本文主要是介绍深度通信网络专栏(4)|自编码器:Blind Channel Equalization using Variational Autoencoders,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文地址:https://arxiv.org/abs/1803.01526
文章目录
- 前言
- 文章主要贡献
- 系统模型
- 变分自编码器
- 引入神经网络
- 仿真结果
前言
深度通信网络专栏|自编码器:整理2018-2019年使用神经网络实现通信系统自编码器的论文,一点拙见,如有偏颇,望不吝赐教,顺颂时祺。
文章主要贡献
原来提出的最大似然估计下的盲信道均衡使用期望最大或近似期望最大,计算复杂度过高。
本文提出用变分自编码器(VAE)实现最大似然估计下的盲信道均衡,与恒模算法(CMA)相比可达到更低的ber和更低的信道获取时延。VAE的性能接近非盲自适应线性最小均方误差均衡器。
VAE由两层卷积层和少量自由参数构成,虽然计算复杂度比CMA高,但是需要估计的自由参数个数较少。
系统模型
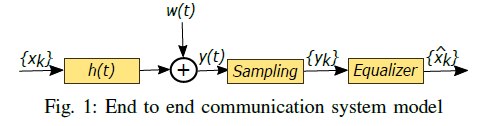
一个端到端系统可表示为以上结构, y = x ∗ h + w \mathbf{y}=\mathbf{x} * \mathbf{h}+\mathbf{w} y=x∗h+w
使用QPSK调制,则 x = x I + j ⋅ x Q \mathrm{x}=\mathrm{x}^{I}+j \cdot \mathrm{x}^{Q} x=xI+j⋅xQ, h = h I + j ⋅ h Q \mathbf{h}=\mathbf{h}^{I}+j \cdot \mathbf{h}^{Q} h=hI+j⋅hQ, y = y I + j ⋅ y Q \mathbf{y}=\mathbf{y}^{I}+j \cdot \mathbf{y}^{Q} y=yI+j⋅yQ
给定x,y 的条件概率函数为:
p θ ( y ∣ x ) = p θ ( y I ∣ x I ) p θ ( y Q ∣ x Q ) = 1 ( π σ w 2 ) N ⋅ e − ∥ y − x ∗ h ∥ 2 / σ w 2 \begin{aligned} p_{\boldsymbol{\theta}}(\mathbf{y} | \mathbf{x}) &=p_{\boldsymbol{\theta}}\left(\mathbf{y}^{I} | \mathbf{x}^{I}\right) p_{\boldsymbol{\theta}}\left(\mathbf{y}^{Q} | \mathbf{x}^{Q}\right) \\ &=\frac{1}{\left(\pi \sigma_{w}^{2}\right)^{N}} \cdot e^{-\|\mathbf{y}-\mathbf{x} * \mathbf{h}\|^{2} / \sigma_{w}^{2}} \end{aligned} pθ(y∣x)=pθ(yI∣xI)pθ(yQ∣xQ)=(πσw2)N1⋅e−∥y−x∗h∥2/σw2
变分自编码器
ML估计,即是估计向量h 和噪声方差 σ w 2 \sigma_{w}^{2} σw2,使得 log p θ ( y ) \log p_{\boldsymbol{\theta}}(\mathbf{y}) logpθ(y)最大,令 θ ≜ { h , σ w 2 } \boldsymbol{\theta} \triangleq\left\{\mathbf{h}, \sigma_{w}^{2}\right\} θ≜{h,σw2}。使用变分法可以简化这一信道估计问题:使用变分法求泛函数 log p θ ( y ) \log p_{\boldsymbol{\theta}}(\mathbf{y}) logpθ(y)的极小值,将问题转化为 最大化 log p θ ( y ) \log p_{\boldsymbol{\theta}}(\mathbf{y}) logpθ(y)的lower bound!使用神经网络解决此最大最小化问题。
补充:变分法
- 变分法用于求解使泛函数取得极大值或极小值的极值函数 。
- 泛函数:输入是一个函数,输出是一个值。
- 通常在变分法中,泛函数是一个积分
eg. I ( y ) = ∫ x 1 x 2 F d x I(y)=\int_{x_{1}}^{x_{2}} F d x I(y)=∫x1x2Fdx,F可以是y(x)和y(x)各阶导数的函数。
- 在这里 p θ ( y ) = ∫ x p ( x ) p θ ( y ∣ x ) d x p_{\boldsymbol{\theta}}(\mathbf{y})=\int_{\mathbf{x}} p(\mathbf{x}) p_{\boldsymbol{\theta}}(\mathbf{y} | \mathbf{x}) d \mathbf{x} pθ(y)=∫xp(x)pθ(y∣x)dx ,y是x的函数。
log p θ ( y ) ≥ E q Φ ( x ∣ y ) [ − log q Φ ( x ∣ y ) + log p θ ( x , y ) ] = − D K L [ q Φ ( x ∣ y ) ∥ p ( x ) ] ⎵ A + E q Φ ( x ∣ y ) [ log p θ ( y ∣ x ) ] ⎵ B ≜ − L ( θ , Φ , y ) \begin{aligned} \log p_{\boldsymbol{\theta}}(\mathbf{y}) \geq & \mathbb{E}_{q_{\Phi}(\mathbf{x} | \mathbf{y})}\left[-\log q_{\Phi}(\mathbf{x} | \mathbf{y})+\log p_{\boldsymbol{\theta}}(\mathbf{x}, \mathbf{y})\right] \\=& \underbrace{-D_{K L}\left[q_{\Phi}(\mathbf{x} | \mathbf{y}) \| p(\mathbf{x})\right]}_{A} \\ &+\underbrace{\mathbb{E}_{q_{\Phi}(\mathbf{x} | \mathbf{y})}\left[\log p_{\boldsymbol{\theta}}(\mathbf{y} | \mathbf{x})\right]}_{B} \triangleq-\mathcal{L}(\boldsymbol{\theta}, \mathbf{\Phi}, \mathbf{y}) \end{aligned} logpθ(y)≥=EqΦ(x∣y)[−logqΦ(x∣y)+logpθ(x,y)]A −DKL[qΦ(x∣y)∥p(x)]+B EqΦ(x∣y)[logpθ(y∣x)]≜−L(θ,Φ,y)
引入了自由参数Φ,问题转化为找到θ和Φ,使得 L ( θ , Φ , y ) \mathcal{L}(\boldsymbol{\theta}, \mathbf{\Phi}, \mathbf{y}) L(θ,Φ,y)最小。那么如何得到 L ( θ , Φ , y ) \mathcal{L}(\boldsymbol{\theta}, \mathbf{\Phi}, \mathbf{y}) L(θ,Φ,y)呢?
