tokenizer专题

解决Can‘t load tokenizer for ‘bert-base-chinese‘.问题
报错提示: OSError: Can't load tokenizer for 'bert-base-chinese'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwi
BPE_tokenizer代码实现
import refrom collections import Counter# 导入 Counter 的示例(如果需要的话)class BytePairEncoder:def __init__(self):self.ws_token = "_"self.unk_token = "<UNK>"self.corpus = {}self.word_count = {}self.vocab = C
Spark MLlib 特征工程系列—特征转换Tokenizer和移除停用词
Spark MLlib 特征工程系列—特征转换Tokenizer和移除停用词 Tokenizer和RegexTokenizer 在Spark中,Tokenizer 和 RegexTokenizer 都是用于文本处理的工具,主要用于将字符串分割成单词(tokens),但它们的工作方式和使用场景有所不同。 1. Tokenizer 功能: Tokenizer 是最简单的分词器,它基于空格(wh
tokenizer(词元化方法),嵌入向量
1. 词元化方法 BPE (Byte-Pair Encoding) BPE 是一种常用的词元化方法,主要用于处理文本中的词汇表。 工作原理:BPE 是一种数据压缩算法,通过反复合并文本中最频繁出现的字符对,生成新的子词单元。例如,在英语中,可能会将 “l” 和 “o” 合并为 “lo”,然后再将 “lo” 和 “ve” 合并为 “love”。优点:BPE 生成的子词单元可以有效减少词汇表大小,

Can‘t load tokenizer for ‘bert-base-uncased‘
先下载https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-768_A-12.zip 我上传了一个:https://download.csdn.net/download/LEE18254290736/89652982?spm=1001.2014.3001.5501 下载完了解压缩。 之后在项目工程新建一
transformers Tokenizer
☆ 问题描述 Tokenizer的学习笔记(Tokenizer is all you need) Tokenizer用于数据预处理 - 分词 - 构建词典 - 数据转换 - 数据填充与截断 现在Tokenizer可以做到上面的所有事情。 ★ 解决方案 Tokenizer的基本使用 # 导入Tokenizerfrom transformers import AutoTokenizer#
boost::tokenizer详解
tokenizer 库提供预定义好的四个分词对象, 其中char_delimiters_separator已弃用. 其他如下: 1. char_separator char_separator有两个构造函数 1. char_separator() 使用函数 std::isspace() 来识别被弃分隔符,同时使用 std::ispunct() 来识别保留分隔符。另外,抛弃空白单词。(见例2)
将stanfordcorenlp的tokenizer换成自定义的(或用stanfordcorenlp对自定义tokenizer分词后的结果做ner)
本文是基于中文语料做的,对于英文语料应该也是同理,即同样适用的。 分析stanfordcorenlp的分词结果,可以发现,它好像是对最小的中文词进行分词,即其对中文的分词粒度很小,这对于某些nlp场景可能就不太合适了,自然的就想到能不能将stanfordcorenlp中用于分词的tokenizer替换掉,替换成自定义的,这样就可以控制中文分词结果是你想要的了。 基于以上动机,我查找了相关资料,
ValueError: Couldn‘t instantiate the backend tokenizer from one of: (1)·
ValueError: Couldn’t instantiate the backend tokenizer from one of: (1) a `t···· 解决方案 !pip install transformers[sentencepiece]

