图大小 / 特征大小
- 获取当前特征对应的三种锚框
- 获取索引对应的锚框的宽高
- 坐标转换:中心点坐标+宽高 --> 左上角坐标+右下角坐标
- torch.stack 整合坐标 [conf, x_min, y_min, x_max, y_max, cls]
- run
- 传入图片进行前向传播,获得预测框信息
- 根据不同类别,遍历框信息,进行NMS,获得各类别最优框
- 不同类别绘制不同颜色的检测框,并标注类别名
- 保存框的置信度和坐标信息,以便计算mAP
- init
- util.py
- bbox_iou
- 计算标签框和输出框的交并比
- nms
- 模型输出的框,按置信度排序
- 置信度最高的,作为当前类别最优的框 max_conf_box = detect_boxes[0]
- 剩余的框 detect_boxes[1:] 和当前最优框 max_conf_box 计算IOU 获取 iou_val
- 和给定阈值(超参数)作比较 iou_idx = iou_val < thresh
- detect_boxes[1:][iou_idx] 则为保留的框
完整代码
detect.py
"""
分析1. 网络初始化,加载权重参数 net
2. 输入数据预处理(归一化) img_norm
3. 前向传播获取预期输出,计算获取 cx cy pred_w pred_h- 切片获取数据 cls, tx, ty, tw, th, one_hot- cx = (索引 + tx) * 特征规模大小- cy = (索引 + ty) * 特征规模大小- pred_w = exp(tw) * anchor_w- pred_h = exp(th) * anchor_h
4. 绘制检测框"""
import osimport cv2
import torch
from torch import nnfrom yolov3 import YoLov3
from config import cfg
from util import utilclass Detector(nn.Module):def __init__(self):super().__init__()# 1. 网络初始化net = YoLov3()# 开启验证net.eval()# 加载权重参数 netnet.load_state_dict(torch.load(cfg.WEIGHT_PATH))print('loading weights successfully')self.net = netdef normalize(self, frame):frame_tensor = util.t(frame)frame_tensor = torch.unsqueeze(frame_tensor, dim=0)return frame_tensordef decode(self, pred_out, feature, threshold):# 1. 预期输出值更换通道 N 27 H W --> N H W 27 --> N H W 3 9pred_out = pred_out.permute((0, 2, 3, 1))n, h, w, _ = pred_out.shapepred_out = torch.reshape(pred_out, (n, h, w, 3, -1))# 2. 获取检测框的坐标索引 锚框数量idx = torch.where(pred_out[:, :, :, :, 0] > threshold)# N H W 3(锚框数量)# - N: idx[0]# - H(rows): idx[1]# - W(cols): idx[2]# - anchor_num = idx[3]h_idx = idx[1]w_idx = idx[2]anchor_num = idx[3]# 3. 获取检测框的标签信息 [[conf, tx, ty, tw, th, cls], ...]# 方式1# label = pred_out[idx[0], idx[1], idx[2], idx[3], :]# 方式2label = pred_out[idx]# N V# [[conf, tx, ty, tw, th, cls], ...]conf = label[:, 0]tx = label[:, 1]ty = label[:, 2]tw = label[:, 3]th = label[:, 4]cls = torch.argmax(label[:, 5:], dim=1)# 4. 计算检测框的中心坐标 宽高# 规模因子 = 原图大小 / 特征大小scale_factor = cfg.IMG_ORI_SIZE / featurecx = (tx + w_idx) * scale_factorcy = (ty + h_idx) * scale_factor# 当前特征对应的三种锚框anchors = cfg.ANCHORS_GROUP[feature]# anchors 类型是list 转为张量便于高级索引anchors = torch.tensor(anchors)# 获取索引对应的锚框的宽高anchor_w = anchors[anchor_num][:, 0]anchor_h = anchors[anchor_num][:, 1]pred_w = torch.exp(tw) * anchor_wpred_h = torch.exp(th) * anchor_h# 5. 坐标转换:中心点坐标+宽高 --> 左上角坐标+右下角坐标x_min = cx - pred_w / 2y_min = cy - pred_h / 2x_max = cx + pred_w / 2y_max = cy + pred_h / 2# torch.stack 整合坐标 [conf, x_min, y_min, x_max, y_max, cls]out = torch.stack((conf, x_min, y_min, x_max, y_max, cls), dim=1)return outdef show_image(self, img, x1, y1, x2, y2, cls):cv2.rectangle(img,(int(x1), int(y1)),(int(x2), int(y2)),color=cfg.COLOR_DIC[int(cls)],thickness=2)cv2.putText(img,text=cfg.CLS_DIC[int(cls)],org=(int(x1) + 5, int(y1) + 10),color=cfg.COLOR_DIC[int(cls)],fontScale=0.5,fontFace=cv2.FONT_ITALIC)cv2.imshow('img', img)cv2.waitKey(25)def forward(self, img, threshold):img_norm = self.normalize(img)pred_out_13, pred_out_26, pred_out_52 = self.net(img_norm)f_big, f_mid, f_sml = cfg.ANCHORS_GROUP.keys()box_13 = self.decode(pred_out_13, f_big, threshold)box_26 = self.decode(pred_out_26, f_mid, threshold)box_52 = self.decode(pred_out_52, f_sml, threshold)boxes = torch.cat((box_13, box_26, box_52), dim=0)return box_52def run(self, img_names):for img_name in img_names:img_path = os.path.join(cfg.BASE_IMG_PATH, img_name)img = cv2.imread(img_path)detect_out = detect(img, cfg.THRESHOLD_BOX)if len(detect_out) == 0:continuefilter_boxes = []for cls in range(4):mask_cls = detect_out[..., -1] == cls_boxes = detect_out[mask_cls]boxes = util.nms(_boxes, cfg.THRESHOLD_NMS)if len(boxes) == 0:continuefilter_boxes.append(boxes)for boxes in filter_boxes:for box in boxes:conf, x1, y1, x2, y2, cls = boxself.show_image(img, x1, y1, x2, y2, cls)# cv2.imwrite(os.path.join(f"./run/imgs/{img_name}"), img)# 保存box信息# file_name = img_name.split('.')[0] + '.txt'# file_path = os.path.join('../data/cal_map/input/detection-results', file_name)# with open(file_path, 'a', encoding='utf-8') as file:# conf_norm = nn.Sigmoid()(conf)# file.write(f"{cfg.CLS_DIC[int(cls)]} {conf_norm} {int(x1)} {int(y1)} {int(x2)} {int(y2)}\n")if __name__ == '__main__':detect = Detector()# frame = cv2.imread('../data/VOC2007/YOLOv3_JPEGImages/2.jpg')# boxes = detect(frame, 1)# # 获取同种类的框,进行NMS# boxes = util.nms(boxes, 0.1)# for box in boxes:# conf, x1, y1, x2, y2, cls = box.detach().cpu().numpy()# detect.show_image(frame, x1, y1, x2, y2, cls)# # cv2.imshow('frame', frame)# cv2.waitKey(0)# cv2.destroyAllWindows()# 多张图片img_names = os.listdir(cfg.BASE_IMG_PATH)detect.run(img_names)pass