分析上式,可知上式与 p θ ( y ∣ x ) p_{\boldsymbol{\theta}}(\mathbf{y} | \mathbf{x}) pθ(y∣x), q Φ ( x ∣ y ) q_{\Phi}(\mathrm{x} | \mathrm{y}) qΦ(x∣y), p ( x ) p(\mathbf{x}) p(x)有关,其中: p θ ( y ∣ x ) = p θ ( y I ∣ x I ) p θ ( y Q ∣ x Q ) = 1 ( π σ w 2 ) N ⋅ e − ∥ y − x ∗ h ∥ 2 / σ w 2 \begin{aligned} p_{\boldsymbol{\theta}}(\mathbf{y} | \mathbf{x}) &=p_{\boldsymbol{\theta}}\left(\mathbf{y}^{I} | \mathbf{x}^{I}\right) p_{\boldsymbol{\theta}}\left(\mathbf{y}^{Q} | \mathbf{x}^{Q}\right) \\ &=\frac{1}{\left(\pi \sigma_{w}^{2}\right)^{N}} \cdot e^{-\|\mathbf{y}-\mathbf{x} * \mathbf{h}\|^{2} / \sigma_{w}^{2}} \end{aligned} pθ(y∣x)=pθ(yI∣xI)pθ(yQ∣xQ)=(πσw2)N1⋅e−∥y−x∗h∥2/σw2
p ( x ) = p ( x I ) p ( x Q ) = 2 − 2 N p(\mathbf{x})=p\left(\mathbf{x}^{I}\right) p\left(\mathbf{x}^{Q}\right)=2^{-2 N} p(x)=p(xI)p(xQ)=2−2N
只需得到 q Φ ( x ∣ y ) q_{\Phi}(\mathrm{x} | \mathrm{y}) qΦ(x∣y)即可得到 L ( θ , Φ , y ) \mathcal{L}(\boldsymbol{\theta}, \mathbf{\Phi}, \mathbf{y}) L(θ,Φ,y),此时可用解析的方法找到θ和Φ。
引入神经网络

用神经网络来求 q Φ ( x ∣ y ) q_{\Phi}(\mathrm{x} | \mathrm{y}) qΦ(x∣y): q Φ ( x ∣ y ) = ∏ j = 0 N − 1 q Φ ( x j ∣ y ) = ∏ j = 0 N − 1 q Φ ( x j I ∣ y ) q Φ ( x j Q ∣ y ) q_{\Phi}(\mathrm{x} | \mathrm{y})=\prod_{j=0}^{N-1} q_{\Phi}\left(x_{j} | \mathrm{y}\right)=\prod_{j=0}^{N-1} q_{\Phi}\left(x_{j}^{I} | \mathrm{y}\right) q_{\Phi}\left(x_{j}^{Q} | \mathrm{y}\right) qΦ(x∣y)=j=0∏N−1qΦ(xj∣y)=j=0∏N−1qΦ(xjI∣y)qΦ(xjQ∣y)
神经网络的输出为 q Φ ( x j I ∣ y ) 和 q Φ ( x j Q ∣ y ) q_{\Phi}\left(x_{j}^{I} | \mathbf{y}\right) 和q_{\Phi}\left(x_{j}^{Q} | \mathbf{y}\right) qΦ(xjI∣y)和qΦ(xjQ∣y),输出维度为2N.
至此,我们得到了 L ( θ , Φ , y ) \mathcal{L}(\boldsymbol{\theta}, \mathbf{\Phi}, \mathbf{y}) L(θ,Φ,y)的显示表达。
仿真结果







这篇关于深度通信网络专栏(4)|自编码器:Blind Channel Equalization using Variational Autoencoders的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






