本文主要是介绍基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT
- 1、研究背景
- 2、提出方法
- 3、模块详细
- 3.1、什么是HoT
- 3.2、HoT 框架
- 3.3、Token 剪枝聚类模块
- 3.4、Token 恢复注意力模块
- 3.5、模块应用
- 4、实验
- 4.1、消融实验
- 4.2、与SOTA对比
- 5、总结
- 简单Transformer的实现
- 总结
摘要
本周主要阅读了CVPR文章,Hourglass Tokenizer for Effcient Transformer-Based 3D Human Pose Estimation。这是一种即插即用的 Token 剪枝和恢复框架,用于从视频中高效地进行基于 Transformer 的 3D 人体姿势估计。大量实验验证了本方法的高度兼容性和广泛适用性。它可以轻松集成至各种常见的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,并且能够有效地适应多种 Token 剪枝与恢复策略,展示出其巨大潜力。除此之外,还学习学习了简单的Transformer代码的学习。
Abstract
This week, I mainly read the CVPR article, Hourglass Tokenizer for Effcient Transformer-Based 3D Human Pose Estimation. This is a plug-and-play Token pruning and recovery framework for efficient Transformer-based 3D human pose estimation from video. A large number of experiments have verified the high compatibility and wide applicability of this method. It can be easily integrated into various common VPT models, whether based on seq2seq or seq2frame VPT, and can effectively adapt to multiple Token pruning and recovery strategies, demonstrating its great potential. In addition, I also learned how to write simple Transformer code.
文献阅读:基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT
Title: Hourglass Tokenizer for Effcient Transformer-Based 3D Human Pose Estimation
Author:Wenhao Li , Mengyuan Liu, Hong Liu,Pichao Wang,Jialun Cail Nicu Sebet
From:2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
在 VPT 模型中,通常每一帧视频都被处理成一个独立的 Pose Token,通过处理长达数百帧的视频序列(通常是 243 帧乃至 351 帧)来实现卓越的性能表现,并且在 Transformer 的所有层中维持全长的序列表示。然而,由于 VPT 中自注意力机制的计算复杂度与 Token 数量(即视频帧数)的平方成正比关系,当处理具有较高时序分辨率的视频输入时,这些模型不可避免地带来了巨大的计算开销,使得它们难以被广泛部署到计算资源有限的实际应用中。此外,这种对整个序列的处理方式没有有效考虑到视频序列内部帧之间的冗余性,尤其是在视觉变化不明显的连续帧中。这种信息的重复不仅增加了不必要的计算负担,而且在很大程度上并没有对模型性能的提升做出实质性的贡献。
