stata专题

STATA学习笔记之按照某个变量的类别分组排序
STATA按照某个变量的类别分组排序 比如要按照var2这个变量的类别进行分组和排序,如下图所示: 四种情况: 如果需要生成n,命令是: by var2, sort: gen n=_n 如果需要生成order2,命令是: by var2, sort: gen order2=_N 如果需要生成order,命令是: sort var2 gen order=_n 如果需要生成nnn,命令是:
《面板变系数模型及 Stata 具体操作步骤》
目录 一、文献综述 二、理论原理 三、实证模型 四、稳健性检验 五、程序代码及解释 六、代码运行结果 一、文献综述 在经济和社会科学研究领域,面板数据模型因其能够同时考虑个体和时间维度的信息而被广泛应用。传统的面板数据模型通常假设系数是固定的,但现实中,系数可能会随着个体或时间的变化而变化。面板变系数模型的出现为更准确地分析数据提供了新的方法。 近年来,众多学

stata空间计量模型基础+检验命令LM检验、sem、门槛+arcgis画图
目录 怎么安装stata命令 3怎么使用已有的数据 4数据编辑器中查看数据 4怎么删除不要的列 4直接将字符型变量转化为数值型的命令 4改变字符长度 4描述分析 4取对数 5相关性分析 5单位根检验 5权重矩阵标准化 6计算泰尔指数 6做核密度图 7Moran’s I 指数 8空间计量模型 9LM检验 10Hausman 检验 11LR 检验 11检验是否退化 13Wald 检验 14交互效应

如何解决stata数据管理器中变量变红的问题
目标:解决open变量变红的问题 网上说可以通过以下代码解决(实际上是缘木求鱼) encode encode 红色数字的变量名, gen(新产生的变量名) 自己尝试用这个代码之后,发现对应变量不是红色了,但变成了蓝色。我开始以为问题已经解决了,但是从实证回归的结果看,实证结果明显和既有的大部分研究不一致。而且实证结果随着控制变量的增减而变化很大,核心解释变量不仅数值变化较大,而且连

【资源分享】Stata 17免费下载安装
::: block-1 “时问桫椤”是一个致力于为本科生到研究生教育阶段提供帮助的不太正式的公众号。我们旨在在大家感到困惑、痛苦或面临困难时伸出援手。通过总结广大研究生的经验,帮助大家尽早适应研究生生活,尽快了解科研的本质。祝一切顺利!——时问桫椤 ::: 获取方法 公众号“时问桫椤”后台回复: Stata17 Stata 是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合

stata 数据匹配
横向匹配(增加变量)——merge merge 1:1 id using otherfile.dta 匹配城市 merge m:1 city using "E:\基点.dta",nogen 匹配上市公司 merge m:1 stkcd time using "E:\基点.dta",nogen 匹配类型: 1:1: 1配1 m:1:多配1 m:m:多配多 1:m: 1配多 纵
Stata 15 for Mac:数据统计分析新标杆,让研究更高效!
Stata 是一种统计分析软件,适用于数据管理、数据分析和绘图。Stata 15 for Mac 具有以下功能: 数据管理:Stata 提供强大的数据管理功能,用户可以轻松导入、清洗、整理和管理数据集。 统计分析:Stata 提供了广泛的统计分析功能,包括描述性统计、回归分析、生存分析、面板数据分析等。 图形化输出:用户可以通过 Stata 生成高质量的图形输出,包括散点图、柱状图、箱线图

用stata进行回归的参数解释
SS离均差平方和 :df自由度; MS均方差; F模型回归系数全为0的无效假设检验对应的F值: Prob>F为F检验相应的p值; Model为回归项:对应为回归平方和和回归均方差 Residual残差项,对应为残差平方和、残差自由度和残差均方和: R-squared为决定系数: Adj R-squared为调整自由度后的决定系数: Total为残差均方和的根号; Coef回归系数; Std.Err
Stata: 虚拟变量交乘项生成和检验的简便方法
作者:胡杰 (中山大学岭南学院本科生) (知乎 | 简书 | 码云) 连享会推文集锦Stata连享会 精品专题 || 精彩推文 连享会计量方法专题…… 2019金秋十月-空间计量专题班,杨海生主讲,成都 简介 虚拟变量(Dummy variables)和交乘项(Interaction) 在对有组别或者等级的数据进行处理时,常常需要利用虚拟变量和交乘项来探究各