util.py
import torch
from torchvision import transforms
from config import cfgt = transforms.Compose([# H W C --> C H W 且把值归一化为 0-1transforms.ToTensor()
])def bbox_iou(box, boxes):box_area = (box[2] - box[0]) * (box[3] - box[1])boxes_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])l_x = torch.maximum(box[0], boxes[:, 0])l_y = torch.maximum(box[1], boxes[:, 1])r_x = torch.minimum(box[2], boxes[:, 2])r_y = torch.minimum(box[3], boxes[:, 3])w = torch.maximum(r_x - l_x, torch.tensor(0))h = torch.maximum(r_y - l_y, torch.tensor(0))inter_area = w * hiou_val = inter_area / (box_area + boxes_area - inter_area)return iou_valdef nms(detect_boxes, threshold=0.5):""":param detect_boxes: 侦测输出的框的信息 [[conf, tx, ty, tw, th, cls], ...]:param threshold: 阈值:return: 筛选后的侦测框流程分析1. 模型输出的框,按置信度排序2. 置信度最高的,作为当前类别最优的框 max_conf_box = detect_boxes[0]3. 剩余的框 detect_boxes[1:] 和当前最优框 max_conf_box 计算IOU 获取 iou_val4. 和给定阈值(超参数)作比较 iou_idx = iou_val < thresh5. detect_boxes[1:][iou_idx] 则为保留的框"""# 保留最优框信息best_boxes = []# 1. 模型输出的框,按置信度排序idx = torch.argsort(detect_boxes[:, 0], descending=True)detect_boxes = detect_boxes[idx]while detect_boxes.size(0) > 0:# 2. 置信度最高的,作为当前类别最优的框max_conf_box = detect_boxes[0]best_boxes.append(max_conf_box)# 3. 剩余的框 detect_boxes[1:] 和当前最优框 max_conf_box 计算IOUdetect_boxes = detect_boxes[1:]iou_val = bbox_iou(max_conf_box[1:5], detect_boxes[:, 1:5])# 4. 和给定阈值(超参数)作比较保留小于阈值的对应框detect_boxes = detect_boxes[iou_val < threshold]return best_boxes参数配置文件
cfg.py
import torch'自定义锚框'
ANCHORS_GROUP = {13: [[360, 360], [360, 180], [180, 360]],26: [[180, 180], [180, 90], [90, 180]],52: [[90, 90], [90, 45], [45, 90]]
}'yolo5 coco数据集锚框'
ANCHORS_DIC = {13: [[116, 90], [156, 198], [373, 326]],26: [[30, 61], [62, 45], [59, 119]],52: [[10, 13], [16, 30], [33, 23]]
}device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
CLASS_NUM = 4
IMG_ORI_SIZE = 416
BASE_IMG_PATH = r'E:\pythonProject\yolo3\data\VOC2007\YOLOv3_JPEGImages'
BASE_LABEL_PATH = r'E:\pythonProject\yolo3\data\VOC2007\yolo_annotation.txt'
WEIGHT_PATH = r'E:\pythonProject\yolo3\net\weights\best.pt'SCALE_FACTOR_BIG = 0.9
SCALE_FACTOR_MID = 0.9
SCALE_FACTOR_SML = 0.9
'阈值'
THRESHOLD_BOX = 0.9
THRESHOLD_NMS = 0.1'视频路径'
VIDEO_PATH = r'E:\pythonProject\yolo3\data\video\fish_video.mp4'
VIDEO2FRAME_PATH = r'E:\pythonProject\yolo3\data\VOC2007\JPEGImages'
'网络参数'
DARKNET35_PARAM_PATH = r'E:\pythonProject\yolo3\config\data.yaml'
'检测类别'
CLS_DIC = {0: 'big_fish',1: 'small_fish'
}
COLOR_DIC = {0: (0, 0, 255), 1: (100, 200, 255), 2: (255, 0, 0), 3: (0, 255, 0)}
计算评价指标
- Github上下载一个mAP源码(如:
https://github.com/Cartucho/mAP.git) - 手动创建计算mAP的输入数据文件夹
- input
- detection-results:模型输出数据集
- ground-truth:标签数据集
- images-optional:原图缩放后的数据集
- input
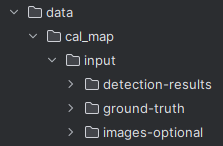
- data/VOC2007/YOLOv3_JPEGImages数据拷贝到images-optional
- data/VOC2007/Annotations数据拷贝到ground-truth
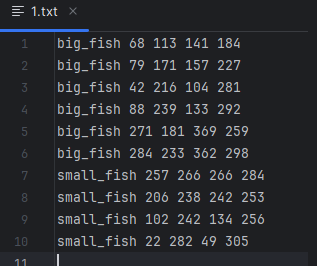
- 运行convert_gt_xml.py,把
.xml文件转为.txt文件- 其中
.txt文件保存的是图片标签框的类别名+坐标信息cls_name xmin ymin xmax ymax
- 其中
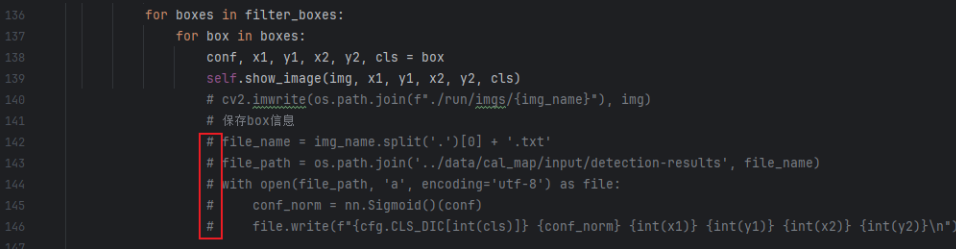
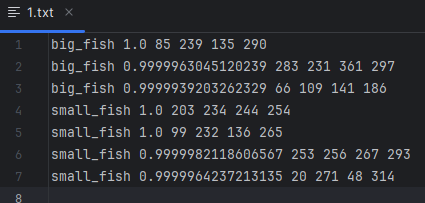
- detector.py取消142-146行代码的注释,运行代码后,detection-results文件夹会保存模型输出框的
.txt文件- 其中
.txt文件保存的是图片标签框的类别名+置信度+坐标信息cls_name conf xmin ymin xmax ymax
- 其中
- 运行map.py会自动生成output文件,弹出mAP图

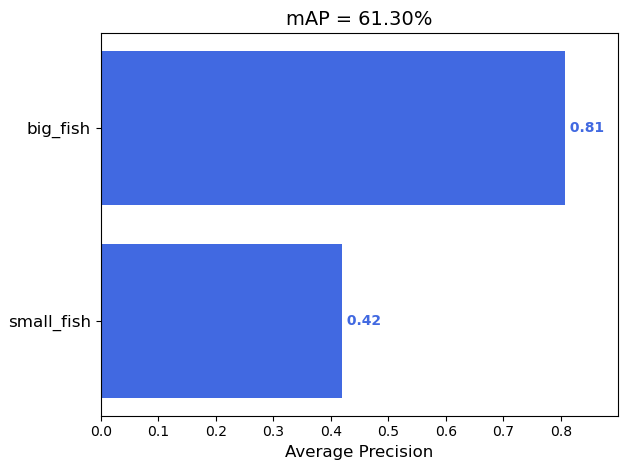
完整代码
convert_gt_xml.py
import sys
import os
import glob
import xml.etree.ElementTree as ET# make sure that the cwd() in the beginning is the location of the python script (so that every path makes sense)
