本文主要是介绍CLIP 源码分析:simple_tokenizer.py,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
tokenizer的含义

from .clip import *引入头文件时为什么有个.

正文
import gzip
import html
import os
from functools import lru_cacheimport ftfy
import regex as re# 上面的都是头文件
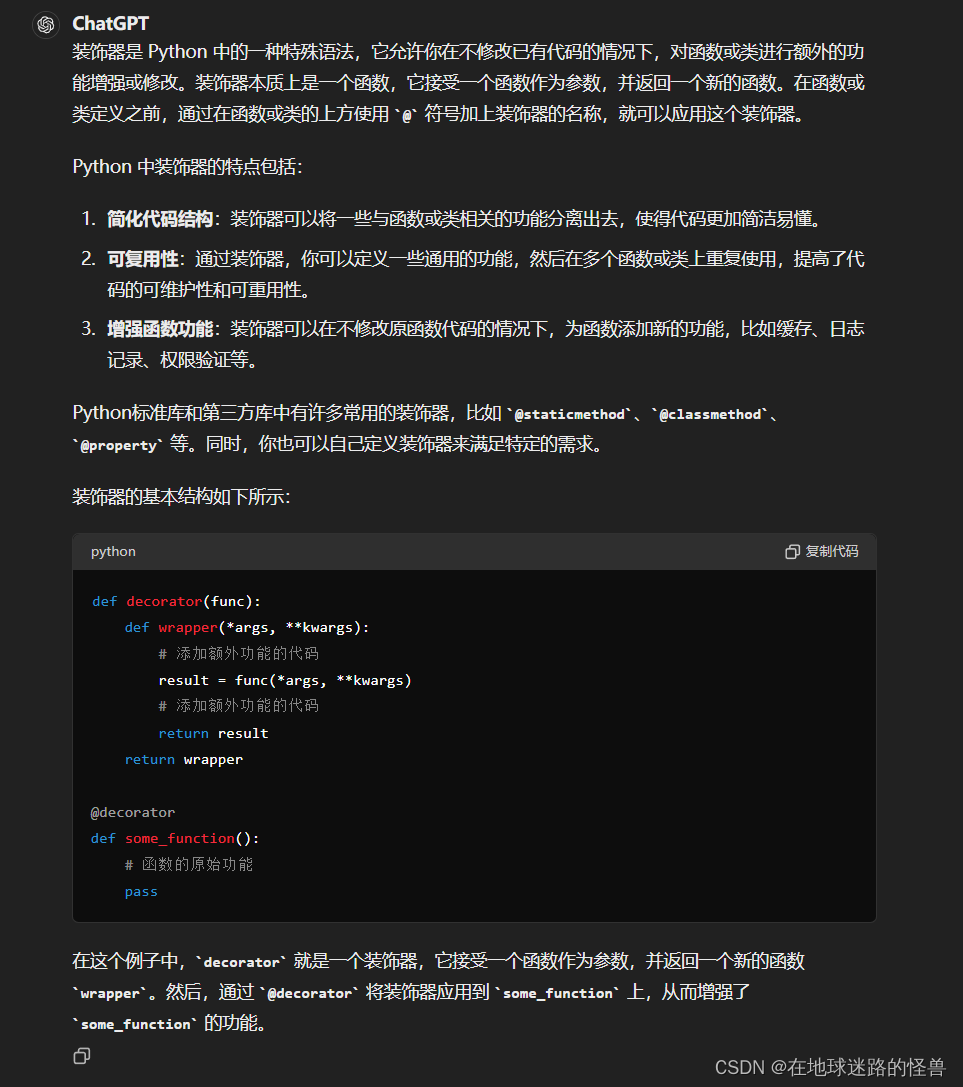
# 这段代码定义了一个函数 default_bpe(),它使用了装饰器 @lru_cache()。
# @lru_cache() 是 Python 中的一个装饰器,用于缓存函数的返回值,以避免重复计算。
# 这样,如果相同的参数再次传递给函数,它会直接返回之前缓存的结果,而不是重新执行函数。
@lru_cache()
# default_bpe() 函数的作用是返回一个文件路径,这个路径是一个位于当前文件所在目录下的文件路径。
# 具体来说,它构造了一个文件路径,指向一个名为 "bpe_simple_vocab_16e6.txt.gz" 的文件。
# 这个文件路径是相对于当前文件所在目录的,因为它使用了 os.path.dirname(__file__) 获取当前文件所在目录的路径,
# 然后通过 os.path.join() 构建了文件的完整路径。
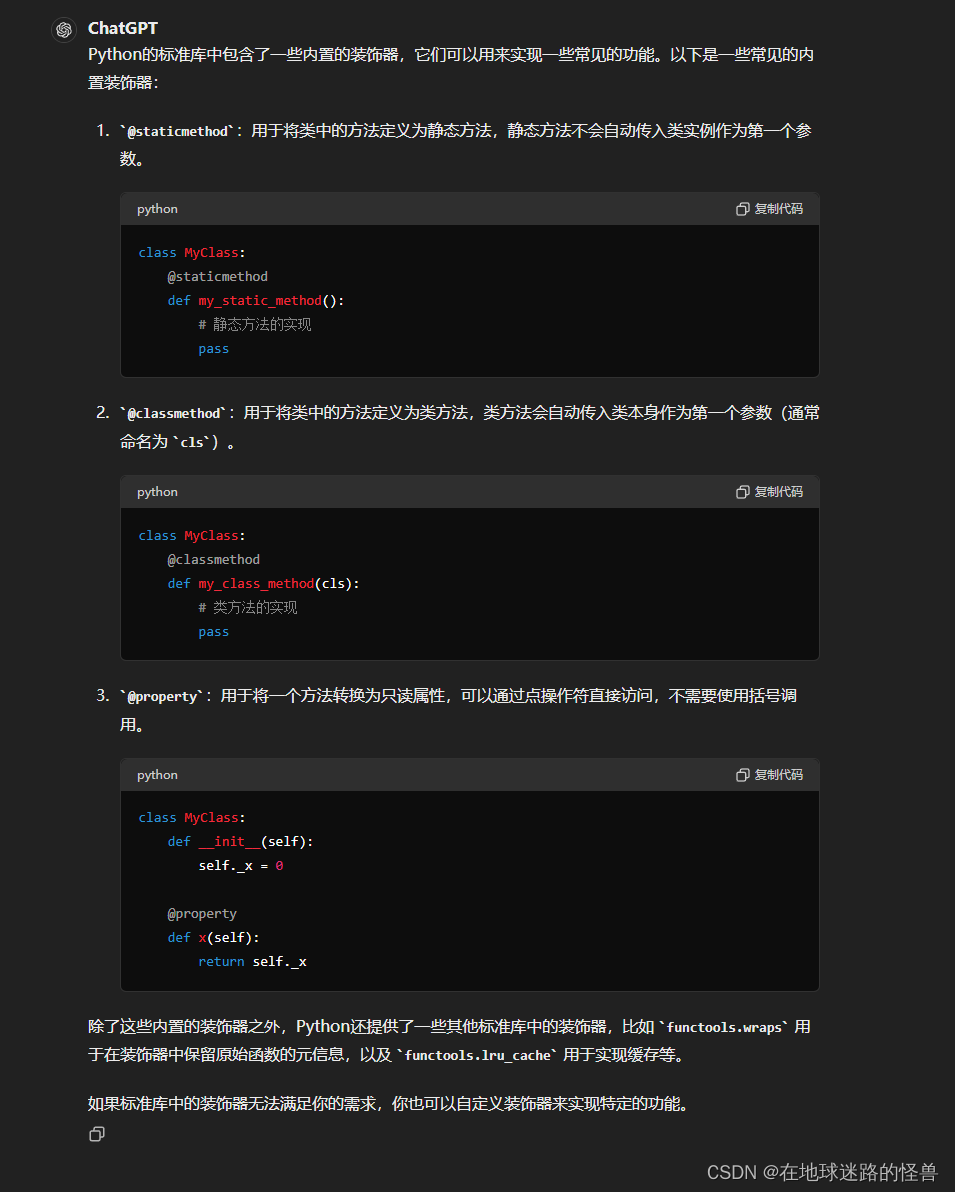
def default_bpe():return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")Python 中的装饰器概念
# 这段代码定义了一个函数 bytes_to_unicode(),同样使用了装饰器 @lru_cache() 来缓存函数的返回值
@lru_cache()
# 这个函数的作用是创建一个字典,将 UTF-8 字节映射到对应的 Unicode 字符串。
# 注释中提到,这个字典的目的是为了在 BPE(Byte Pair Encoding)编码中使用。
# BPE 编码需要在词汇表中有大量的 Unicode 字符,以避免未知字符(UNKs)的出现。
def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe codes work on unicode strings.This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.This is a signficant percentage of your normal, say, 32K bpe vocab.To avoid that, we want lookup tables between utf-8 bytes and unicode strings.And avoids mapping to whitespace/control characters the bpe code barfs on."""