autoencoders专题

论文《Autoencoders for improving quality of process event logs》翻译
论文《Autoencoders for improving quality of process event logs》翻译 《Autoencoders for improving quality of process event logs》翻译
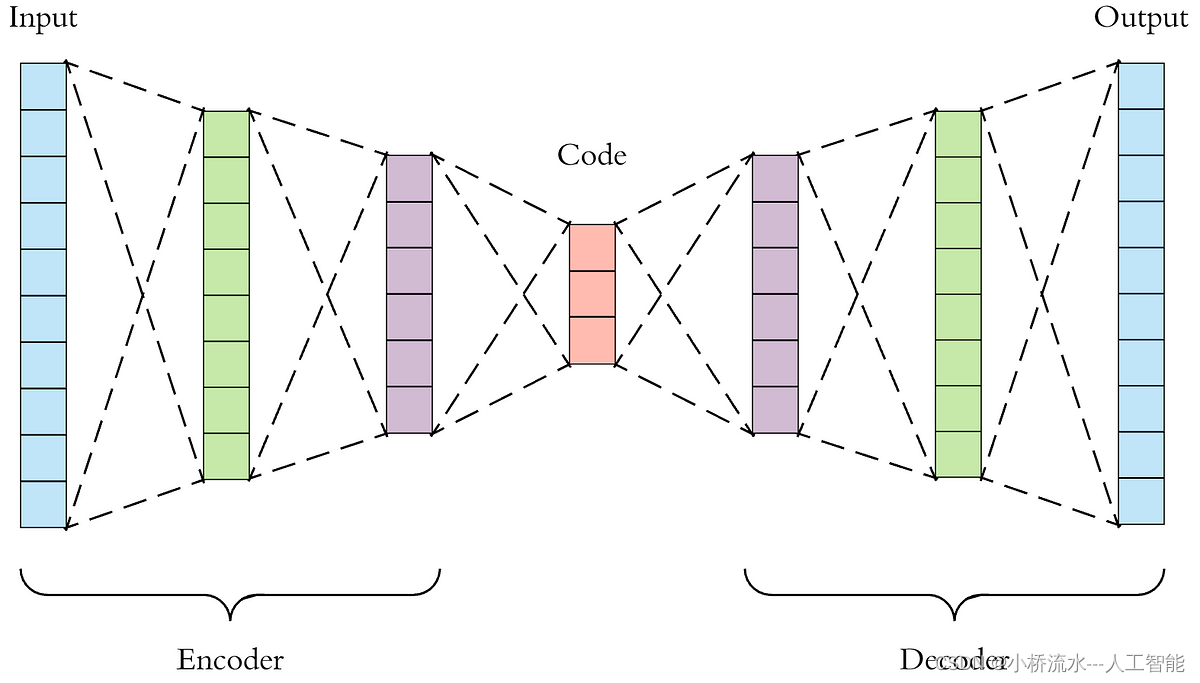
为什么堆叠自编码器(Stacked Autoencoders, SAE)解释性很强!?
堆叠自编码器(Stacked Autoencoders, SAE)相对于卷积神经网络(CNN)在某些情况下具有更高的解释性,主要原因在于其结构和特性使其在特征提取和表示上具有一定的透明度和可解释性。以下是具体原因: 特征表示的透明性: 低维特征表示:自编码器通过压缩输入数据,将高维数据映射到低维特征空间。这些低维特征表示保留了输入数据的主要信息,并且这种映射是显式的,易于分析和理解。逐层特