小白学大模型:Hugging Face Tokenizer
Tokenizer介绍 在自然语言处理(NLP)领域,Tokenizer(分词器)是准备输入模型的关键步骤之一。Hugging Face 提供了用于各种模型的分词器库,其中大多数分词器都以两种风格提供:一种是完整的 Python 实现,另一种是基于 Rust 库 🤗 Tokenizers 的“Fast”实现。这两种实现方式各有特点,其中“Fast”实现具有两大优势: 显著提升速度: 特别是在
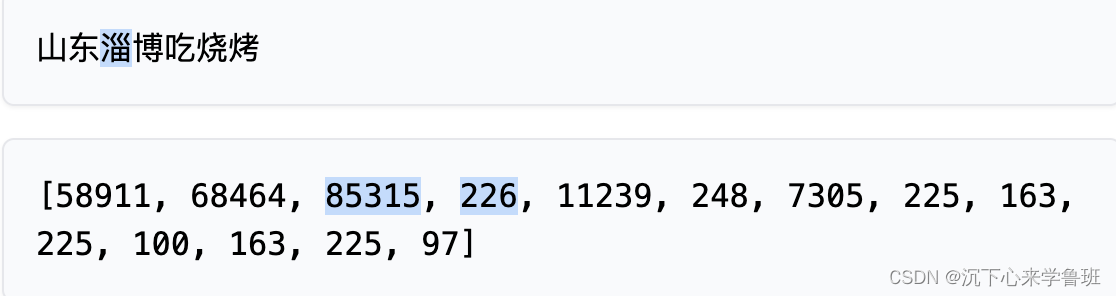
语言模型解构——Tokenizer
1. 认识Tokenizer 1.1 为什么要有tokenizer? 计算机是无法理解人类语言的,它只会进行0和1的二进制计算。但是呢,大语言模型就是通过二进制计算,让你感觉计算机理解了人类语言。 举个例子:单=1,双=2,计算机面临“单”和“双”的时候,它所理解的就是2倍关系。再举一个例子:赞美=1,诋毁=0, 当计算机遇到0.5的时候,它知道这是“毁誉参半”。再再举一个例子:女王={1,
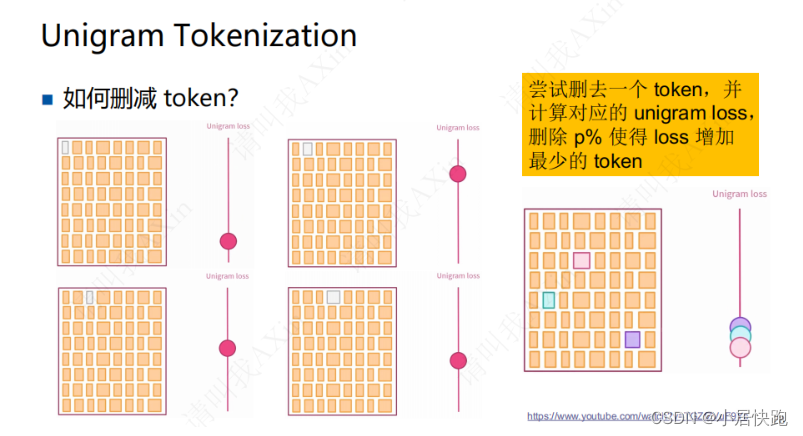
辅导男朋友转算法岗第1天|tokenizer
文章目录 LLM训练流程LLM中的tokenizersBPEWordPieceUnigramSentencePiece(使用BBPE或Unigram) LLM训练流程 【大语言模型LLM基础之Tokenizer完全介绍-哔哩哔哩】 https://b23.tv/2kdTKxf LLM中的tokenizers 三种不同分词粒度的Tokenizers word-based

CLIP 源码分析:simple_tokenizer.py
tokenizer的含义 from .clip import *引入头文件时为什么有个. 正文 import gzipimport htmlimport osfrom functools import lru_cacheimport ftfyimport regex as re# 上面的都是头文件 # 这段代码定义了一个函数 default_bpe(),它使用了装饰器 @

AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概览 AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化 AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理 AI大模型探索之路-训练篇7:大语言模型
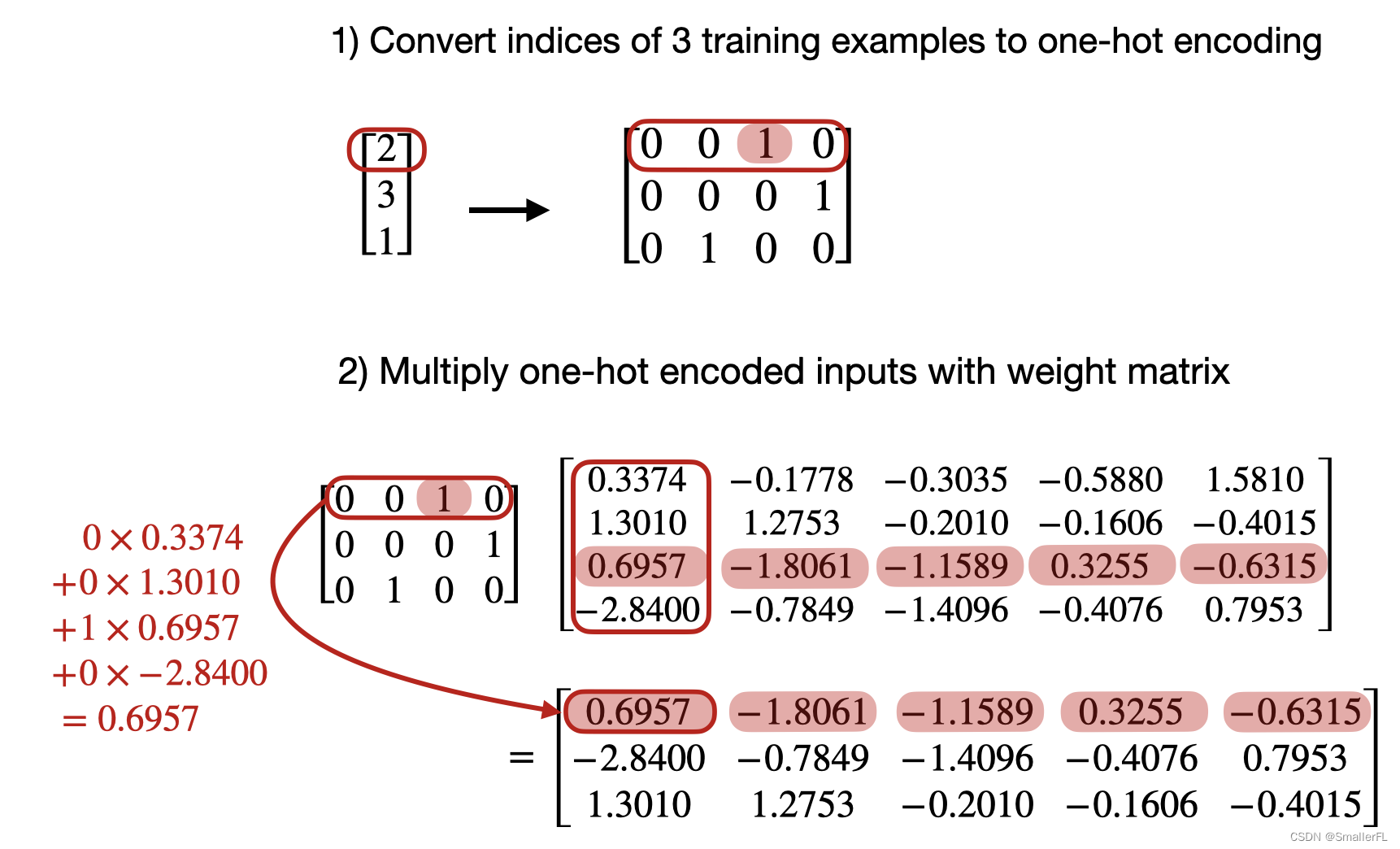
LLM 为什么需要 tokenizer?
文章目录 1. LLM 预训练目的1.1 什么是语言模型 2. Tokenizer一般处理流程(了解)3. 进行 Tokenizer 的原因3.1 one-hot 的问题3.2 词嵌入 1. LLM 预训练目的 我们必须知道一个预训练目的:LLM 的预训练是为了建立语言模型。 1.1 什么是语言模型 预训练的语言模型通常是建立预测模型的,即预测下一个词的概率。 通常采