os.chdir(os.path.dirname(os.path.abspath(__file__)))# change directory to the one with the files to be changed
parent_path = os.path.abspath(os.path.join(os.getcwd(), os.pardir))
parent_path = os.path.abspath(os.path.join(parent_path, os.pardir))
# GT_PATH = os.path.join(parent_path, 'input','ground-truth')
yolo3_path = os.getcwd().rsplit('\\', 1)[:1][0]
# 'E:\\pythonProject\\yolo3'
GT_PATH = os.path.join(yolo3_path, 'data', 'cal_map', 'input', 'ground-truth')
#print(GT_PATH)
os.chdir(GT_PATH)# old files (xml format) will be moved to a "backup" folder
## create the backup dir if it doesn't exist already
if not os.path.exists("backup"):os.makedirs("backup")# create VOC format files
xml_list = glob.glob('*.xml')
if len(xml_list) == 0:print("Error: no .xml files found in ground-truth")sys.exit()
for tmp_file in xml_list:#print(tmp_file)# 1. create new file (VOC format)with open(tmp_file.replace(".xml", ".txt"), "a") as new_f:root = ET.parse(tmp_file).getroot()for obj in root.findall('object'):obj_name = obj.find('name').textbndbox = obj.find('bndbox')left = bndbox.find('xmin').texttop = bndbox.find('ymin').textright = bndbox.find('xmax').textbottom = bndbox.find('ymax').textnew_f.write("%s %s %s %s %s\n" % (obj_name, left, top, right, bottom))# 2. move old file (xml format) to backupos.rename(tmp_file, os.path.join("backup", tmp_file))
print("Conversion completed!")
voc2yolo_v3.py
import glob
import xml.etree.ElementTree as ET
import osdef xml_to_yolo(xml_path, img_path, save_dir):img_name = os.path.basename(img_path)xml_name_pre = os.path.basename(xml_path).split(".")[0]img_name_pre = os.path.basename(img_path).split(".")[0]if xml_name_pre != img_name_pre:print("xml_name is not equal to img_name")returntree = ET.parse(xml_path)root = tree.getroot()# 拼接格式 图片地址 类别1 cx cy w h 类别2 cx cy w himg_annotation = img_namefor obj in root.findall('object'):class_name = obj.find('name').textxmin = float(obj.find('bndbox/xmin').text)ymin = float(obj.find('bndbox/ymin').text)xmax = float(obj.find('bndbox/xmax').text)ymax = float(obj.find('bndbox/ymax').text)# Convert to YOLO formatx_center = int((xmin + xmax) / 2)y_center = int((ymin + ymax) / 2)box_width = int((xmax - xmin))box_height = int((ymax - ymin))cls_id = cls_dic[class_name]# cls_id = 0img_annotation += f"\t\t{cls_id}\t{x_center}\t{y_center}\t{box_width}\t{box_height}\t"# Create a text file to save YOLO annotationsfile_name = os.path.splitext(os.path.basename(xml_path))[0] + '.txt'if os.path.isdir(save_directory):save_path = os.path.join(save_dir, file_name)else:save_path = save_dirwith open(save_path, 'a+') as file:file.write(img_annotation + '\n')return save_pathif __name__ == '__main__':# 保存为YOLOv3需要的txt格式save_directory = r'../data/VOC2007/yolo_annotation.txt'# 获取转换宽高为416x416之后的标签,用于进行等比例缩放xml_paths = glob.glob(os.path.join(r'../data/VOC2007/Annotations', "*"))# 转换之后的原图像img_paths = glob.glob(os.path.join(r"../data/VOC2007/YOLOv3_JPEGImages", "*"))# cls_dic = {"fish_gray": 0, "fish_red": 1, "fish_black": 2}# cls_dic = {"person": 0, "dog": 1, "cat": 2, "horse": 3}cls_dic = {"big_fish": 0, "small_fish": 1}for idx, xml_path in enumerate(xml_paths):img_path = img_paths[idx]saved_path = xml_to_yolo(xml_path, img_path, save_directory)print(f"YOLO annotations saved to: {saved_path}")
map.py
import glob
import json
import os
import shutil
import operator
import sys
import argparse
import mathimport numpy as npMINOVERLAP = 0.5 # default value (defined in the PASCAL VOC2012 challenge)parser = argparse.ArgumentParser()
parser.add_argument('-na', '--no-animation', help="no animation is shown.", action="store_true")
parser.add_argument('-np', '--no-plot', help="no plot is shown.", action="store_true")
parser.add_argument('-q', '--quiet', help="minimalistic console output.", action="store_true")
# argparse receiving list of classes to be ignored (e.g., python main.py --ignore person book)
parser.add_argument('-i', '--ignore', nargs='+', type=str, help="ignore a list of classes.")