![[论文精读]Masked Autoencoders are scalable Vision Learners](https://img-blog.csdnimg.cn/direct/339a52553e2447ffa8b06a7d8d7d0fef.png)
[论文精读]Masked Autoencoders are scalable Vision Learners
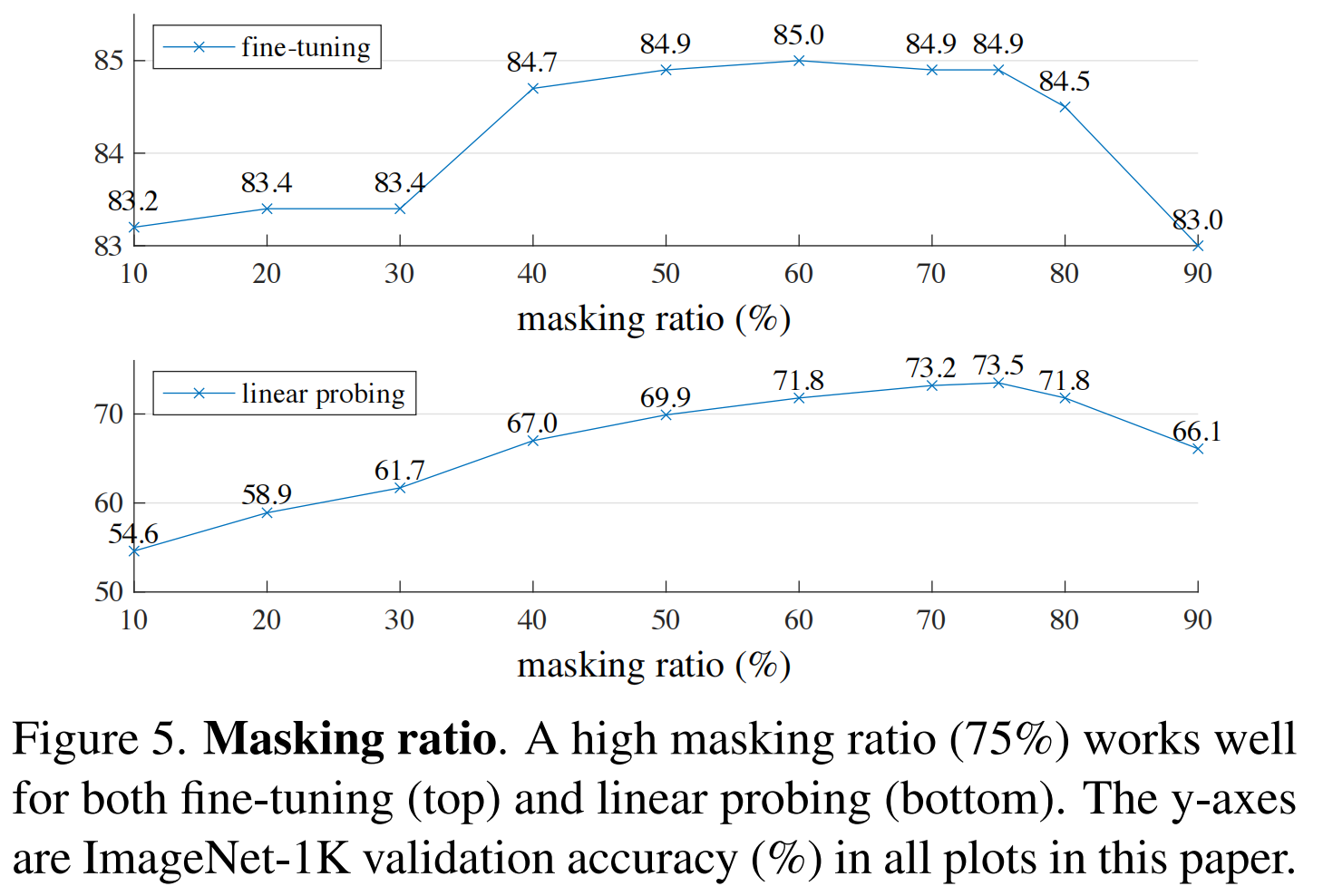
摘要本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的 MAE方法很简单:我们盖住输入图像的随机块并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对块的可见子集(没有掩码标记)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码标记重建原始图像。其次,我们发现如果用比较高的掩盖比例掩盖输入图像,例如75%,这会产生

