本文主要是介绍灰色关联度分析详细Stata代码和说明(代码+案例数据+说明),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
灰色关联度分析详细Stata代码和说明(代码+案例数据+说明)
因素分析的基本方法过去采用的主要是统计的方法,如回归分析,回归分析虽然是一种较通用的方法,但大都只用于少因素的、线性的。
对于多因素的,非线性的则难以处理。 灰色系统理论考虑到回归分析方法的种种弊病和不足,采用关联分析的方法来作系统分析。
灰色关联度分析法(Grey Relational Analysis)是灰色系统分析方法的一种。是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。
对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度。
在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。因此,灰色关联法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。
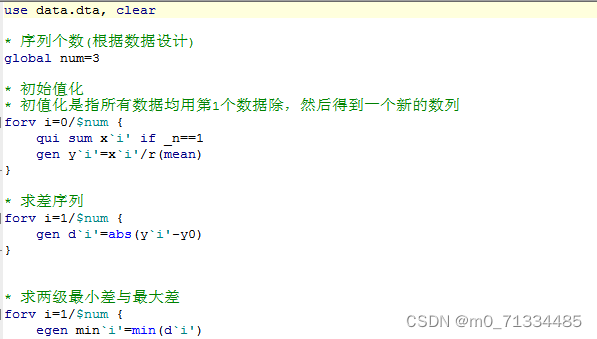
文件包含灰色关联度计算代码以及计算方式介绍文档
下载链接:
灰色关联度分析详细Stata代码和说明(代码+案例数据+说明)![]() https://download.csdn.net/download/m0_71334485/88731395
https://download.csdn.net/download/m0_71334485/88731395
这篇关于灰色关联度分析详细Stata代码和说明(代码+案例数据+说明)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






