variational专题

ML17_变分推断Variational Inference
1. KL散度 KL散度(Kullback-Leibler divergence),也称为相对熵(relative entropy),是由Solomon Kullback和Richard Leibler在1951年引入的一种衡量两个概率分布之间差异的方法。KL散度不是一种距离度量,因为它不满足距离度量的对称性和三角不等式的要求。但是,它仍然被广泛用于量化两个概率分布之间的“接近程度”。 在

变分自编码器(Variational Autoencoder, VAE):深入理解与应用
变分自编码器(Variational Autoencoder, VAE):深入理解与应用 在深度学习的广阔领域中,生成模型一直是研究的热点之一。其中,VAE(变分自编码器)作为AE(自编码器)的一种扩展,以其独特的优势在生成任务中展现了卓越的性能。本文将深入探讨VAE相对于AE的改进之处,并解析这些改进如何提升模型的生成能力和泛化性能。 一、引言 自编码器(Autoencoder, AE

Autoencoder(AE)、Variational Autoencoder(VAE)和Diffusion Models(DM)了解
Autoencoder (AE) 工作原理: Autoencoder就像一个数据压缩机器。它由两部分组成: 编码器:将输入数据压缩成一个小小的代码。解码器:将这个小代码还原成尽可能接近原始输入的数据。 优点和应用: 简单易懂:用于学习数据的特征和去除噪声。应用场景:例如可以用来缩小图像的大小但保留关键特征,或者去除文本数据中的错误。 挑战: 数据损坏:如果输入数据太乱,编码器可能无法有
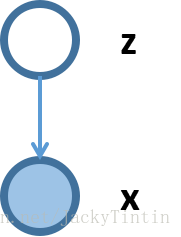
Autoencorder理解(5):VAE(Variational Auto-Encoder,变分自编码器)
reference: http://blog.csdn.net/jackytintin/article/details/53641885 近年,随着有监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关

Autoencorder理解(7):Variational Autoencoder
以下将分为6个部分介绍: vae结构框架vae与ae区别提及一下为什么要采样如何优化vae应用vae生成/抽象看待vae学习 1.框架: 先来看一下VAE的结构框架,并先预告一下结论: VAE 包括 encoder (模块 1)和 decoder(模块 4) 两个神经网络。两者通过模块 2、3 连接成一个大网络。利益于 reparemeterization 技巧,我们可以使用常规
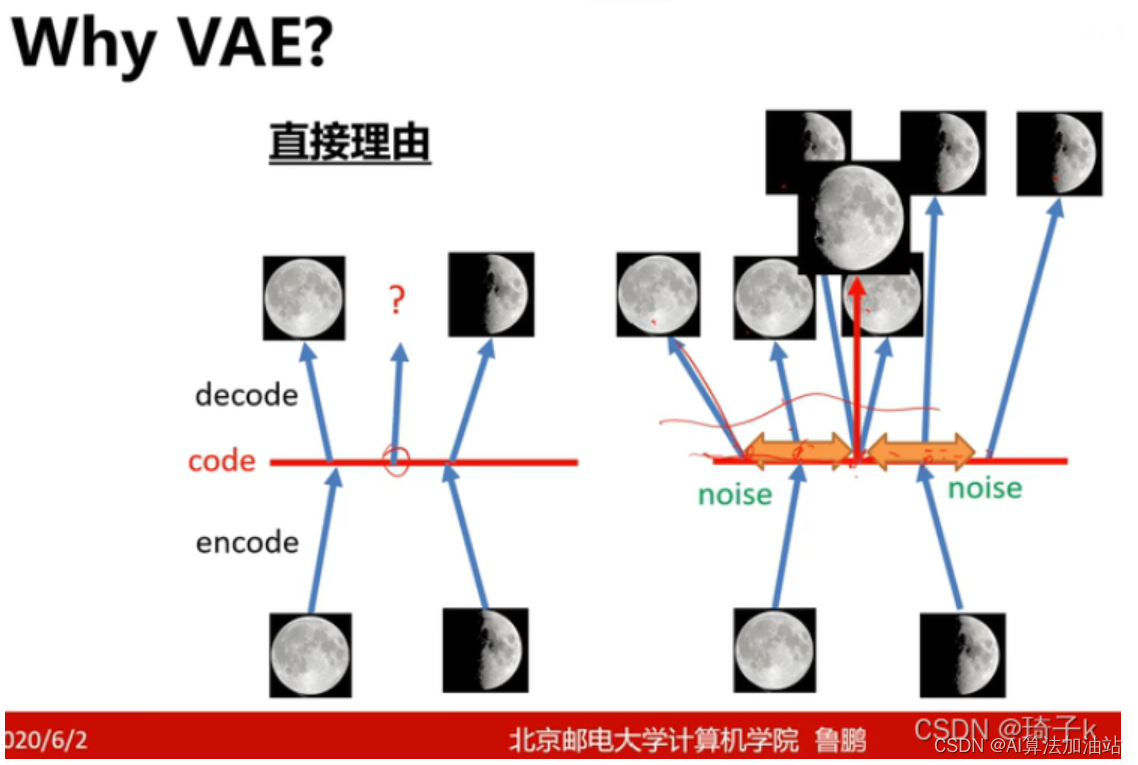
变分自编码器(Variational Autoencoder, VAE)
目录 why VAE: 关于变分自编码器,这篇文章讲的不错 1. 自编码器(Autoencoder)的基础 2. 引入概率图模型 3. 重参数化技巧 4. 损失函数 5. 应用 变分自编码器(Variational Autoencoder, VAE) why VAE: 关于变分自编码器,这篇文章讲的不错 机器学习方法—优雅的模型(一):变分自编码器(VAE