【论文精读】MAE:Masked Autoencoders Are Scalable Vision Learners 带掩码的自动编码器是可扩展的视觉学习器
系列文章目录 【论文精读】Transformer:Attention Is All You Need 【论文精读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 【论文精读】VIT:vision transformer论文 文章目录 系列文章目录一、前言二、文章概览(一)研究背

MAE——「Masked Autoencoders Are Scalable Vision Learners」
这次,何凯明证明让BERT式预训练在CV上也能训的很好。 论文「Masked Autoencoders Are Scalable Vision Learners」证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。 这项工作的意义何在? 讨论区 Reference MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili //

PyTorch随笔 - MAE(Masked Autoencoders)推理脚本
MAE推理脚本: 需要安装:pip install timm==0.4.5需要下载:mae_visualize_vit_base.pth,447M 源码: #!/usr/bin/env python# -- coding: utf-8 --"""Copyright (c) 2022. All rights reserved.Created by C. L. Wang on 202

深度通信网络专栏(4)|自编码器:Blind Channel Equalization using Variational Autoencoders
本文地址:https://arxiv.org/abs/1803.01526 文章目录 前言文章主要贡献系统模型变分自编码器引入神经网络 仿真结果 前言 深度通信网络专栏|自编码器:整理2018-2019年使用神经网络实现通信系统自编码器的论文,一点拙见,如有偏颇,望不吝赐教,顺颂时祺。 文章主要贡献 原来提出的最大似然估计下的盲信道均衡使用期望最大或近似期望最大,计算复杂度
【ICCV 2022】(MAE)Masked Autoencoders Are Scalable Vision Learners
何凯明一作文章:https://arxiv.org/abs/2111.06377 感觉本文是一种新型的自监督学习方式 ,从而增强表征能力 本文的出发点:是BERT的掩码自编码机制:移除一部分数据并对移除的内容进行学习。mask自编码源于CV但盛于NLP,恺明对此提出了疑问:是什么导致了掩码自编码在视觉与语言之间的差异?尝试从不同角度进行解释并由此引申出了本文的MAE。 恺明提出一种用于计
论文阅读: Masked Autoencoders Are Scalable Vision Learners掩膜自编码器是可扩展的视觉学习器
Masked Autoencoders Are Scalable Vision Learners 掩膜自编码器是可扩展的视觉学习器 作者:FaceBook大神何恺明 一作 摘要: This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision.
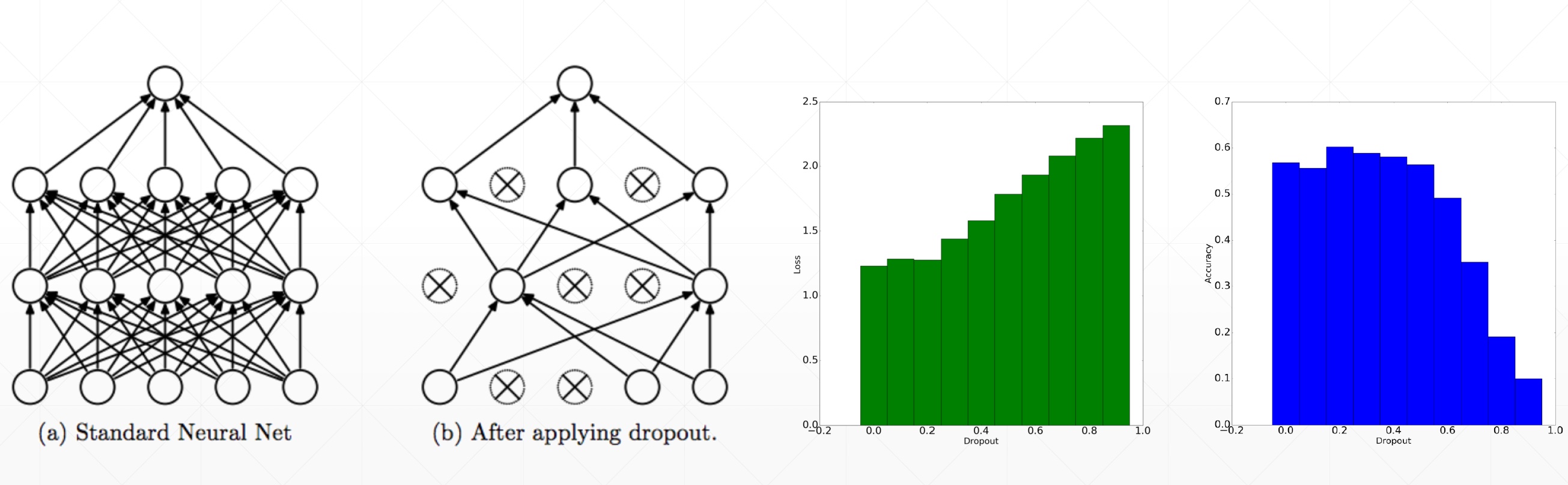
AutoEncoders变种
目录 PCA V.S. Auto-EncodersDenoising AutoEncodersDropout AutoEncoders PCA V.S. Auto-Encoders deep autoencoder由深度神经网络构成,因此降维效果丢失数据少 左pca;右auto-encoder Denoising AutoEncoders Dropout AutoEncoders
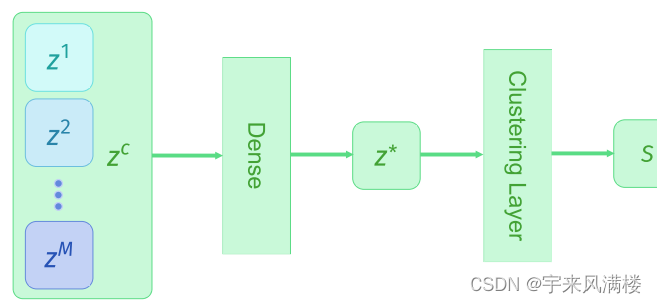

【论文阅读笔记】Traj-MAE: Masked Autoencoders for Trajectory Prediction
Abstract 通过预测可能的危险,轨迹预测一直是构建可靠的自动驾驶系统的关键任务。一个关键问题是在不发生碰撞的情况下生成一致的轨迹预测。为了克服这一挑战,我们提出了一种有效的用于轨迹预测的掩蔽自编码器(Traj-MAE),它能更好地代表驾驶环境中智能体的复杂行为。 具体来说,我们的Traj-MAE采用了多种掩蔽策略来预训练轨迹编码器和地图编码器,允许捕获智能体之间的社会和时间信息,同时利