# 函数内部的操作是创建了两个列表 bs 和 cs,分别存储了一组 UTF-8 字节和对应的 Unicode 字符串。# 然后通过循环将所有可能的 8 位字节加入到这两个列表中,确保覆盖了所有可能的情况。# 最后,使用 zip() 函数将这两个列表合并成一个字典,键为 UTF-8 字节,值为对应的 Unicode 字符串。bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))cs = bs[:]n = 0for b in range(2**8):if b not in bs:bs.append(b)cs.append(2**8+n)n += 1cs = [chr(n) for n in cs]return dict(zip(bs, cs))
bs = list(range(ord(“!”), ord(“~”)+1))+list(range(ord(“¡”), ord(“¬”)+1))+list(range(ord(“®”), ord(“ÿ”)+1))

# 这个函数的作用是提取给定单词中所有相邻字符对的集合,用于后续的处理,比如在文本处理中进行基于字符的分词或编码
def get_pairs(word):"""Return set of symbol pairs in a word.Word is represented as tuple of symbols (symbols being variable-length strings)."""# 创建一个空集合 pairs,用于存储字符对。pairs = set()# 初始化变量 prev_char 为输入单词 word 的第一个字符。prev_char = word[0]# 使用 for 循环遍历输入单词 word 中的每个字符,从第二个字符开始(因为第一个字符已经在 prev_char 中)。for char in word[1:]:# 将相邻的字符对 (prev_char, char) 添加到集合 pairs 中。# 这个操作将当前字符 char 与前一个字符 prev_char 组成一个元组,然后将这个元组添加到集合中。pairs.add((prev_char, char))# 更新 prev_char 的值为当前字符 char,以便在下一次循环中使用。prev_char = char# 返回包含所有相邻字符对的集合 pairs。return pairs
# 这个函数用于对文本进行基本的清洗和修复
def basic_clean(text):# 这一行代码使用了第三方库 ftfy 中的 fix_text() 函数,用于修复文本中的各种编码问题和Unicode字符问题。# 这个函数会尝试修复诸如Unicode编码错误、Unicode编码为HTML实体等问题text = ftfy.fix_text(text)# 这一行代码用于解码 HTML 实体,将 HTML 实体转换回原始字符。# 通常,HTML 实体是用来表示特殊字符的编码形式,比如 < 表示 <,> 表示 >。# 由于可能存在多级嵌套的 HTML 实体,因此使用了两次 html.unescape() 函数来确保解码所有的实体。text = html.unescape(html.unescape(text))# 最后,这一行代码返回经过清洗和修复后的文本,# 并使用 strip() 方法去除文本两端的空白字符,确保文本的整洁性return text.strip()# 这个函数用于去除文本中的多余空白字符