2、提出方法
作者提出了一种基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT,用来解决现有视频姿态 Transformer(Video Pose Transformer,VPT)高计算需求的问题。基于对实现高效VPT要解决时间感受野要打、视频冗余得去除的问题,作者提出对深层 Transformer 的 Pose Token 进行剪枝,以减少视频帧的冗余性,同时提高 VPT 的整体效率。该框架可以即插即用无缝地集成到 MHFormer,MixSTE,MotionBERT 等模型中,降低模型近 40% 的计算量而不损失精度。
3、模块详细
3.1、什么是HoT
HoT是第一个基于 Transformer 的高效三维人体姿态估计的即插即用框架。如下图所示,传统的 VPT 采用了一个 “矩形” 的范式,即在模型的所有层中维持完整长度的 Pose Token,这带来了高昂的计算成本及特征冗余。与传统的 VPT 不同,HoT 先剪枝去除冗余的 Token,再恢复整个序列的 Token(看起来像一个 “沙漏”),使得 Transformer 的中间层中仅保留少量的 Token,从而有效地提升了模型的效率。HoT 还展现了极高的通用性,它不仅可以无缝集成到常规的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,同时也能够适配各种 Token 剪枝和恢复策略。
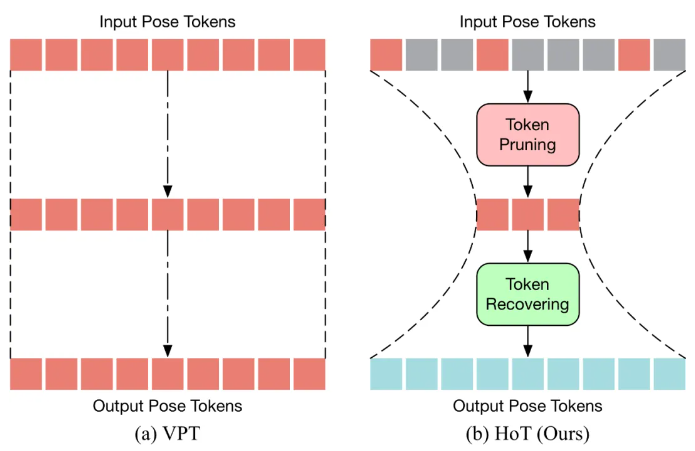
3.2、HoT 框架
提出的 HoT 整体框架如下图所示。为了更有效地执行 Token 的剪枝和恢复,本文提出了 Token 剪枝聚类(Token Pruning Cluster,TPC)和 Token 恢复注意力(Token Recovering Attention,TRA)两个模块。其中,TPC 模块动态地选择少量具有高语义多样性的代表性 Token,同时减轻视频帧的冗余。TRA 模块根据所选的 Token 来恢复详细的时空信息,从而将网络输出扩展到原始的全长时序分辨率,以进行快速推理。

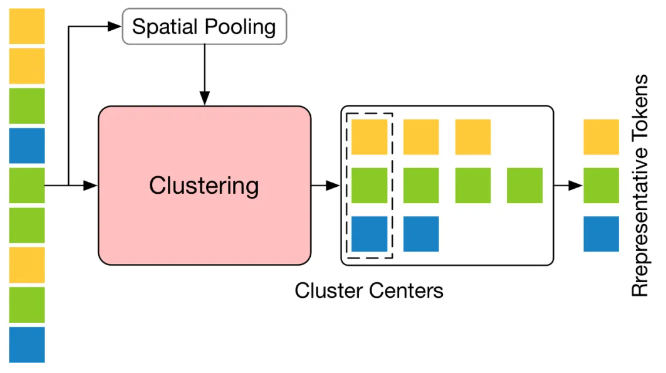
3.3、Token 剪枝聚类模块
Token 剪枝聚类(Token Pruning Cluster,TPC)模块的核心在于鉴别并去除掉那些在语义上贡献较小的 Token,并聚焦于那些能够为最终的三维人体姿态估计提供关键信息的 Token。通过采用聚类算法,TPC 动态地选择聚类中心作为代表性 Token,借此利用聚类中心的特性来保留原始数据的丰富语义。TPC 的结构如下图所示,它先对输入的 Pose Token 在空间维度上进行池化处理,随后利用池化后 Token 的特征相似性对输入 Token 进行聚类,并选取聚类中心作为代表性 Token。
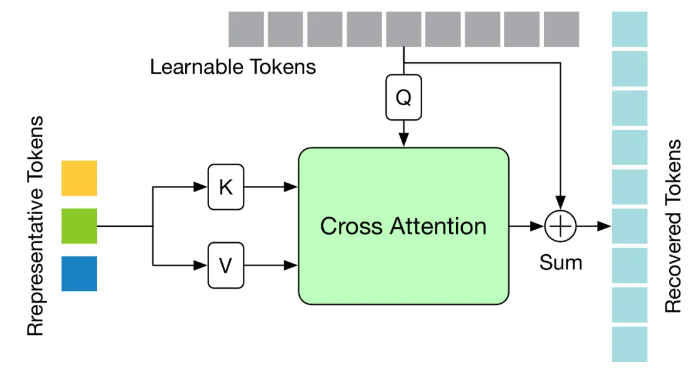
3.4、Token 恢复注意力模块
Token 恢复注意力(Token Recovering Attention,TRA)模块,它能够基于选定的 Token 恢复详细的时空信息。通过这种方式,由剪枝操作引起的低时间分辨率得到了有效扩展,达到了原始完整序列的时间分辨率,使得网络能够一次性估计出所有帧的三维人体姿态序列,从而实现 seq2seq 的快速推理。TRA 模块的结构如下图所示,其利用最后一层 Transformer 中的代表性 Token 和初始化为零的可学习 Token,通过一个简单的交叉注意力机制来恢复完整的 Token 序列。
3.5、模块应用
VPT 架构主要由三个组成部分构成:一个姿态嵌入模块用于编码姿态序列的空间与时间信息,多层 Transformer 用于学习全局时空表征,以及一个回归头模块用于回归输出三维人体姿态结果。根据输出的帧数不同,现有的 VPT 可分为两种推理流程:seq2frame 和 seq2seq。在 seq2seq 流程中,输出是输入视频的所有帧,因此需要恢复原始的全长时序分辨率。如 HoT 框架图所示的,TPC 和 TRA 两个模块都被嵌入到 VPT 中。在 seq2frame 流程中,输出是视频中心帧的三维姿态。因此,在该流程下,TRA 模块是不必要的,只需在 VPT 中集成 TPC 模块即可。其框架如下图所示。

