本文主要是介绍stata空间计量模型基础+检验命令LM检验、sem、门槛+arcgis画图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 怎么安装stata命令 3
- 怎么使用已有的数据 4
- 数据编辑器中查看数据 4
- 怎么删除不要的列 4
- 直接将字符型变量转化为数值型的命令 4
- 改变字符长度 4
- 描述分析 4
- 取对数 5
- 相关性分析 5
- 单位根检验 5
- 权重矩阵标准化 6
- 计算泰尔指数 6
- 做核密度图 7
- Moran’s I 指数 8
- 空间计量模型 9
- LM检验 10
- Hausman 检验 11
- LR 检验 11
- 检验是否退化 13
- Wald 检验 14
- 交互效应 14
- 中介效应 15
- 门槛模型 19
- Arcgis画图 20
- 怎么选择想要的省份 24
- 空间引力模型 25
1.怎么安装stata命令
① ssc install 名字
② search 名字
在打开的网页点击随便一个蓝色连接
点击click…

完成

2.怎么使用已有的数据
文件——更改工作目录——选择到数据所在的文件位置——确定
这样子就把当前的stata程序也保存在了同一目录下了,就可以使用在此文件的数据了
3.数据编辑器中查看数据
4.怎么删除不要的列
导入数据——use data——drop 名字
5.直接将字符型变量转化为数值型的命令
当数据格式是str,文本类型,所以呈现红色
destring 变量名,replace 新的名字(英文)
encode 变量,generate(yy)
6.改变字符长度
format var8 %16.0g *16.0意思是改为16个字符那么长
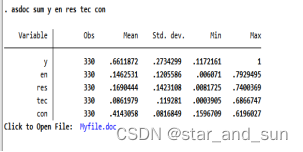
7.描述分析
ssc inatall asdoc *下载包
asdoc sum y en res tec con
8.取对数
foreach var of varlist y en res tec con{
gen ln ‘var’=log(‘var’)}
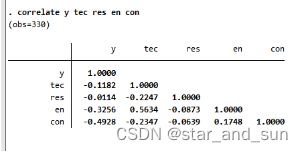
9.相关性分析
correlate y tec res en con
10.单位根检验
n大于t可以不做,想要检验一个名为“inflation”的变量是否存在单位根,可以运行以下命令
DF检验
dfuller inflation, trend
ADF检验
Dfuller inflation, lags(4)
面板数据单位根检验
如果p值小于显著性水平,则可以拒绝原假设并认为该变量不存在单位根。
xtunitroot llc lnrxrate , demean lags(aic 10) kernel(bartlett nwest)
demean表示去截面均值
lags(#) 表示序列变量差分的滞后项数#,其中截面滞后阶数相同
lags(aic #) lags(bic #) lags(hqic #)以aic bic hqic准则判定最大滞后阶数#
trend 表示加入趋势项并默认加入个体固定项
noconstant 表示趋势项与个体项都不加入
trend和noconstant都不加默认个体固定项
kernel(kernel_spec) 为核函数,估计渐进方差,具体设定包括 ba pa qu等)
11.权重矩阵标准化
spatwmat using W.dta, name(W) standardize *行标准化
12.计算泰尔指数
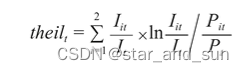

数据如下

. use data3.dta
. gen I城镇= 城镇人口* 城镇收入
. gen I农村= 农村人口农村收入
. sort I农村
. gen Iall= I城镇+ I农村
. gen Pall=城镇人口+ 农村人口
. gen I比例城镇= I城镇/ Iall
. gen I比例农村= I农村/ Iall
. gen p比例城镇= 城镇人口 / Pall
. gen p比例农村= 农村人口 / Pall
. gen theil= I比例城镇ln( I比例城镇/ p比例城镇)+ I比例农村*ln( I比例农村/ p比例农村)
. sum thei
13.做核密度图
假如做城镇收入的核密度图
kdensity 城镇收入
更改坐标
. kdensity 城镇收入,xlabel(0.1(0.2)1.5) ylabel(0(0.2)1.5)
画多个核密度
. kdensity 城镇收入,addplot(kdensity 农村收入) xlabel(0.1(0.2)1.5) ylabel(0(0.2 )1.5) *两个图
. kdensity 城镇收入,addplot((kdensity 农村收入)(kdensity 城镇人口)) xlabel(0.1(0.2)1.5) ylabel(0(0.2)1.5) *三个图
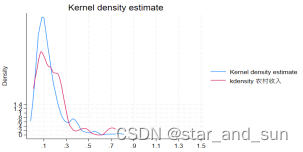
增加坐标名
. kdensity 城镇收入,xlabel(0.1(0.2)1.5) ylabel(0(0.2)1.5) title(“收入核密度图”) xtitle(“时间”) ytitle(“密度”)
14.Moran’s I 指数
preserve
keep if year==2010
spatgsa y,weights(W) moran
restore
*把年份改了就可以做所有年的,结果中p值小于0.1则存在空间效应