Stata实证命令代码汇总
Stata代码命令汇总 数据内容:包括数据导入和管理、数据的处理、描述性统计、相关性分析、实证模型、内生性解决、检验分析、结果导出 具体如下: 一、数据导入和管理:数据导入、数据导出 二、数据的处理:生成新变量、格式转换、缺失数据、异常数据、重命名变量、编码分类变量、设定面板数据、数据合并、 数据追加 三、描述性统计:基本统计、变量的详细统计、变量的频率表、变量间的相关性、回归分析及其描
【计量】内生性相关(stata:工具变量,CEM,PSM,GPSM)(施工中)
内生性 原理 处理 1. 工具变量 原理: 问题:违反“解释变量与随机扰动项不相关”的假设工具变量的要求:与内生变量高度相关(违背会导致弱工具 — 特殊:有很多的弱工具 many weak instruments)、与误差项不相关(违背会使得工具变的无效Invalid),以上最好有理论证明一般采用二阶段最小二乘法(2SLS)进行回归;当随机扰动项存在异方差或自相关的问题,2SLS就不是有效
Stata学习(1)
一、五大窗口 Command窗口:实现人机交互 来导入一个自带数据: sysuse是导入系统自带的数据,auto导入该数据的名称,后面的clear是清除之前的数据 结果窗口:展示计算结果、查找功能 在Edit的find可以实现查找功能,或者ctrl+f;清屏右击有clear 回顾窗口:保存执行过的命令,漏斗可以进行筛选,点击后会自动跑到命令窗口,直接双击会执行 导

泛谈一下数字化技能的学习,SPSS、Stata还是Python?技术、业务+表达、展现!
1.本科、专科上学时对于这些偏数学类的课程还是要好好学习 应知乎、小红书、CSDN很多年轻朋友、同学们的邀请,今天我泛谈一下数字化技能的学习。很多学生在本科或专科上学时代学过统计学、计量经济学、机器学习、数据分析、统计分析、数据挖掘、量化建模等一门或多门课程,至少也学过概率论、数理统计、线性代数、微积分等课程,其实就已经具备了相对较好的数据分析基础。等到本科或专科毕业后,有的同学致力于读研、读博
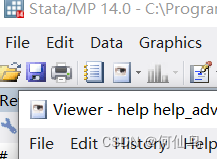
第11章Stata回归诊断与应对
目录 11.1异方差检验与应对 案例延伸 11.2自相关检验与应对 案例延伸 11.3多重共线性检验与应对 案例延伸 在上以讲中,简要介绍了最小二乘线性回归,这种方法可以满足大部分的研究需要。但是这种分析方法的有效性建立在变量无异方差、无自相关、无多重线共线性的基础之上。显示生活中很多数据是不满足这些条件的。那就需要用到在本章中介绍的回归诊断与应
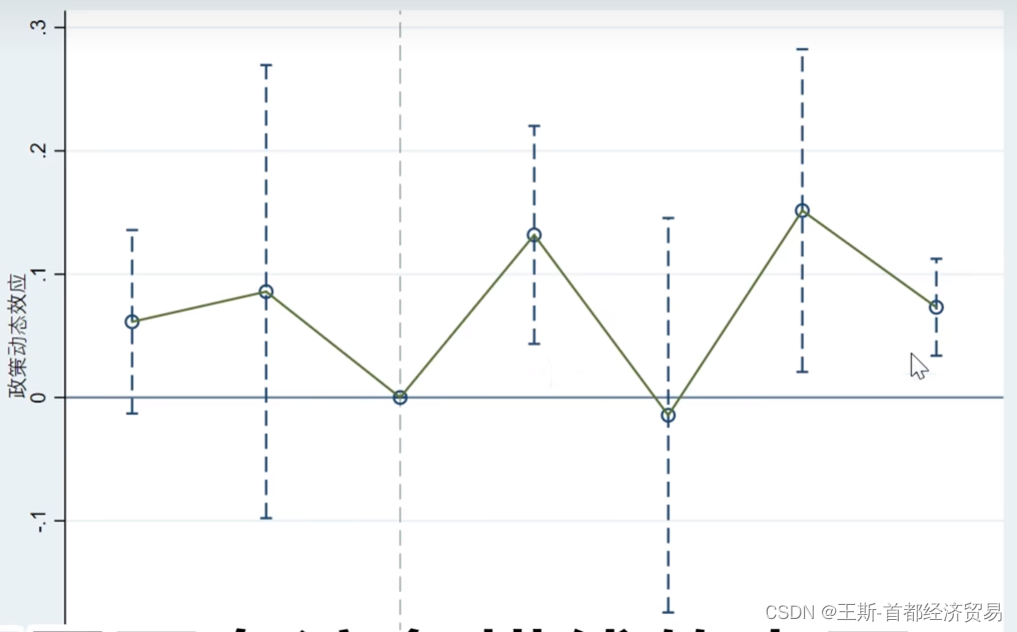
基于stata的DID平行趋势检验
前言 DID平行趋势检验定义 定义:评估两变量数据之间是否会存在某种同幅度增减情况的相关关系检验方法 重要性:为何要做平行趋势检验?平行趋势检验在DID模型中是非常重要的一步,用于验证处理组和对照组在干预前的趋势是否平行。只有当变量通过了平行趋势检验,我们才能更可靠地构建DID模型并进行实证分析。 判断方式: 时间趋势图,绘制处理组和对照组在干预前的趋势图。图形上的趋势应该是

