本文主要是介绍tensorflow1.1/variational_autoencoder,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境tensorflow1.1,matplotlib2.02,python3
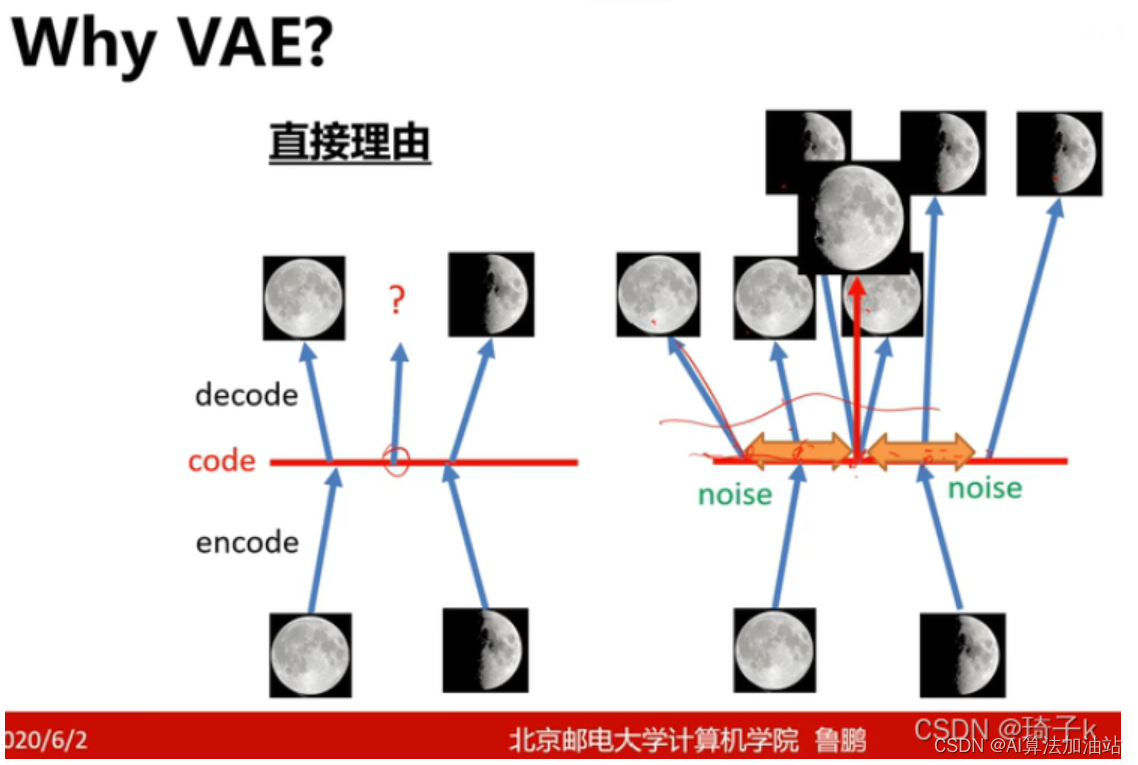
近年,非监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关注
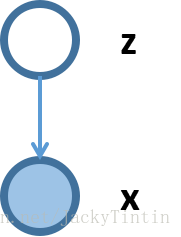
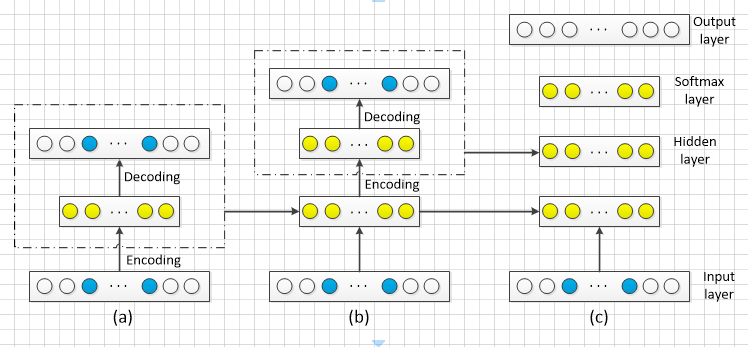
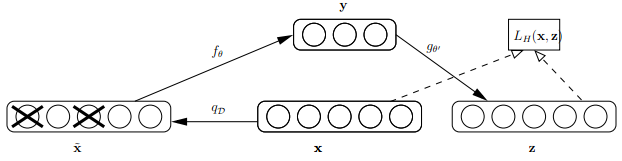
VAE:模型结构:

其中:loss = mse+KLDivergence
#coding:utf-8
"""
tensorflow 1.1
matplotlib 2.02
"""
import tensorflow as tf
import numpy as np
import input_data
import matplotlib.pyplot as pltinput_dim = 784
hidden_encoder_dim = 1200
hidden_decoder_dim = 1200
latent_dim = 200
epochs = 3000
batch_size = 100
N_pictures=3mnist = input_data.read_data_sets('mnist/')def weight_variable(shape):#tf.truncated_normal()截断的标准正态分布return tf.Variable(tf.truncated_normal(shape,stddev=0.001))def bias_variable(shape):return tf.Variable(tf.truncated_normal(shape))x = tf.placeholder('float32',[None,input_dim])
#在全连接层加入l2_regularization
l2_loss = tf.constant(0.0)#encoder网络
w_encoder1 =weight_variable([input_dim,hidden_encoder_dim])
b_encoder1 = bias_variable([hidden_encoder_dim])
encoder1 = tf.nn.relu(tf.matmul(x,w_encoder1)+b_encoder1)
#第一层的l2_loss
l2_loss += tf.nn.l2_loss(w_encoder1)#定义一个mu网络
mu_w_encoder2 = weight_variable([hidden_encoder_dim,latent_dim])
mu_b_encoder2 = bias_variable([latent_dim])
mu_encoder2 = tf.matmul(encoder1,mu_w_encoder2)+mu_b_encoder2
#mu网络的l2_loss
l2_loss += tf.nn.l2_loss(mu_w_encoder2)#定义一个var网络
var_w_encoder2 = weight_variable([hidden_encoder_dim,latent_dim])
var_b_encoder2 = bias_variable([latent_dim])
var_encoder2 = tf.matmul(encoder1,var_w_encoder2)+var_b_encoder2
#var网络的l2_loss
l2_loss += tf.nn.l2_loss(var_w_encoder2)#抽样
#生成标准正态分布
epsilon = tf.random_normal(tf.shape(var_encoder2))
new_var_encoder2 = tf.sqrt(tf.exp(var_encoder2))
#z的维度是latent_dim
z = mu_encoder2+tf.multiply(new_var_encoder2,epsilon)#定义decoder网络
w_decoder1 = weight_variable([latent_dim,hidden_decoder_dim])
b_decoder1 = bias_variable([hidden_decoder_dim])
decoder1 = tf.nn.relu(tf.matmul(z,w_decoder1)+b_decoder1)
l2_loss += tf.nn.l2_loss(w_decoder1)
w_decoder2 = weight_variable([hidden_decoder_dim,input_dim])
b_decoder2 = bias_variable([input_dim])
#输出层没有使用激活函数(加入激活函数后面用log_px_given_z,不加入激活函数用cost1)
decoder2 = tf.nn.sigmoid(tf.matmul(decoder1,w_decoder2)+b_decoder2)
l2_loss += tf.nn.l2_loss(w_decoder2)#计算cost
log_px_given_z = -tf.reduce_sum(x*tf.log(decoder2+1e-10)+(1-x)*tf.log(1-decoder2+1e-10),1)
#cost1 = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=decoder2,labels=x),reduction_indices=1)
#计算KL Divergence
KLD = -0.5*tf.reduce_sum(1+var_encoder2-tf.pow(mu_encoder2,2)-tf.exp(var_encoder2),reduction_indices=1)
cost = tf.reduce_mean(log_px_given_z+KLD)
#加上regularization
regularized_cost = cost + l2_losstrain = tf.train.AdamOptimizer(0.01).minimize(cost)with tf.Session() as sess:init = tf.global_variables_initializer()sess.run(init)#画图,2行5列返回图和子图figure_,a = plt.subplots(2,N_pictures,figsize=(6,4))#开始交互模式plt.ion()#测试的图view_figures = mnist.test.images[:N_pictures]for i in range(N_pictures):#将图片reshape为28行28列显示a[0][i].imshow(np.reshape(view_figures[i],(28,28)))#清空x轴,y轴坐标a[0][i].set_xticks(())a[0][i].set_yticks(())for step in range(10000):batch_x,batch_y = mnist.train.next_batch(batch_size)#encoder3和decoder3需要进行run_,encoded,decoded,c = sess.run([train,z,decoder2,cost],feed_dict={x:batch_x})if step % 1000 ==0:print('= = = = = = > > > > > >','train loss:% .4f' % c)#将真实的图片和autoencoder后的图片对比decoder_figures = sess.run(decoder2,feed_dict={x:view_figures})for i in range(N_pictures):#清除第一行图片a[1][i].clear()a[1][i].imshow(np.reshape(decoder_figures[i],(28,28)))a[1][i].set_xticks(())a[1][i].set_yticks(())plt.draw()plt.pause(1)plt.ioff() #关闭交互模式"""
with tf.Session() as sess:init = tf.global_variables_initializer()sess.run(init)for epoch in range(epochs):batch_x,batch_y = mnist.train.next_batch(batch_size)_,c = sess.run([train,cost],feed_dict={x:batch_x})if epoch % 100 == 0:print('- - - - - - > > > > > > epoch: ',int(epoch/100),'cost: %.4f' %c)#输出结果可视化encoder_result = sess.run(z,feed_dict={x:mnist.test.images})plt.scatter(encoder_result[:,0],encoder_result[:,1],c = mnist.test.labels,label='mnist distributions')plt.legend(loc='best')plt.title('different mnist digits shows in figure')plt.colorbar()plt.show()"""结果


聚类效果:

这篇关于tensorflow1.1/variational_autoencoder的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!