4、实验
4.1、消融实验
在下表,论文给出了在 seq2seq(*)和 seq2frame(†)推理流程下的对比。结果表明,通过在现有 VPT 上应用所提出的方法,本方法能够在保持模型参数量几乎不变的同时,显著减少 FLOPs,并且大幅提高了 FPS。此外,相比原始模型,所提出的方法在性能上基本持平或者能取得更好的性能。
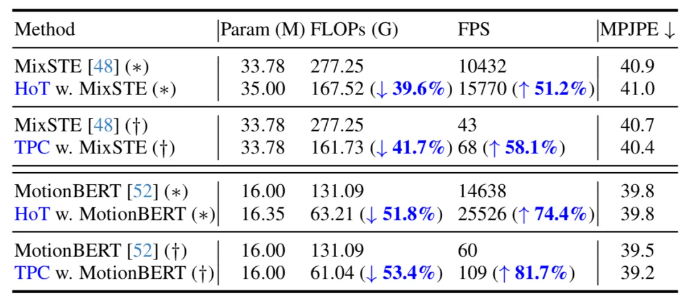
4.2、与SOTA对比
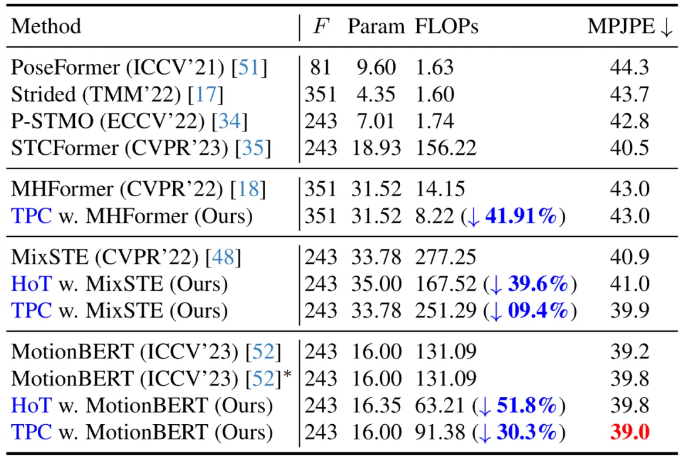
当前,在 Human3.6M 数据集上,三维人体姿态估计的领先方法均采用了基于 Transformer 的架构。为了验证本方法的有效性,作者将其应用于三个最新的 VPT 模型:MHForme,MixSTE 和 MotionBERT,并与它们在参数量、FLOPs 和 MPJPE 上进行了比较。如下表所示,本方法在保持原有精度的前提下,显著降低了 SOTA VPT 模型的计算量。这些结果不仅验证了本方法的有效性和高效率,还揭示了现有 VPT 模型中存在着计算冗余,并且这些冗余对最终的估计性能贡献甚小,甚至可能导致性能下降。此外,本方法可以剔除掉这些不必要的计算量,同时达到了高度竞争力甚至更优的性能。
5、总结
本文针对现有 Video Pose Transforme(VPT)计算成本高的问题,提出了沙漏 Tokenizer(Hourglass Tokenizer,HoT),这是一种即插即用的 Token 剪枝和恢复框架,用于从视频中高效地进行基于 Transformer 的 3D 人体姿势估计。研究发现,在 VPT 中维持全长姿态序列是不必要的,使用少量代表性帧的 Pose Token 即可同时实现高精度和高效率。大量实验验证了本方法的高度兼容性和广泛适用性。它可以轻松集成至各种常见的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,并且能够有效地适应多种 Token 剪枝与恢复策略,展示出其巨大潜力。作者期望 HoT 能够推动开发更强、更快的 VPT。
简单Transformer的实现
# 定义多头注意力机制模块
class MultiHeadAttention(nn.Module): def __init__(self, d_model, num_heads): super(MultiHeadAttention, self).__init__() # 调用父类(nn.Module)的构造函数 self.num_heads = num_heads # 设置多头注意力的头数 self.d_model = d_model # 输入特征的维度 # 确保d_model可以被num_heads整除 assert d_model % self.num_heads == 0 # 计算每个头的维度 self.depth = d_model // self.num_heads # 定义线性变换层,用于计算查询、键和值的表示 self.wq = nn.Linear(d_model, d_model) self.wk = nn.Linear(d_model, d_model) self.wv = nn.Linear(d_model, d_model) # 定义线性变换层,用于最后的输出变换 self.dense = nn.Linear(d_model, d_model) # 将输入张量分割成多个头 def split_heads(self, x, batch_size): # 重塑张量以准备分割 x = x.reshape(batch_size, -1, self.num_heads, self.depth) # 置换张量的维度,以便后续的矩阵乘法 return