# argparse receiving list of classes with specific IoU (e.g., python main.py --set-class-iou person 0.7)
parser.add_argument('--set-class-iou', nargs='+', type=str, help="set IoU for a specific class.")
args = parser.parse_args()'''0,0 ------> x (width)|| (Left,Top)| *_________| | || |y |_________|(height) *(Right,Bottom)
'''# if there are no classes to ignore then replace None by empty list
if args.ignore is None:args.ignore = []specific_iou_flagged = False
if args.set_class_iou is not None:specific_iou_flagged = True# make sure that the cwd() is the location of the python script (so that every path makes sense)
os.chdir(os.path.dirname(os.path.abspath(__file__)))# GT_PATH = os.path.join(os.getcwd(), 'input', 'ground-truth')
# DR_PATH = os.path.join(os.getcwd(), 'input', 'detection-results')
# # if there are no images then no animation can be shown
# IMG_PATH = os.path.join(os.getcwd(), 'input', 'images-optional')yolo3_path = os.getcwd().rsplit('\\', 1)[:1][0]
# 'E:\\pythonProject\\yolo3'
GT_PATH = os.path.join(yolo3_path, 'data', 'cal_map', 'input', 'ground-truth')
DR_PATH = os.path.join(yolo3_path, 'data', 'cal_map', 'input', 'detection-results')
# if there are no images then no animation can be shown
IMG_PATH = os.path.join(yolo3_path, 'data', 'cal_map', 'input', 'images-optional')
if os.path.exists(IMG_PATH): for dirpath, dirnames, files in os.walk(IMG_PATH):if not files:# no image files foundargs.no_animation = True
else:args.no_animation = True# try to import OpenCV if the user didn't choose the option --no-animation
show_animation = False
if not args.no_animation:try:import cv2show_animation = Trueexcept ImportError:print("\"opencv-python\" not found, please install to visualize the results.")args.no_animation = True# try to import Matplotlib if the user didn't choose the option --no-plot
draw_plot = False
if not args.no_plot:try:import matplotlib.pyplot as pltdraw_plot = Trueexcept ImportError:print("\"matplotlib\" not found, please install it to get the resulting plots.")args.no_plot = Truedef log_average_miss_rate(prec, rec, num_images):"""log-average miss rate:Calculated by averaging miss rates at 9 evenly spaced FPPI pointsbetween 10e-2 and 10e0, in log-space.output:lamr | log-average miss ratemr | miss ratefppi | false positives per imagereferences:[1] Dollar, Piotr, et al. "Pedestrian Detection: An Evaluation of theState of the Art." Pattern Analysis and Machine Intelligence, IEEETransactions on 34.4 (2012): 743 - 761."""# if there were no detections of that classif prec.size == 0:lamr = 0mr = 1fppi = 0return lamr, mr, fppifppi = (1 - prec)mr = (1 - rec)fppi_tmp = np.insert(fppi, 0, -1.0)mr_tmp = np.insert(mr, 0, 1.0)# Use 9 evenly spaced reference points in log-spaceref = np.logspace(-2.0, 0.0, num = 9)for i, ref_i in enumerate(ref):# np.where() will always find at least 1 index, since min(ref) = 0.01 and min(fppi_tmp) = -1.0j = np.where(fppi_tmp <= ref_i)[-1][-1]ref[i] = mr_tmp[j]# log(0) is undefined, so we use the np.maximum(1e-10, ref)lamr = math.exp(np.mean(np.log(np.maximum(1e-10, ref))))return lamr, mr, fppi"""throw error and exit
"""
def error(msg):print(msg)sys.exit(0)"""check if the number is a float between 0.0 and 1.0
"""
def is_float_between_0_and_1(value):try:val = float(value)if val > 0.0 and val < 1.0:return Trueelse:return Falseexcept ValueError:return False"""Calculate the AP given the recall and precision array1st) We compute a version of the measured precision/recall curve withprecision monotonically decreasing2nd) We compute the AP as the area under this curve by numerical integration.