def whitespace_clean(text):
# 这一行代码使用了 Python 内置的 re 模块,调用了 re.sub() 函数来进行正则表达式替换。
# 具体地,它使用了正则表达式 \s+ 来匹配一个或多个连续的空白字符(包括空格、制表符、换行符等),
# 然后将它们替换为单个空格 ' '。这样可以将连续的空白字符合并成一个空格,从而去除多余的空白。text = re.sub(r'\s+', ' ', text)# 这一行代码使用了字符串的 strip() 方法,去除了文本两端的空白字符,确保文本的整洁性text = text.strip()# 返回经过清洗后的文本return text
# 这段代码定义了一个名为 SimpleTokenizer 的类,它实现了一个简单的分词器,用于将文本分割成词语的序列
# 更具体的,这个类实现了一个基于字节对编码的简单分词器,用于将文本转换为词语序列,并提供了编码和解码的方法来处理文本数据
class SimpleTokenizer(object):
# 类的初始化方法。接受一个参数 bpe_path,默认值为 default_bpe() 函数的返回值(也就上面定义的函数),
# 这个函数用于获取默认的 BPE(字节对编码)路径。
# 在初始化过程中,加载了 BPE 模型文件(这个文件也在文件目录中捏),并设置了一些其他的属性和变量。def __init__(self, bpe_path: str = default_bpe()):self.byte_encoder = bytes_to_unicode()self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')merges = merges[1:49152-256-2+1]merges = [tuple(merge.split()) for merge in merges]vocab = list(bytes_to_unicode().values())vocab = vocab + [v+'</w>' for v in vocab]for merge in merges:vocab.append(''.join(merge))vocab.extend(['<|startoftext|>', '<|endoftext|>'])self.encoder = dict(zip(vocab, range(len(vocab))))self.decoder = {v: k for k, v in self.encoder.items()}self.bpe_ranks = dict(zip(merges, range(len(merges))))self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}self.pat = re.compile(r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)# 这个方法用于执行 BPE 编码。