本文主要是介绍论文阅读笔记VPE《Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
变分原型编码器VPE:原型图象的one-shot learning
将真实输入图像到对应的原型图像的图像转换任务当作元任务。因此VPE学习的是图像相似性和原型图像。Prototypical Images
1 核心思想
首先,明确一下原型图像的概念:标准形式、没有任何形变和干扰信息的原始符号,也可以成为典范域。(结合下图理解)

上面一行是交通标识,下面一行是徽标。可以看出是没有任何背景的、没有任何形变的。
本文的核心思想基于自动编码器对于实际拍摄采集的图像生成原型图像,并利用最近邻算法解决小样本的图标或标识分类问题。这里首先指出,拍摄采集到的图像经常会背景模糊,被光照因素干扰或产生形变等,这些都算是噪声。在生成原型图像的过程中,诱导同类图像的相似性,并生成原型图像的潜在特征空间分布。
2 实现过程
方法架构

网络结构
目标函数
与一般的VAE损失函数略有不同,本文要比较原型图像t tt和输入图像x xx之间的重构差异
损失分为两项,重构损失和分布正则项。重构损失采用的是二元交叉熵损失函数BCE,;KL散度用来约束潜在空间的分布。
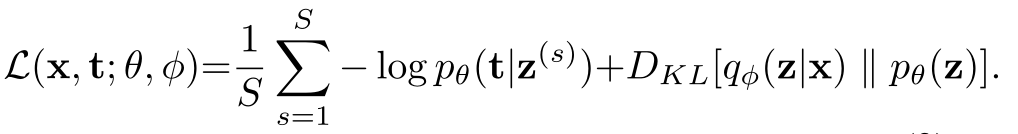
训练策略
SGD
重构出的原型
左侧是见过的类,右侧为未未见过的类。我理解的是分别是训练集和测试集。

3 创新点总结
引入原型图像的概念,通过VAE重构原型图像。
4 算法评价
本文利用VAE结构生成原型图像,并利用编码器作为特征提取器,通过比较隐藏向量之间的欧氏距离寻找最为接近的样本,实现分类任务。正如作者自己左说,这个VAE结构可以看做一种降噪网络,把图像中的干扰信息排除,保留最直观最重要的原型图像。但本文无论是采用的VAE生成式模型还是利用隐藏空间中的特征向量进行最近邻分类都不是非常新颖的想法,唯一的创新可能就是原型图像这一概念了吧,但这一概念也并不具备普遍性,如果数据集图像质量普遍较高,这一做法就退化为一个简单的最近邻分类了。
————————————————
版权声明:本文为CSDN博主「深视」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36104364/article/details/106438467
对数据集的要求比较特殊,可以理解为对特定任务很有效吧。也只有这些交通标志和徽标才具有清晰且唯一的原型图像了吧。
这篇关于论文阅读笔记VPE《Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