x.permute(0, 2, 1, 3) # 前向传播函数 def forward(self, v, k, q, mask): batch_size = q.shape[0] # 获取批次大小 # 通过线性变换层计算查询、键和值的表示 q = self.wq(q) # 查询(batch_size, seq_len, d_model) k = self.wk(k) # 键(batch_size, seq_len, d_model) v = self.wv(v) # 值(batch_size, seq_len, d_model) # 将查询、键和值分割成多个头 q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth) k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth) v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth) # 计算缩放点积注意力 scaled_attention, attention_weights = self.scaled_dot_product_attention(q, k, v, mask) # 将注意力输出的维度重新排列并合并回原始维度 scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous() new_context_layer_shape = scaled_attention.shape[:-2] + (self.d_model,) scaled_attention = scaled_attention.reshape(new_context_layer_shape) # 通过线性变换层得到最终的输出 output = self.dense(scaled_attention) return output, attention_weights # 计算缩放点积注意力 def scaled_dot_product_attention(self, q, k, v, mask): # 计算查询和键的点积 matmul_qk = torch.matmul(q, k.transpose(-2, -1)) # (batch_size, num_heads, seq_len_q, seq_len_k) dk = torch.tensor(self.depth, dtype=torch.float32).to(q.device) # 获取每个头的维度 # 缩放点积注意力分数 scaled_attention_logits = matmul_qk / dk # 如果提供了掩码,则将其应用于注意力分数 if mask is not None: scaled_attention_logits += (mask * -1e9) # 将掩码位置的值设置为一个非常小的负数 # 应用softmax函数得到注意力权重 attention_weights = F.softmax(scaled_attention_logits, dim=-1) # (batch_size, num_heads
总结
本周主要阅读了CVPR文章,Hourglass Tokenizer for Effcient Transformer-Based 3D Human Pose Estimation。这是一种即插即用的 Token 剪枝和恢复框架,用于从视频中高效地进行基于 Transformer 的 3D 人体姿势估计。大量实验验证了本方法的高度兼容性和广泛适用性。它可以轻松集成至各种常见的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,并且能够有效地适应多种 Token 剪枝与恢复策略,展示出其巨大潜力。除此之外,还学习学习了简单的Transformer代码的学习。
这篇关于基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