"""
def voc_ap(rec, prec):"""--- Official matlab code VOC2012---mrec=[0 ; rec ; 1];mpre=[0 ; prec ; 0];for i=numel(mpre)-1:-1:1mpre(i)=max(mpre(i),mpre(i+1));endi=find(mrec(2:end)~=mrec(1:end-1))+1;ap=sum((mrec(i)-mrec(i-1)).*mpre(i));"""rec.insert(0, 0.0) # insert 0.0 at begining of listrec.append(1.0) # insert 1.0 at end of listmrec = rec[:]prec.insert(0, 0.0) # insert 0.0 at begining of listprec.append(0.0) # insert 0.0 at end of listmpre = prec[:]"""This part makes the precision monotonically decreasing(goes from the end to the beginning)matlab: for i=numel(mpre)-1:-1:1mpre(i)=max(mpre(i),mpre(i+1));"""# matlab indexes start in 1 but python in 0, so I have to do:# range(start=(len(mpre) - 2), end=0, step=-1)# also the python function range excludes the end, resulting in:# range(start=(len(mpre) - 2), end=-1, step=-1)for i in range(len(mpre)-2, -1, -1):mpre[i] = max(mpre[i], mpre[i+1])"""This part creates a list of indexes where the recall changesmatlab: i=find(mrec(2:end)~=mrec(1:end-1))+1;"""i_list = []for i in range(1, len(mrec)):if mrec[i] != mrec[i-1]:i_list.append(i) # if it was matlab would be i + 1"""The Average Precision (AP) is the area under the curve(numerical integration)matlab: ap=sum((mrec(i)-mrec(i-1)).*mpre(i));"""ap = 0.0for i in i_list:ap += ((mrec[i]-mrec[i-1])*mpre[i])return ap, mrec, mpre"""Convert the lines of a file to a list
"""
def file_lines_to_list(path):# open txt file lines to a listwith open(path) as f:content = f.readlines()# remove whitespace characters like `\n` at the end of each linecontent = [x.strip() for x in content]return content"""Draws text in image
"""
def draw_text_in_image(img, text, pos, color, line_width):font = cv2.FONT_HERSHEY_PLAINfontScale = 1lineType = 1bottomLeftCornerOfText = poscv2.putText(img, text,bottomLeftCornerOfText,font,fontScale,color,lineType)text_width, _ = cv2.getTextSize(text, font, fontScale, lineType)[0]return img, (line_width + text_width)"""Plot - adjust axes
"""
def adjust_axes(r, t, fig, axes):# get text width for re-scalingbb = t.get_window_extent(renderer=r)text_width_inches = bb.width / fig.dpi# get axis width in inchescurrent_fig_width = fig.get_figwidth()new_fig_width = current_fig_width + text_width_inchespropotion = new_fig_width / current_fig_width# get axis limitx_lim = axes.get_xlim()axes.set_xlim([x_lim[0], x_lim[1]*propotion])"""Draw plot using Matplotlib
"""
def draw_plot_func(dictionary, n_classes, window_title, plot_title, x_label, output_path, to_show, plot_color, true_p_bar):# sort the dictionary by decreasing value, into a list of tuplessorted_dic_by_value = sorted(dictionary.items(), key=operator.itemgetter(1))# unpacking the list of tuples into two listssorted_keys, sorted_values = zip(*sorted_dic_by_value)# if true_p_bar != "":"""Special case to draw in:- green -> TP: True Positives (object detected and matches ground-truth)- red -> FP: False Positives (object detected but does not match ground-truth)- pink -> FN: False Negatives (object not detected but present in the ground-truth)"""fp_sorted = []tp_sorted = []for key in sorted_keys:fp_sorted.append(dictionary[key] - true_p_bar[key])tp_sorted.append(true_p_bar[key])plt.barh(range(n_classes), fp_sorted, align='center', color='crimson', label='False Positive')plt.barh(range(n_classes), tp_sorted, align='center', color='forestgreen', label='True Positive', left=fp_sorted)# add legendplt.legend(loc='lower right')"""Write number on side of bar"""fig = plt.gcf() # gcf - get current figureaxes = plt.gca()r = fig.canvas.get_renderer()for i, val in enumerate(sorted_values):fp_val = fp_sorted[i]tp_val = tp_sorted[i]fp_str_val = " " + str(fp_val)tp_str_val = fp_str_val + " " + str(tp_val)# trick to paint multicolor with offset:# first paint everything and then repaint the first numbert = plt.text(val, i, tp_str_val, color='forestgreen', va='center', fontweight='bold')plt.text(val, i, fp_str_val, color='crimson', va='center', fontweight='bold')if i == (len(sorted_values)-1): # largest baradjust_axes(r, t, fig, axes)else:plt.barh(range(n_classes), sorted_values, color=plot_color)"""Write number on side of bar"""fig = plt.gcf() # gcf - get current figureaxes = plt.gca()r = fig.canvas.get_renderer()for i, val in enumerate(sorted_values):str_val = " " + str(val) # add a space beforeif val < 1.0:str_val = " {0:.2f}".format(val)t = plt.text(val, i, str_val, color=plot_color, va='center', fontweight='bold')# re-set axes to show number inside the figureif i == (len(sorted_values)-1): # largest baradjust_axes(r, t, fig, axes)# set window titlefig.canvas.manager.set_window_title(window_title)# write classes in y axistick_font_size = 12plt.yticks(range(n_classes), sorted_keys, fontsize=tick_font_size)"""Re-scale height accordingly"""init_height = fig.get_figheight()# comput the matrix height in points and inchesdpi = fig.dpiheight_pt = n_classes * (tick_font_size * 1.4) # 1.4 (some spacing)height_in = height_pt / dpi# compute the required figure height top_margin = 0.15 # in percentage of the figure heightbottom_margin = 0.05 # in percentage of the figure heightfigure_height = height_in / (1 - top_margin - bottom_margin)# set new heightif figure_height > init_height:fig.set_figheight(figure_height)# set plot titleplt.title(plot_title, fontsize=14)# set axis titles# plt.xlabel('classes')plt.xlabel(x_label, fontsize='large')# adjust size of windowfig.tight_layout()# save the plotfig.savefig(output_path)# show imageif to_show:plt.show()# close the plotplt.close()"""Create a ".temp_files/" and "output/" directory
"""
TEMP_FILES_PATH = ".temp_files"
if not os.path.exists(TEMP_FILES_PATH): # if it doesn't exist alreadyos.makedirs(TEMP_FILES_PATH)
# output_files_path = "output"
output_files_path = r'E:\pythonProject\yolo3\data\cal_map\output'
if os.path.exists(output_files_path): # if it exist already# reset the output directoryshutil.rmtree(output_files_path)os.makedirs(output_files_path)
if draw_plot:os.makedirs(os.path.join(output_files_path, "classes"))
if show_animation:os.makedirs(os.path.join(output_files_path, "images", "detections_one_by_one"))"""ground-truthLoad each of the ground-truth files into a temporary ".json" file.Create a list of all the class names present in the ground-truth (gt_classes).