【Deep Learning】Variational Autoencoder ELBO:优美的数学推导
Variational Autoencoder In this note, we talk about the generation model, where x x x represents the given dataset, z z z represents the latent variable, θ , ϕ \theta,\phi θ,ϕ denote the parameter
variational approximation posterior distribution (变分近似)
变分近似是一种数学方法,用来近似复杂系统中难以精确计算的概率分布。在统计和机器学习领域,我们经常会遇到需要估计后验分布的情况,后验分布是指在给定观测数据后,我们对未知量(比如模型的参数)的不确定性的概率描述。 想象你有一堆数据,你想根据这些数据来猜测某些你不知道的量(比如一个事件发生的概率)。在贝叶斯统计中,你会用到后验分布来表达你的猜测。但问题在于,对于很多复杂的模型,这个后验分布非常难以直接

tensorflow1.1/variational_autoencoder
环境tensorflow1.1,matplotlib2.02,python3 近年,非监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关注 VAE:模型结构: 其中:loss = mse+KLDivergence #coding:utf-8

变分互信息蒸馏(Variational mutual information KD)
原文标题是Variational Information Distillation for Knowledge Transfer,是CVPR2019的录用paper。 VID方法 思路比较简单,就是利用互信息(mutual information,MI)的角度,增加teacher网络与student网络中间层特征的MI,motivation是因为MI可以表示两个变量的依赖程度,MI越大,表明