常见分词器tokenizer汇总
常见分词器tokenizer 大模型中的分词器:BPE、WordPiece、Unigram LM、SentencePiece Byte Pair Encoding (BPE) OpenAI 从GPT2开始分词就是使用的这种方式,BPE每一步都将最常见的一对相邻数据单位替换为该数据中没有出现过的一个新单位,反复迭代直到满足停止条件。 字节对编码(Byte Pair Encoding, BPE
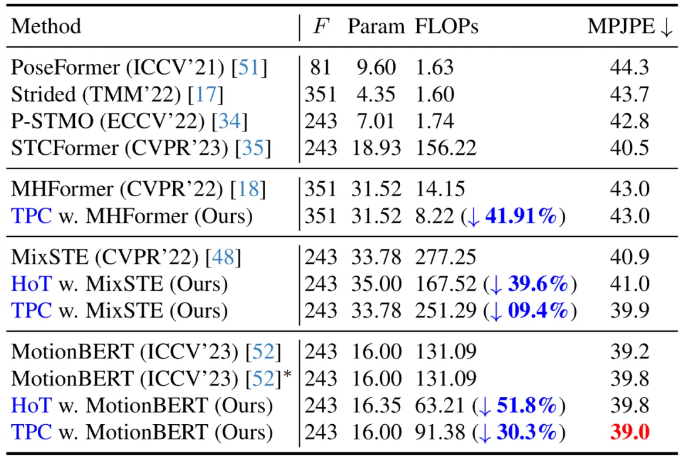
基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract文献阅读:基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT1、研究背景2、提出方法3、模块详细3.1、什么是HoT3.2、HoT 框架3.3、Token 剪枝聚类模块3.4、Token 恢复注意力模块3.5、模块应用 4、实验4.1、消融实验4.2、与SOTA对比 5、总结

OSError: Can‘t load tokenizer for ‘bert-base-chinese‘
文章目录 OSError: Can't load tokenizer for 'bert-base-chinese'1.问题描述2.解决办法 OSError: Can’t load tokenizer for ‘bert-base-chinese’ 1.问题描述 使用from_pretrained()函数从预训练的权重中加载模型时报错: OSError: Can’t loa
LLM大语言模型(八):ChatGLM3-6B使用的tokenizer模型BAAI/bge-large-zh-v1.5
背景 BGE embedding系列模型是由智源研究院研发的中文版文本表示模型。 可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。 BAAI/BGE embedding系列模型 模型列表 ModelLanguageDescriptionquery instruction for retrieval [1]BAAI/bge-m3Mu

transformers的tokenizer总结
1.BPE(byte-pair encoding) 根据字母搭配出现的频率组成词根。 初始vocabulary:["b", "g", "h", "n", "p", "s", "u"] 假设训练数据中有10个hug,5个pug,12个pun,4个bun和5个hugs: ("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)

AttributeError: ‘ChatGLMTokenizer‘ object has no attribute ‘sp_tokenizer‘
目录 问题描述 在使用ChatGLM+lora微调的时候,报错“AttributeError: 'ChatGLMTokenizer' object has no attribute 'sp_tokenizer'“ 编辑问题解决: 问题描述 在使用ChatGLM+lora微调的时候,报错“AttributeError: 'ChatGLMTokenizer' object ha

