本文主要是介绍Tensorflow - Tutorial (5) : 降噪自动编码器(Denoising Autoencoder),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Denoising Autoencoder
在神经网络模型训练阶段开始前,通过Autoencoder对模型进行预训练可确定编码器 W 的初始参数值。然而,受模型复杂度、训练集数据量以及数据噪音等问题的影响,通过Autoencoder得到的初始模型往往存在过拟合的风险。关于Autoencoder的介绍请参考:自动编码器(Autoencoder)。
在介绍Denoising Autoencoder(降噪自动编码器)之前,我们先来回顾一下机器学习中的过拟合的问题,如下图所示,其展示了训练数据量和噪音数量对模型过拟合问题的影响。图中红色区域表示模型过拟合,蓝色区域表示欠拟合,绿色区域是我们希望得到的模型。从图中可以看出,当训练数据越少,数据噪音越多时,模型越容易过拟合。
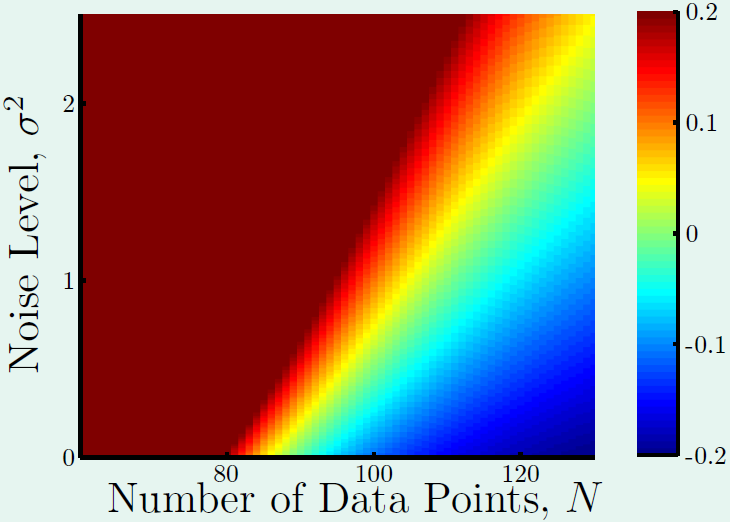
在模型的复杂度和数据量都已经确定的前提下,防止过拟合的一种办法是减少数据中的噪音数量,即对训练集数据做清洗操作。然而,如果我们无法检测并删除掉数据中的噪音。另一种防止过拟合的办法就是给数据中增加噪音,这看似与之前的结论矛盾,但却是增强模型鲁棒性的一种有效方式,我们以手写数字识别为例,Autoencoder所做的操作是首先对输入图片编码,经过隐含层后解码重构原始图片中的数字信息。假如现在我们输入的是一副含有一定噪音的图片,例如图片中有污点,图片中的数字倾斜等,并且我们仍然希望解码后的图片是一副干净正确的图片,这就需要编码器不仅有编码功能,还得有去噪音的作用,通过这种方式训练出的模型具有更强的鲁棒性。
Denoising Autoencoder(降噪自动编码器)就是在Autoencoder的基础之上,为了防止过拟合问题而对输入的数据(网络的输入层)加入噪音,使学习得到的编码器
- Extracting and composing robust features with denoising autoencoders.
论文中关于Denoising Autoencoder的示意图如下,其中 x 是原始的输入数据,Denoising Autoencoder以一定概率把输入层节点的值置为0,从而得到含有噪音的模型输入
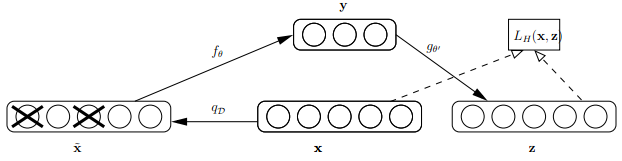
Bengio对Denoising Autoencoder作出了以下直观的解释:
- Denoising Autoencoder与人的感知机理类似,比如人眼看物体时,如果物体某一小部分被遮住了,人依然能够将其识别出来。
- 人在接收到多模态信息时(比如声音,图像等),少了其中某些模态的信息有时也不会造成太大影响。
- Autoencoder的本质是学习一个相等函数,即网络的输入和重构后的输出相等,这种相等函数的表示有个缺点就是当测试样本和训练样本不符合同一分布,即相差较大时,效果不好,而Denoising Autoencoder在这方面的处理有所进步。
实验代码
MNIST数据集的格式与数据预处理代码input_data.py的讲解请参考 :Tutorial (2)
实验代码如下:
import tensorflow as tf
import numpy as np
import input_datamnist_width = 28
n_visible = mnist_width * mnist_width
n_hidden = 500
corruption_level = 0.3# 输入的一张图片用28x28=784的向量表示.
X = tf.placeholder("float", [None, n_visible], name='X')# 用于将部分输入数据置为0
mask = tf.placeholder("float", [None, n_visible], name='mask')# create nodes for hidden variables
W_init_max = 4 * np.sqrt(6. / (n_visible + n_hidden))
W_init = tf.random_uniform(shape=[n_visible, n_hidden],minval=-W_init_max,maxval=W_init_max)
# 编码器
W = tf.Variable(W_init, name='W')#shape:784x500
b = tf.Variable(tf.zeros([n_hidden]), name='b')#隐含层的偏置
#解码器
W_prime = tf.transpose(W)
b_prime = tf.Variable(tf.zeros([n_visible]), name='b_prime')def model(X, mask, W, b, W_prime, b_prime):tilde_X = mask * X # corrupted XY = tf.nn.sigmoid(tf.matmul(tilde_X, W) + b) # hidden stateZ = tf.nn.sigmoid(tf.matmul(Y, W_prime) + b_prime) # reconstructed inputreturn Z# build model graph
Z = model(X, mask, W, b, W_prime, b_prime)# create cost function
cost = tf.reduce_sum(tf.pow(X - Z, 2)) # minimize squared error
train_op = tf.train.GradientDescentOptimizer(0.02).minimize(cost) # construct an optimizer# load MNIST data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels# Launch the graph in a session
with tf.Session() as sess:# you need to initialize all variablestf.initialize_all_variables().run()for i in range(100):for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):input_ = trX[start:end]mask_np = np.random.binomial(1, 1 - corruption_level, input_.shape)sess.run(train_op, feed_dict={X: input_, mask: mask_np})mask_np = np.random.binomial(1, 1 - corruption_level, teX.shape)print(i, sess.run(cost, feed_dict={X: teX, mask: mask_np}))这篇关于Tensorflow - Tutorial (5) : 降噪自动编码器(Denoising Autoencoder)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