一文讲透Excel数据如何导入到Stata?
推荐采用《Stata统计分析从入门到精通》 杨维忠、张甜 清华大学出版社“1.2.6 导入其他格式的数据文件” 的解答。 在Stata主界面选择“文件|导入”命令(如图所示),即可看到Stata支持的其他格式的数据文件类型,包括Excel电子表格、文本数据、SPSS数据、SAS数据、固定格式文本数据、字典定义的固定格式文本数据、自由格式文本数据、SAS XPORT V8、SAS XPORT V5
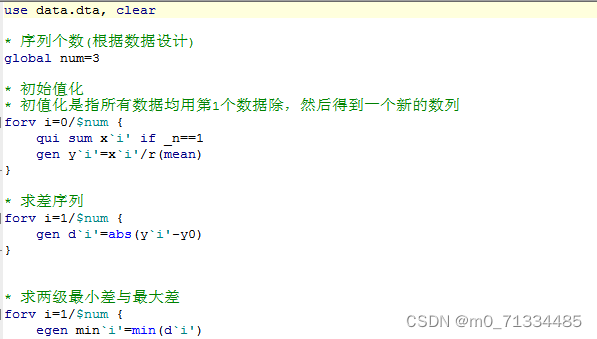
灰色关联度分析详细Stata代码和说明(代码+案例数据+说明)
灰色关联度分析详细Stata代码和说明(代码+案例数据+说明) 因素分析的基本方法过去采用的主要是统计的方法,如回归分析,回归分析虽然是一种较通用的方法,但大都只用于少因素的、线性的。 对于多因素的,非线性的则难以处理。 灰色系统理论考虑到回归分析方法的种种弊病和不足,采用关联分析的方法来作系统分析。 灰色关联度分析法(Grey Relational Analysis)是灰色系统分析方法的

STATA计算AIC、BIC、MSE、MAE、MAPE值
用STATA做普通的回归时,计算AIC、BIC、MSE、MAE、MAPE并不难,甚至像MSE这样的都会直接给出,但是比如做logit、probit或者mlogit、mprobit甚至ologit、oprobit时,上述五个就不太容易了,在网上搜集了很久,也走了不少弯路。现将方法及代码整理如下: 1.计算AIC、BIC 在做完回归后,紧跟 estat ic 即可得到AIC、BIC 忘记在哪