它接受一个字符串 token 作为输入,返回经过 BPE 编码后的字符串。def bpe(self, token):if token in self.cache:return self.cache[token]word = tuple(token[:-1]) + ( token[-1] + '</w>',)pairs = get_pairs(word)if not pairs:return token+'</w>'while True:bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))if bigram not in self.bpe_ranks:breakfirst, second = bigramnew_word = []i = 0while i < len(word):try:j = word.index(first, i)new_word.extend(word[i:j])i = jexcept:new_word.extend(word[i:])breakif word[i] == first and i < len(word)-1 and word[i+1] == second:new_word.append(first+second)i += 2else:new_word.append(word[i])i += 1new_word = tuple(new_word)word = new_wordif len(word) == 1:breakelse:pairs = get_pairs(word)word = ' '.join(word)self.cache[token] = wordreturn word# 这个方法用于对文本进行编码,将文本转换为 BPE 词汇的索引序列def encode(self, text):bpe_tokens = []text = whitespace_clean(basic_clean(text)).lower()for token in re.findall(self.pat, text):token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))return bpe_tokens# 这个方法用于对索引序列进行解码,将 BPE 编码后的索引序列转换回文本。def decode(self, tokens):text = ''.join([self.decoder[token] for token in tokens])text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('</w>', ' ')# 最后返回经过编解码处理的文本数据return text总结
不难发现,simple_tokenizer.py 这个文件模块就是用来处理我们输入的文本数据的,主要是一些编码上的处理、文本数据的清洗以及文本格式的转换。在最后我们会手动 debug 走一遍流程,看看该项目的各个部分到底是怎么做的都负责了什么。
这篇关于CLIP 源码分析:simple_tokenizer.py的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