"""
# get a list with the ground-truth files
ground_truth_files_list = glob.glob(GT_PATH + '/*.txt')
if len(ground_truth_files_list) == 0:error("Error: No ground-truth files found!")
ground_truth_files_list.sort()
# dictionary with counter per class
gt_counter_per_class = {}
counter_images_per_class = {}gt_files = []
for txt_file in ground_truth_files_list:#print(txt_file)file_id = txt_file.split(".txt", 1)[0]file_id = os.path.basename(os.path.normpath(file_id))# check if there is a correspondent detection-results filetemp_path = os.path.join(DR_PATH, (file_id + ".txt"))if not os.path.exists(temp_path):error_msg = "Error. File not found: {}\n".format(temp_path)error_msg += "(You can avoid this error message by running extra/intersect-gt-and-dr.py)"error(error_msg)lines_list = file_lines_to_list(txt_file)# create ground-truth dictionarybounding_boxes = []is_difficult = Falsealready_seen_classes = []for line in lines_list:try:if "difficult" in line:class_name, left, top, right, bottom, _difficult = line.split()is_difficult = Trueelse:class_name, left, top, right, bottom = line.split()except ValueError:error_msg = "Error: File " + txt_file + " in the wrong format.\n"error_msg += " Expected: <class_name> <left> <top> <right> <bottom> ['difficult']\n"error_msg += " Received: " + lineerror_msg += "\n\nIf you have a <class_name> with spaces between words you should remove them\n"error_msg += "by running the script \"remove_space.py\" or \"rename_class.py\" in the \"extra/\" folder."error(error_msg)# check if class is in the ignore list, if yes skipif class_name in args.ignore:continuebbox = left + " " + top + " " + right + " " +bottomif is_difficult:bounding_boxes.append({"class_name":class_name, "bbox":bbox, "used":False, "difficult":True})is_difficult = Falseelse:bounding_boxes.append({"class_name":class_name, "bbox":bbox, "used":False})# count that objectif class_name in gt_counter_per_class:gt_counter_per_class[class_name] += 1else:# if class didn't exist yetgt_counter_per_class[class_name] = 1if class_name not in already_seen_classes:if class_name in counter_images_per_class:counter_images_per_class[class_name] += 1else:# if class didn't exist yetcounter_images_per_class[class_name] = 1already_seen_classes.append(class_name)# dump bounding_boxes into a ".json" filenew_temp_file = TEMP_FILES_PATH + "/" + file_id + "_ground_truth.json"gt_files.append(new_temp_file)with open(new_temp_file, 'w') as outfile:json.dump(bounding_boxes, outfile)gt_classes = list(gt_counter_per_class.keys())
# let's sort the classes alphabetically
gt_classes = sorted(gt_classes)
n_classes = len(gt_classes)
#print(gt_classes)
#print(gt_counter_per_class)"""Check format of the flag --set-class-iou (if used)e.g. check if class exists
"""
if specific_iou_flagged:n_args = len(args.set_class_iou)error_msg = \'\n --set-class-iou [class_1] [IoU_1] [class_2] [IoU_2] [...]'if n_args % 2 != 0:error('Error, missing arguments. Flag usage:' + error_msg)# [class_1] [IoU_1] [class_2] [IoU_2]# specific_iou_classes = ['class_1', 'class_2']specific_iou_classes = args.set_class_iou[::2] # even# iou_list = ['IoU_1', 'IoU_2']iou_list = args.set_class_iou[1::2] # oddif len(specific_iou_classes) != len(iou_list):error('Error, missing arguments. Flag usage:' + error_msg)for tmp_class in specific_iou_classes:if tmp_class not in gt_classes:error('Error, unknown class \"' + tmp_class + '\". Flag usage:' + error_msg)for num in iou_list:if not is_float_between_0_and_1(num):error('Error, IoU must be between 0.0 and 1.0. Flag usage:' + error_msg)"""detection-resultsLoad each of the detection-results files into a temporary ".json" file.
"""
# get a list with the detection-results files
dr_files_list = glob.glob(DR_PATH + '/*.txt')
dr_files_list.sort()for class_index, class_name in enumerate(gt_classes):bounding_boxes = []for txt_file in dr_files_list:#print(txt_file)# the first time it checks if all the corresponding ground-truth files existfile_id = txt_file.split(".txt",1)[0]file_id = os.path.basename(os.path.normpath(file_id))temp_path = os.path.join(GT_PATH, (file_id + ".txt"))if class_index == 0:if not os.path.exists(temp_path):error_msg = "Error. File not found: {}\n".format(temp_path)error_msg += "(You can avoid this error message by running extra/intersect-gt-and-dr.py)"error(error_msg)lines = file_lines_to_list(txt_file)for line in lines:try:tmp_class_name, confidence, left, top, right, bottom = line.split()except ValueError:error_msg = "Error: File " + txt_file + " in the wrong format.\n"error_msg += " Expected: <class_name> <confidence> <left> <top> <right> <bottom>\n"error_msg += " Received: " + lineerror(error_msg)if tmp_class_name == class_name:#print("match")bbox = left + " " + top + " " + right + " " +bottombounding_boxes.append({"confidence":confidence, "file_id":file_id, "bbox":bbox})#print(bounding_boxes)# sort detection-results by decreasing confidencebounding_boxes.sort(key=lambda x:float(x['confidence']), reverse=True)with open(TEMP_FILES_PATH + "/" + class_name + "_dr.json", 'w') as outfile:json.dump(bounding_boxes, outfile)"""Calculate the AP for each class
"""
sum_AP = 0.0
ap_dictionary = {}
lamr_dictionary = {}