深度通信网络专栏(4)|自编码器:Blind Channel Equalization using Variational Autoencoders
本文地址:https://arxiv.org/abs/1803.01526 文章目录 前言文章主要贡献系统模型变分自编码器引入神经网络 仿真结果 前言 深度通信网络专栏|自编码器:整理2018-2019年使用神经网络实现通信系统自编码器的论文,一点拙见,如有偏颇,望不吝赐教,顺颂时祺。 文章主要贡献 原来提出的最大似然估计下的盲信道均衡使用期望最大或近似期望最大,计算复杂度
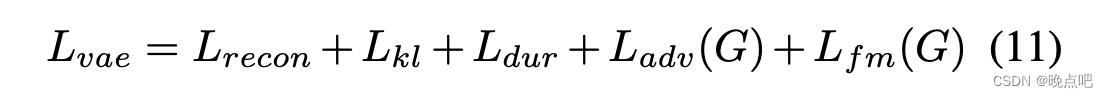
VITS(Conditional Variational Autoencoder with Adversarial Learning)论文解读及实现(一)
此篇为VITS论文解读第一部份 论文地址Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech模型使用了VAE,GAN,FLOW以及transorflomer(文本处理有用到),即除了未diffusion模型,将生成式模型都融入进来了,是一篇集大成的文章。涉及的知识点和公
【论文阅读】Variational Graph Auto-Encoder
0、基本信息 会议:2016-NIPS作者:Thomas N. Kipf,Max Welling文章链接:Variational Graph Auto-Encoder代码链接:Variational Graph Auto-Encoder 1、介绍 本文提出一个变分图自编码器,一个基于变分自编码(VAE)的,用于在图结构数据上无监督学习的框架。其基本思路是:用已知的图(graph)经过编码(图
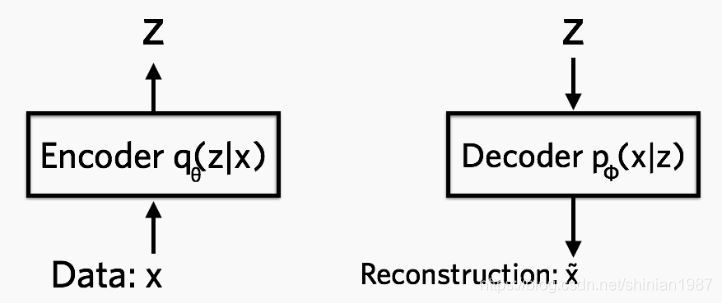
机器学习:VAE(Variational Autoencoder) 模型
VAE 模型是一种有趣的生成模型,与GAN相比,VAE 有更加完备的数学理论(引入了隐变量),理论推导更加显性,训练相对来说更加容易。 VAE 可以从神经网络的角度或者概率图模型的角度来解释。 VAE 全名叫 变分自编码器,是从之前的 auto-encoder 演变过来的,auto-encoder 也就是自编码器,自编码器,顾名思义,就是可以自己对自己进行编码,重构。所以 AE 模型一般都由两
逐次变分模态分解(Sequential Variational Mode Decomposition,SVMD)(附代码)
代码原理 逐次变分模态分解(Sequential Variational Mode Decomposition,SVMD)是一种用于信号处理和数据分析的方法。它可以将复杂的信号分解为一系列模态函数,每个模态函数代表了信号中的一个特定频率成分。SVMD的主要目标是提取信号中的不同频率成分,并将其重构为原始信号。 SVMD的基本原理是通过变分模态分解的方式将信号分解为多个模态函数。在每个迭代步骤中
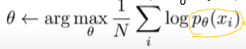
Variational Inference 笔记 from UCB CS 285 Sergey Levine
Part 1 Probabilistic models with latent variable models, evidence variable and query variable: 我们要这么想 p(x), p(z) 和 p(x|z): (下图右上角 应该是 mu_nn(z), sigma_nn(z) ) 这里牵扯到了第一个神经网络。 现在要明确,我们的目标是

22-变分推断-variational inference
文章目录 1.背景1.1 频率派1.1.1 回归问题1.1.2 SVM支持向量机(分类问题)1.1.3 EM 1.2 贝叶斯派 2.公式推导2.1平均场理论 3.再回首3.1 符号规范 4. SGVI-随机梯度变分推断4.1求梯度 ∇ ϕ L ( ϕ ) \nabla_{\phi}L(\phi) ∇ϕL(ϕ)4.2 梯度采样4.3 重参数化技巧 1.背景 关于变分推断,现在补

论文阅读笔记VPE《Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images》
变分原型编码器VPE:原型图象的one-shot learning 将真实输入图像到对应的原型图像的图像转换任务当作元任务。因此VPE学习的是图像相似性和原型图像。Prototypical Images 1 核心思想 首先,明确一下原型图像的概念:标准形式、没有任何形变和干扰信息的原始符号,也可以成为典范域。(结合下图理解) 上面一行是交通标识,下面一行是徽标。可以看出是没有任何背景的、