15.空间计量模型
先把空间权重矩阵放进去
spatwmat using w.dta,name(w) standardize *标准化
clear
use data *使用数据
xtset id year
随机效应模型
xsmle y x a, model(sdm) wmat(W) type(both) nolog effects re
时间固定效应
xsmle y x a, model(sdm) wmat(W) type(time) nolog effects fe
个体固定效应
xsmle y x a, model(sdm) wmat(W) type(ind) nolog effects fe
双固定效应
xsmle y x a, model(sdm) wmat(W) type(both) nolog effects fe
- effects表示显示直接效应、间接效应与总效应,noeffects不显示
加上约束变量只看x1的空间效应
xsmle y x1 x2 x3,wmat(W) durbin(x1) model(SDM) fe
est ic看AIC BIC
16.LM检验
*判断是否存在空间依赖性,是才可以做空间计量模型
*进行LM检验之前,需要将空间权重矩阵扩大
use w / /W 为权重名称
spcs2xt a1-a30,matrix(w)time(13) //扩大13倍
spatwmat using wxt,name(W)
clear
use data *调用论文数据 data
xtset id year
reg y x1 x2 x3 a1 a2 a3 a4 *ols的结果
spatdiag,weights(W) *LM检验
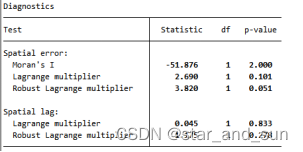
一般来说,P值小于0.1则显著。Spatial error为空间误差模型(SEM);Spatial lag为空间滞后模型(SAR);Robust为结果稳健的意思。Error的p值不显著,不适合空间误差,在这里空间滞后也不显著。

17.Hausman 检验
检验用于选择固定效应模型还是随机效应模型,用没有扩大的权重矩阵
方法一
spatwmat using w.dta,name(w) standardize
xsmle y en res tec con , fe model(sdm) wmat(w) hausman nolog noeffects

p大于0.1选择随机,否则选择固定
方法二
xsmle y x1 x2 x3 a1 a2 a3 a4 , fe model(sdm) wmat(W) nolog noeffects type(both)
est store fe
xsmle y x1 x2 x3 a1 a2 a3 a4 , re model(sdm) wmat(W) nolog noeffects type(both)
est store re
hausman fe re
18.LR 检验
判断使用何种固定效应模型,检验地区固定效应、时间固定效应以及双固定效应,三种效应哪个最适合
spatwmat using W, name(W) standardize
个体固定
xsmle y x1 x2 x3 a1 a2 a3 a4 , fe model(sdm) wmat(W) nolog noeffects type(ind)
est store ind
时间固定
xsmle y x1 x2 x3 a1 a2 a3 a4 , fe model(sdm) wmat(W) nolog noeffects type(time)
est store time
双固定
xsmle y x1 x2 x3 a1 a2 a3 a4 , fe model(sdm) wmat(W) nolog noeffects type(both)
est store both
lrtest both ind,df(10) *看哪一个最优
lrtest both time,df(10)
操作案例
xsmle y en res tec con , fe model(sdm) wmat(w) nolog noeffects type(ind)
est store ind
xsmle y en res tec con , fe model(sdm) wmat(w) nolog noeffects type(time)
est store time
xsmle y en res tec con , fe model(sdm) wmat(w) nolog noeffects type(both)
est store both
lrtest both ind,df(10) *这才是判断哪一个最优,前面只需要跑一下就可以了