# open file to store the output
with open(output_files_path + "/output.txt", 'w') as output_file:output_file.write("# AP and precision/recall per class\n")count_true_positives = {}for class_index, class_name in enumerate(gt_classes):count_true_positives[class_name] = 0"""Load detection-results of that class"""dr_file = TEMP_FILES_PATH + "/" + class_name + "_dr.json"dr_data = json.load(open(dr_file))"""Assign detection-results to ground-truth objects"""nd = len(dr_data)tp = [0] * nd # creates an array of zeros of size ndfp = [0] * ndfor idx, detection in enumerate(dr_data):file_id = detection["file_id"]if show_animation:# find ground truth imageground_truth_img = glob.glob1(IMG_PATH, file_id + ".*")#tifCounter = len(glob.glob1(myPath,"*.tif"))if len(ground_truth_img) == 0:error("Error. Image not found with id: " + file_id)elif len(ground_truth_img) > 1:error("Error. Multiple image with id: " + file_id)else: # found image#print(IMG_PATH + "/" + ground_truth_img[0])# Load imageimg = cv2.imread(IMG_PATH + "/" + ground_truth_img[0])# load image with draws of multiple detectionsimg_cumulative_path = output_files_path + "/images/" + ground_truth_img[0]if os.path.isfile(img_cumulative_path):img_cumulative = cv2.imread(img_cumulative_path)else:img_cumulative = img.copy()# Add bottom border to imagebottom_border = 60BLACK = [0, 0, 0]img = cv2.copyMakeBorder(img, 0, bottom_border, 0, 0, cv2.BORDER_CONSTANT, value=BLACK)# assign detection-results to ground truth object if any# open ground-truth with that file_idgt_file = TEMP_FILES_PATH + "/" + file_id + "_ground_truth.json"ground_truth_data = json.load(open(gt_file))ovmax = -1gt_match = -1# load detected object bounding-boxbb = [ float(x) for x in detection["bbox"].split() ]for obj in ground_truth_data:# look for a class_name matchif obj["class_name"] == class_name:bbgt = [ float(x) for x in obj["bbox"].split() ]bi = [max(bb[0],bbgt[0]), max(bb[1],bbgt[1]), min(bb[2],bbgt[2]), min(bb[3],bbgt[3])]iw = bi[2] - bi[0] + 1ih = bi[3] - bi[1] + 1if iw > 0 and ih > 0:# compute overlap (IoU) = area of intersection / area of unionua = (bb[2] - bb[0] + 1) * (bb[3] - bb[1] + 1) + (bbgt[2] - bbgt[0]+ 1) * (bbgt[3] - bbgt[1] + 1) - iw * ihov = iw * ih / uaif ov > ovmax:ovmax = ovgt_match = obj# assign detection as true positive/don't care/false positiveif show_animation:status = "NO MATCH FOUND!" # status is only used in the animation# set minimum overlapmin_overlap = MINOVERLAPif specific_iou_flagged:if class_name in specific_iou_classes:index = specific_iou_classes.index(class_name)min_overlap = float(iou_list[index])if ovmax >= min_overlap:if "difficult" not in gt_match:if not bool(gt_match["used"]):# true positivetp[idx] = 1gt_match["used"] = Truecount_true_positives[class_name] += 1# update the ".json" filewith open(gt_file, 'w') as f:f.write(json.dumps(ground_truth_data))if show_animation:status = "MATCH!"else:# false positive (multiple detection)fp[idx] = 1if show_animation:status = "REPEATED MATCH!"else:# false positivefp[idx] = 1if ovmax > 0:status = "INSUFFICIENT OVERLAP""""Draw image to show animation"""if show_animation:height, widht = img.shape[:2]# colors (OpenCV works with BGR)white = (255,255,255)light_blue = (255,200,100)green = (0,255,0)light_red = (30,30,255)# 1st linemargin = 10v_pos = int(height - margin - (bottom_border / 2.0))text = "Image: " + ground_truth_img[0] + " "img, line_width = draw_text_in_image(img, text, (margin, v_pos), white, 0)text = "Class [" + str(class_index) + "/" + str(n_classes) + "]: " + class_name + " "img, line_width = draw_text_in_image(img, text, (margin + line_width, v_pos), light_blue, line_width)if ovmax != -1:color = light_redif status == "INSUFFICIENT OVERLAP":text = "IoU: {0:.2f}% ".format(ovmax*100) + "< {0:.2f}% ".format(min_overlap*100)else:text = "IoU: {0:.2f}% ".format(ovmax*100) + ">= {0:.2f}% ".format(min_overlap*100)color = greenimg, _ = draw_text_in_image(img, text, (margin + line_width, v_pos), color, line_width)# 2nd linev_pos += int(bottom_border / 2.0)rank_pos = str(idx+1) # rank position (idx starts at 0)text = "Detection #rank: " + rank_pos + " confidence: {0:.2f}% ".format(float(detection["confidence"])*100)img, line_width = draw_text_in_image(img, text, (margin, v_pos), white, 0)color = light_redif status == "MATCH!":color = greentext = "Result: " + status + " "img, line_width = draw_text_in_image(img, text, (margin + line_width, v_pos), color, line_width)font = cv2.FONT_HERSHEY_SIMPLEXif ovmax > 0: # if there is intersections between the bounding-boxesbbgt = [ int(round(float(x))) for x in gt_match["bbox"].split() ]cv2.rectangle(img,(bbgt[0],bbgt[1]),(bbgt[2],bbgt[3]),light_blue,2)cv2.rectangle(img_cumulative,(bbgt[0],bbgt[1]),(bbgt[2],bbgt[3]),light_blue,2)cv2.putText(img_cumulative, class_name, (bbgt[0],bbgt[1] - 5), font, 0.6, light_blue, 1, cv2.LINE_AA)bb = [int(i) for i in bb]cv2.rectangle(img,(bb[0],bb[1]),(bb[2],bb[3]),color,2)cv2.rectangle(img_cumulative,(bb[0],bb[1]),(bb[2],bb[3]),color,2)cv2.putText(img_cumulative, class_name, (bb[0],bb[1] - 5), font, 0.6, color, 1, cv2.LINE_AA)# show imagecv2.imshow("Animation", img)cv2.waitKey(20) # show for 20 ms# save image to outputoutput_img_path = output_files_path + "/images/detections_one_by_one/" + class_name + "_detection" + str(idx) + ".jpg"cv2.imwrite(output_img_path, img)# save the image with all the objects drawn to itcv2.imwrite(img_cumulative_path, img_cumulative)#print(tp)# compute precision/recallcumsum = 0for idx, val in enumerate(fp):fp[idx] += cumsumcumsum += valcumsum = 0for idx, val in enumerate(tp):tp[idx] += cumsumcumsum += val#print(tp)rec = tp[:]for idx, val in enumerate(tp):rec[idx] = float(tp[idx]) / gt_counter_per_class[class_name]#print(rec)prec = tp[:]for idx, val in enumerate(tp):prec[idx] = float(tp[idx]) / (fp[idx] + tp[idx])#print(prec)ap, mrec, mprec = voc_ap(rec[:], prec[:])sum_AP += aptext = "{0:.2f}%".format(ap*100) + " = " + class_name + " AP " #class_name + " AP = {0:.2f}%".format(ap*100)"""Write to output.txt"""rounded_prec = [ '%.2f' % elem for elem in prec ]rounded_rec = [ '%.2f' % elem for elem in rec ]output_file.write(text + "\n Precision: " + str(rounded_prec) + "\n Recall :" + str(rounded_rec) + "\n\n")if not args.quiet:print(text)ap_dictionary[class_name] = apn_images = counter_images_per_class[class_name]lamr, mr, fppi = log_average_miss_rate(np.array(prec), np.array(rec), n_images)lamr_dictionary[class_name] = lamr"""Draw