【搜索引擎分析策略(Analyzer = Tokenizer + Filter)】种瓜得豆?
你晓得伐?Solr的文本分析链 <analyzer type="index或者query"><tokenizer class="solr.StandardTokenizerFactory"/> 只会有一个分词器!<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> 可以有多个过滤器!
大模型Tokenizer知识
Byte-Pair Encoding(BPE) 如何构建词典? Byte-Pair Encoding(BPE)是一种常用的无监督分词方法,用于将文本分解为子词或字符级别的单位。BPE的词典构建过程如下: 初始化词典:将每个字符视为一个初始的词。例如,对于输入文本"hello world",初始词典可以包含{'h', 'e', 'l', 'o', 'w', 'r', 'd'}。 统计词频:对
关于LLaMA Tokenizer的一些坑...
使用LLaMA Tokenizer对 jsonl 文件进行分词,并将分词结果保存到 txt 文件中,分词代码如下: import jsonlinesimport sentencepiece as spmfrom tqdm import tqdmjsonl_file = '/path/to/jsonl_file'txt_file = '/path/to/txt_file'tokenizer
引入BertTokenizer出现OSError: Can‘t load tokenizer for ‘bert-base-uncased‘.
今天在跑一个模型的时候出现该报错,完整报错为: OSError: Can't load tokenizer for 'bert-base-uncased'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the
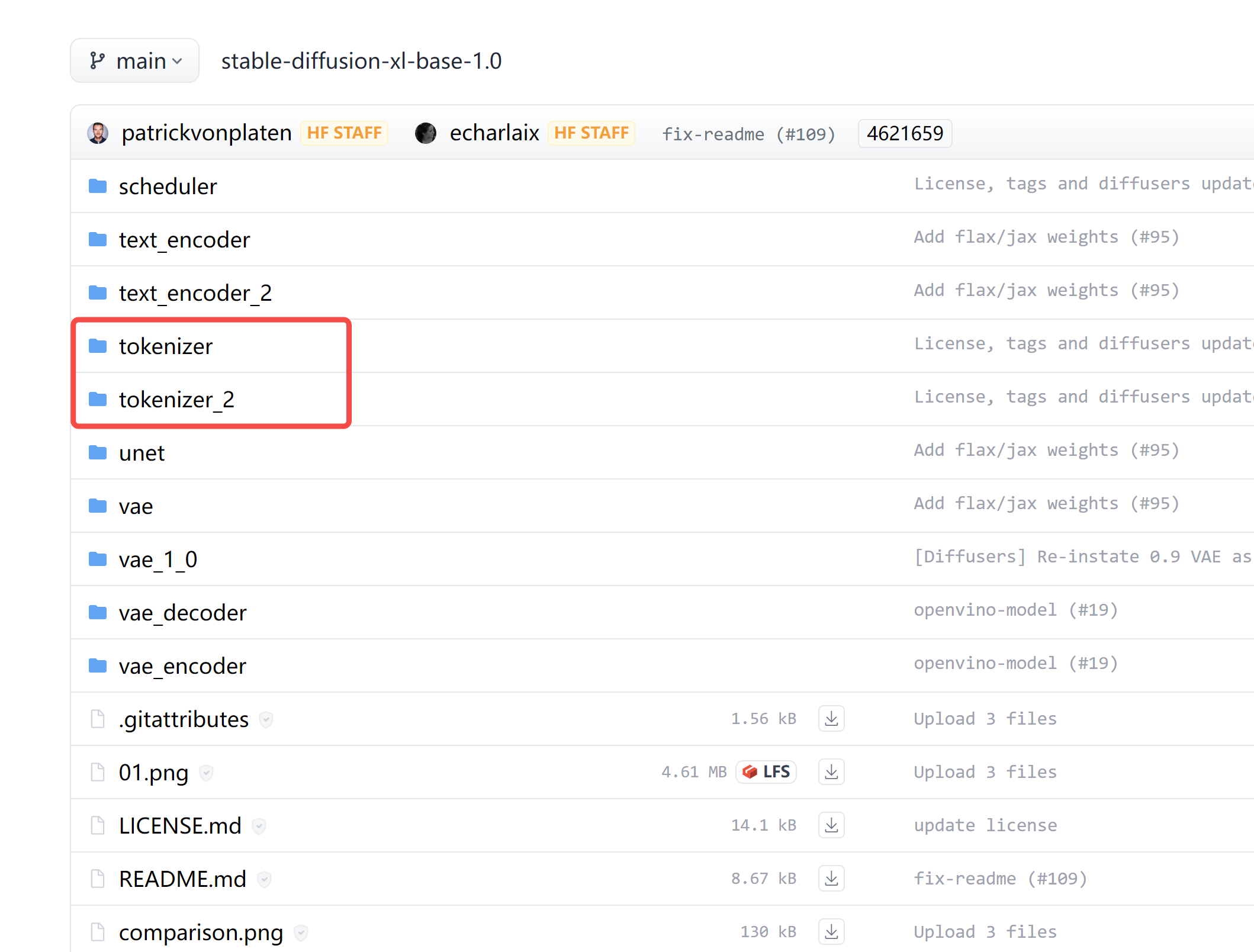
【深度学习】sdxl中的 tokenizer tokenizer_2 区别
代码仓库: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main 截图: 为什么有两个分词器 tokenizer 和 tokenizer_2? 在仔细阅读这些代码后,我们了解到 tokenizer_2 主要是用于 refiner 模型的。 # Load text tokenizer(s)i