可见P值显著,那么拒绝使用个体,从而使用both

同理选择双向固定的both
19.检验是否退化
检验空间杜宾模型是否会退化为空间滞后模型和空间误差模型
操作案例
xsmle y en res tec con , fe model(sdm) wmat(w) nolog noeffects type(both)
est store sdm
xsmle y en res tec con , fe model(sdm) wmat(w) nolog noeffects type(both)
est store sar
. xsmle y en res tec con , fe model(sem) emat(w) nolog noeffects type(both)
est store sem
lrtest sdm sar *H0:SDM退化为SAR
如果P小于0.1显著,不可以退化,P值大于0.1,说明可以退化
lrtest sdm sem *H0:SDM退化为SEM
如果P小于0.1显著,不可以退化,P值大于0.1,说明可以退化
20.Wald 检验
clear all
use data
spatwmat using W.dta,name(W) standardize
xtset id year
xsmle y x a, fe model(sdm) wmat(W) type(both) nolog noeffects
Test x=a=0
Test [wx]x=0
Test[wx]x=[wx]a=0
estat ic
21.交互效应

gen c = a*b 产生a和b的交互项
然后做回归
gen c = enres
reg y en res con c
11.中介效应
ba和c’同号则表示发挥了中介效应,异号则表示稀释效应。
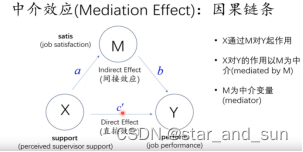
中介效应方法一
reg tec en res con *在这里假设tec为中介变量,en是核心解释变量
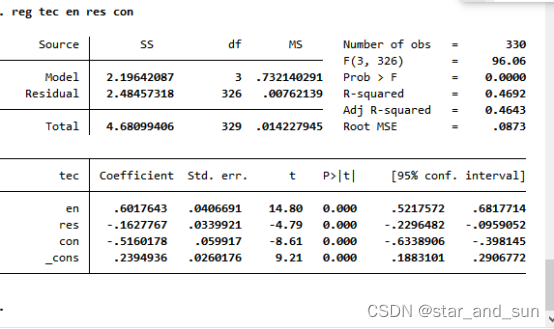
看en所对应的p小于0.1可见是显著的
estimates store reg1 *结果存起来
reg y res con tec en
*tec所对应的p值小于0.1
*tec所对应的p值小于0.1
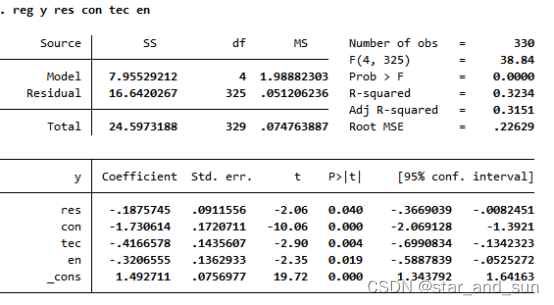
estimates store reg2
esttab reg1 reg2 using out.doc,mtitles r2(%6.2f) ar2(%6.2f)
*把结果输入到word其中r2为R方 ar2为调整的
*如果都显著说明存在中介效应,在这里reg2回归中en前面的系数是显著的,说明中介变量发挥的是部分效应,如果一个显著一个不显著需要用bootstrap检验,检验如下
bootstrap r(ind_eff) r(dir_eff),reps(1000):sgmediation y mv(tec) iv(en) cv(con res)
*mv里面是中介变量 iv是自变量 cv是控制变量
中介效应方法二
逐步回归
ssc install reghdfe
ssc install ftools
reghdfe y res en con,absorb(id year) vce(cluster id)
*在这里假设tec为中介变量,en的核心解释变量
est store m1
reghdfe tec res en con,absorb(id year) vce(cluster id)
est store m2
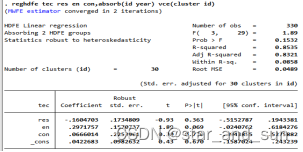
reghdfe y tec res en con,absorb(id year) vce(cluster id)