plot"""if draw_plot:plt.plot(rec, prec, '-o')# add a new penultimate point to the list (mrec[-2], 0.0)# since the last line segment (and respective area) do not affect the AP valuearea_under_curve_x = mrec[:-1] + [mrec[-2]] + [mrec[-1]]area_under_curve_y = mprec[:-1] + [0.0] + [mprec[-1]]plt.fill_between(area_under_curve_x, 0, area_under_curve_y, alpha=0.2, edgecolor='r')# set window titlefig = plt.gcf() # gcf - get current figurefig.canvas.manager.set_window_title('AP ' + class_name)# set plot titleplt.title('class: ' + text)#plt.suptitle('This is a somewhat long figure title', fontsize=16)# set axis titlesplt.xlabel('Recall')plt.ylabel('Precision')# optional - set axesaxes = plt.gca() # gca - get current axesaxes.set_xlim([0.0,1.0])axes.set_ylim([0.0,1.05]) # .05 to give some extra space# Alternative option -> wait for button to be pressed#while not plt.waitforbuttonpress(): pass # wait for key display# Alternative option -> normal display#plt.show()# save the plotfig.savefig(output_files_path + "/classes/" + class_name + ".png")plt.cla() # clear axes for next plotif show_animation:cv2.destroyAllWindows()output_file.write("\n# mAP of all classes\n")mAP = sum_AP / n_classestext = "mAP = {0:.2f}%".format(mAP*100)output_file.write(text + "\n")print(text)"""Draw false negatives
"""
if show_animation:pink = (203,192,255)for tmp_file in gt_files:ground_truth_data = json.load(open(tmp_file))#print(ground_truth_data)# get name of corresponding imagestart = TEMP_FILES_PATH + '/'img_id = tmp_file[tmp_file.find(start)+len(start):tmp_file.rfind('_ground_truth.json')]img_cumulative_path = output_files_path + "/images/" + img_id + ".jpg"img = cv2.imread(img_cumulative_path)if img is None:img_path = IMG_PATH + '/' + img_id + ".jpg"img = cv2.imread(img_path)# draw false negativesfor obj in ground_truth_data:if not obj['used']:bbgt = [ int(round(float(x))) for x in obj["bbox"].split() ]cv2.rectangle(img,(bbgt[0],bbgt[1]),(bbgt[2],bbgt[3]),pink,2)cv2.imwrite(img_cumulative_path, img)# remove the temp_files directory
shutil.rmtree(TEMP_FILES_PATH)"""Count total of detection-results
"""
# iterate through all the files
det_counter_per_class = {}
for txt_file in dr_files_list:# get lines to listlines_list = file_lines_to_list(txt_file)for line in lines_list:class_name = line.split()[0]# check if class is in the ignore list, if yes skipif class_name in args.ignore:continue# count that objectif class_name in det_counter_per_class:det_counter_per_class[class_name] += 1else:# if class didn't exist yetdet_counter_per_class[class_name] = 1
#print(det_counter_per_class)
dr_classes = list(det_counter_per_class.keys())"""Plot the total number of occurences of each class in the ground-truth
"""
if draw_plot:window_title = "ground-truth-info"plot_title = "ground-truth\n"plot_title += "(" + str(len(ground_truth_files_list)) + " files and " + str(n_classes) + " classes)"x_label = "Number of objects per class"output_path = output_files_path + "/ground-truth-info.png"to_show = Falseplot_color = 'forestgreen'draw_plot_func(gt_counter_per_class,n_classes,window_title,plot_title,x_label,output_path,to_show,plot_color,'',)"""Write number of ground-truth objects per class to results.txt
"""
with open(output_files_path + "/output.txt", 'a') as output_file:output_file.write("\n# Number of ground-truth objects per class\n")for class_name in sorted(gt_counter_per_class):output_file.write(class_name + ": " + str(gt_counter_per_class[class_name]) + "\n")"""Finish counting true positives
"""
for class_name in dr_classes:# if class exists in detection-result but not in ground-truth then there are no true positives in that classif class_name not in gt_classes:count_true_positives[class_name] = 0
#print(count_true_positives)"""Plot the total number of occurences of each class in the "detection-results" folder
"""
if draw_plot:window_title = "detection-results-info"# Plot titleplot_title = "detection-results\n"plot_title += "(" + str(len(dr_files_list)) + " files and "count_non_zero_values_in_dictionary = sum(int(x) > 0 for x in list(det_counter_per_class.values()))plot_title += str(count_non_zero_values_in_dictionary) + " detected classes)"# end Plot titlex_label = "Number of objects per class"output_path = output_files_path + "/detection-results-info.png"to_show = Falseplot_color = 'forestgreen'true_p_bar = count_true_positivesdraw_plot_func(det_counter_per_class,len(det_counter_per_class),window_title,plot_title,x_label,output_path,to_show,plot_color,true_p_bar)"""Write number of detected objects per class to output.txt
"""
with open(output_files_path + "/output.txt", 'a') as output_file:output_file.write("\n# Number of detected objects per class\n")for class_name in sorted(dr_classes):n_det = det_counter_per_class[class_name]text = class_name + ": " + str(n_det)text += " (tp:" + str(count_true_positives[class_name]) + ""text += ", fp:" + str(n_det - count_true_positives[class_name]) + ")\n"output_file.write(text)"""Draw log-average miss rate plot (Show lamr of all classes in decreasing order)
"""
if draw_plot:window_title = "lamr"plot_title = "log-average miss rate"x_label = "log-average miss rate"output_path = output_files_path + "/lamr.png"to_show = Falseplot_color = 'royalblue'draw_plot_func(lamr_dictionary,n_classes,window_title,plot_title,x_label,output_path,to_show,plot_color,"")"""Draw mAP plot (Show AP's of all classes in decreasing order)
"""
if draw_plot:window_title = "mAP"plot_title = "mAP = {0:.2f}%".format(mAP*100)x_label = "Average Precision"output_path = output_files_path + "/mAP.png"to_show = Trueplot_color = 'royalblue'draw_plot_func(ap_dictionary,n_classes,window_title,plot_title,x_label,output_path,to_show,plot_color,"")
这篇关于YOLOv3+mAP实现金鱼检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