STATA做滚动窗口回归
在做回归之前要先设置时间(这里我们用的时间变量名为time,数据是1到60) tsset time 然后就可以开始做回归了(回归结果会覆盖之前的数据集,记得保存好之前的数据) rolling, window(30) recursive rrecursive : regress y x1 x2 切记 recursive rrecursive只能同时存在一个 recursive 命令是
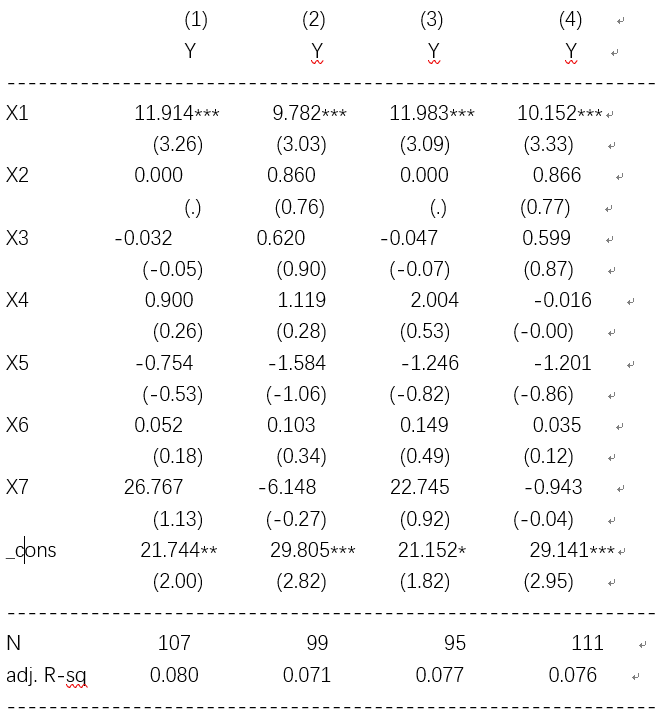
STATA中eststo命令安装及使用
常用的 est store modelx接 est table命令有两大不方便的地方,一是modelx的数据是保存在dta文件中的,换一个数据集结果就没了(当然也是优势,可以让别人拿到dta文件后直接看到你的回归结果)二是 est table输出结果中不能同时列示***(显著性)和标准差,而且标准差需要自己加括号(也可能有自动加括号的命令但我不知道)。 这里我们就要用到ests

固定效应模型-以stata为工具
固定效应模型-以stata为工具 文章目录 1.固定效应模型2. 模型原理3. `stata`代码实现 1.固定效应模型 固定效应模型(Fixed Effects Model)是一种面板数据分析方法,通过引入个体固定效应来控制个体间的异质性,并更准确地估计解释变量对因变量的影响。它在许多经济、社会科学和健康研究中被广泛应用。 面板数据由多个个体(例如个
计量经济学及stata应用思维导图_广东白云学院外国语学院举行英语学习与思维导图应用大赛_民办院校新闻...
近日,由广东白云学院外国语学院主办的第二课堂活动——广东白云学院第二届英语学习与思维导图应用大赛圆满结束。本次大赛意在为广大英语爱好者提供一种更为有效的英语学习方法,同时也提供一个互相交流和展现学习的平台,让更多的学生通过竞赛的方式学会在英语学习中更灵活运用思维导图这一高效的工具,培养他们的创新思维和批判性思维能力。 本次大赛面向所有在校本专科学生,作品可以围绕在英语学习中的各类话题,包括

2000-2022年上市公司CEO 高管及董事会环保背景数据(5W+ )(原始数据+处理代码Stata do文档)
2000-2022年上市公司CEO 高管及董事会环保背景数据(5W+ )(原始数据+处理代码Stata do文档) 1、时间:2000-2022年 2、指标:证券代码、股票代码、年份、股票简称、ST或PT为1,否则为0、金融业为1,否则为0、行业名称、行业代码、制造业取两位代码,其他行业用大类、 高级管理层人数、董事会人数、环保背景高管总数、环保背景董事会成员总数、董事长是否有环保背景、CE