est store m3
esttab m1 m2 m3 using out.doc,mtitles r2(%6.2f) ar2(%6.2f)
*结果主要看第二步en前的系数是否显著和第三步tec前面的系数是否显著,两个都显著说明存在中介效应
如果一个显著一个不显著需要用bootstrap检验,检验如下
bootstrap r(ind_eff) r(dir_eff),reps(1000):sgmediation2 y mv(tec) iv(en) cv(con res)
sobel检验
net install sgmediation2, from(“https://tdmize.github.io/data/sgmediation2”)
*安装命令
Sgmediation2 y, mv(tec) iv(en) cv(con res) *cv里面不能用i.id,要手工产生
tab id,gen(id) *生成个体虚拟变量
ssgmediation2 y,mv( tec ) iv( en ) cv( con res id1-id30) quietly
*quietly表示不显示逐步回归
自助法
bootstrap r(ind_eff) r(dir_eff),reps(1000) bca:sgmediation2 y mv(tec) iv(en) cv(con res id1-id30)
*(ind_eff)表示间接效应,(dir_eff)表示直接效应,结果包括0就显著,不包括0就不显著
12.门槛模型
xthreg y c1 c2 c3 c4, rx(x1) qx(x2) thnum(1) bs(300) trim(0.01) grid(100)
其中,y表示被解释变量,c1-c4表示控制变量,rx表示核心解释变量,qx表示门槛变量,thnum表示门槛个数bs表示自举次数(理论上越多越好,但是考虑到效率,一般设置成300以上),trim表示门限分组内异常值去除的比例(一般选0.01或0.05),grid表示样本网格计算的网格数(一般设置成100或300),r表示用聚类稳健标准误
单一门槛
xthreg y c1 c2, rx(x1) qx(x2) thnum(1) bs(300) trim(0.01) grid(100) r
双门槛
xthreg y c1 c2, rx(x1) qx(x2) thnum(2) bs(300 300) trim(0.01 0.01)grid(100) r
三门槛
xthreg y c1 c2, rx(x1) qx(x2) thnum(3) bs(300 300 300) trim(0.01 0.01 0.01) grid(100) r

*这里的p不显著说明不存在门槛值
三门槛结果解读
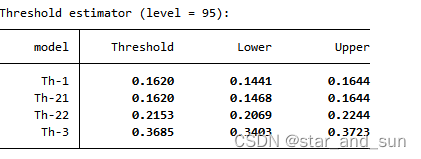
*如果p都小于0.1,那么0.3685第一门槛值 0.1620 第二 0.2153第三,门槛值从小到大看是第几个门槛

*假设p值小于0.1,表示在门槛值小于第一门槛值时en对解释变量y的影响为0.31,介于第一和第二门槛值是en对y的影响是0.818,以此类推
13.Arcgis画图
蓝色➕插入地图信息
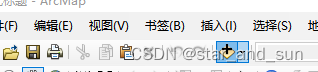
右键——连接

选择连接的文件
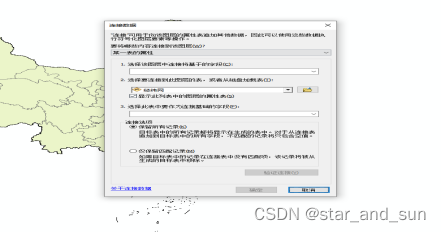
以NAME为连接字段 ——选择连接的文件
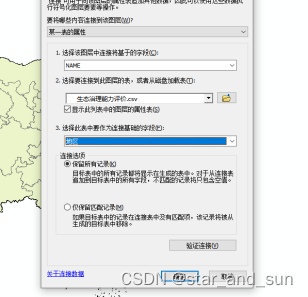
打开数据属性表可以看看连接情况
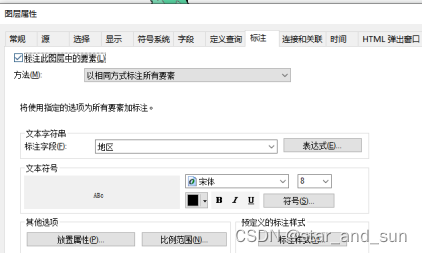
右键——点击属性——标注——字段选择(name)——应用

符号系统——数量

值(要画的数据) 色带自己选择喜欢的

怎么把局部的放大呢(显示南海这些区域)
插入——数据框——复制行政区 国界线——布局视图


插入——文本——输入标题名字
布局试图下——插入——比例尺——插入——指北针

14.怎么选择想要的省份
选择+shift(在知道地理位置的时候)
打开属性表——NAME_——获取唯一值——大写的IN依次点击省份名字用英文逗号隔开——右键——选择——所选建立图层


15.空间引力模型

这篇关于stata空间计量模型基础+检验命令LM检验、sem、门槛+arcgis画图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