HLM(多层线性模型)在stata中语句
在阅读CEPS中发现有些研究采用的是HLM模型,HLM简单来说用一个方程跑两个回归。举例,对学习成绩影响因素,不同层有不同的影响,如在个体层面上个体特征会对成绩产生影响,在学校层面学校排名等因素会对成绩产生影响,两种因素不在一个层面,每层造成的差异都不相同。 在找相关语句时候发现操作这个语句的软件大多是SPSS和HLM,对于stata操作者并不友好。因此,在有限资料中总结了HLM在stata中的语
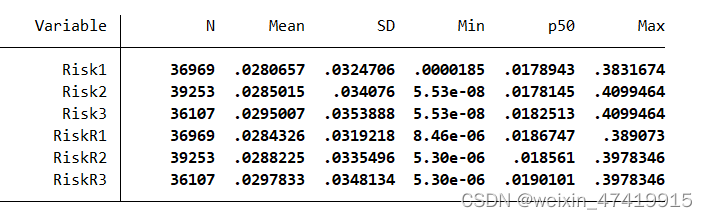
Stata企业风险承担水平:2000-2021年
1.数据说明 数据年份:2000-2021年 数据内容: 以息税前利息/总资产与息税折旧摊销前利润/总资产作为计算风险变量包含t-2到t期,t-1到t+1期,以及t到t+2期三年窗口的风险标准差测算 数据处理: 1.保留沪深A股股票(可自行选取其他市场) 2.剔除金融行业股票数据(可自行其他标准) 3.保留正常交易股票,剔除终止上市、暂停上市以及停牌股票 4.对连续变量在上下 1%的水平上进
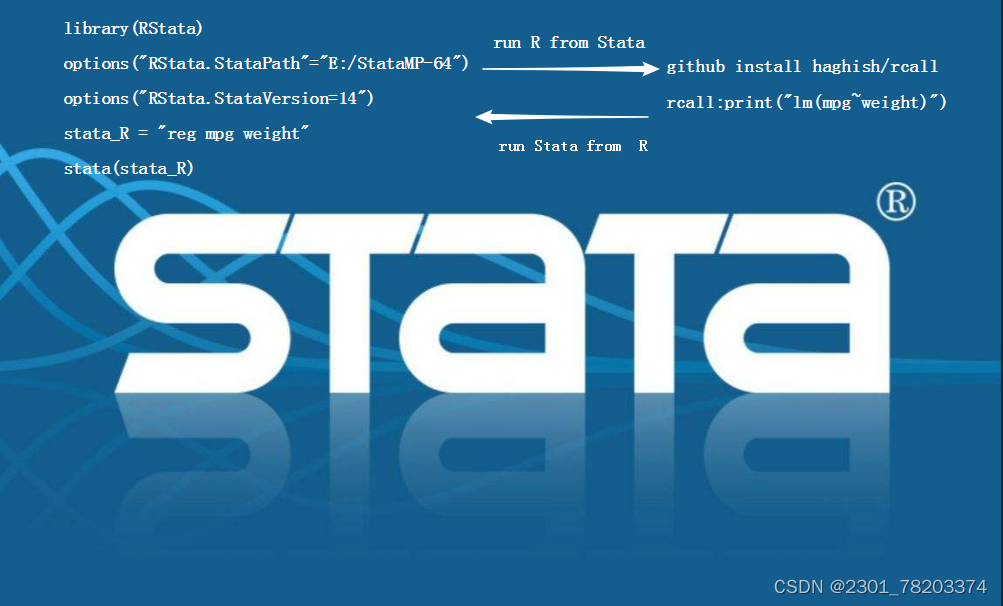
Stata 17中文版软件:Stata 最新版下载附安装教程及功能使用(2)
STATA是一款常用的统计分析软件,广泛应用于社会科学、医学、经济学、金融等领域。它不仅具备丰富的统计分析功能,而且操作简单易学,因此备受研究人员和实践者的喜爱。本文将从实际案例出发,介绍一些STATA软件的使用技巧。 如何使用STATA进行线性回归分析 STATA安装包下载: soruan.top/YcWIJOd.STATA 包内含安装教程 线性回归分析是一种常见的数