stacking专题

机器学习:Voting和Stacking的模型融合实现
NLP:Voting和Stacking的模型融合实现 参考资料: 最全NLP中文文本分类实践(下)——Voting和Stacking的模型融合实现

学习法之Stacking
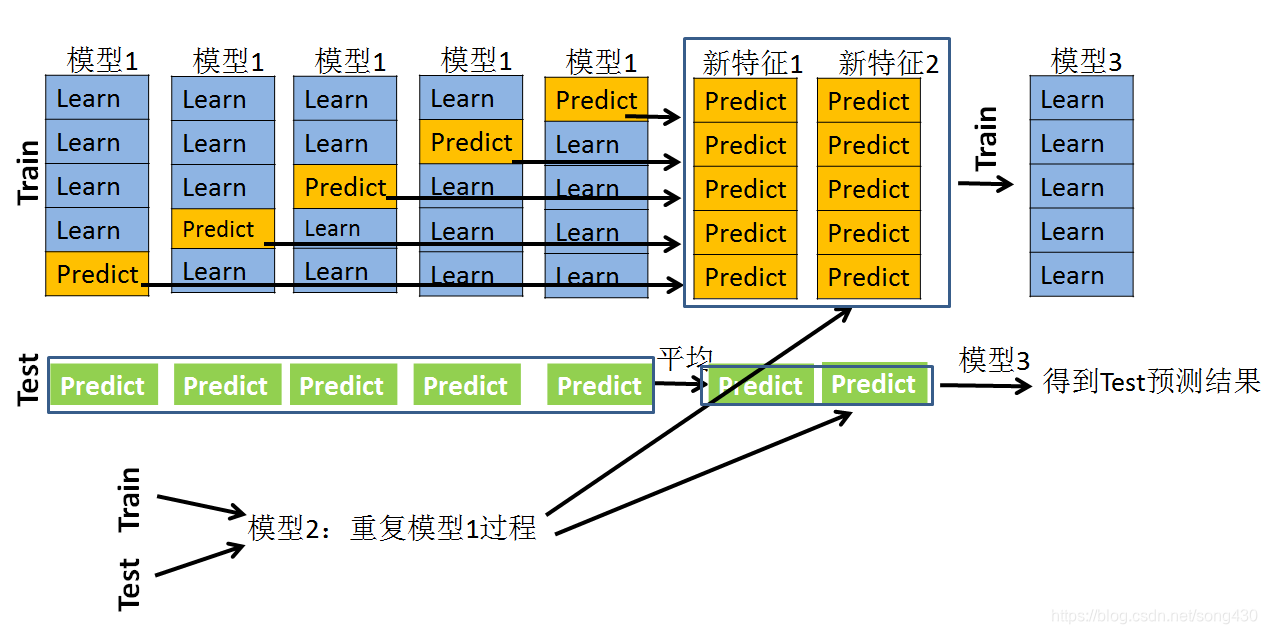
本文转载自:详解stacking过程 之前一直对stacking一知半解,找到的资料也介绍的很模糊。。所以有多看了几篇文章,然后来此写篇博客,加深一下印象,顺便给各位朋友分享一下。 stacking的过程有一张图非常经典,如下: 虽然他很直观,但是没有语言描述确实很难搞懂。 上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证

UVA 103--- Stacking Boxes
这道题在小白书中的分类是动态规划,把题AC了之后在网上看解题报告后,多数解法也是DAG上的动态规划。但其实一个简单的深度优先就能解决问题了。首先将每数从大到小排序,再将各组按照排序后的第一个数字的大小进行从大到小排序。需要注意的是,记录各组数据的编号也要和数进行同步的排序。 #include <iostream>#include <cstdio>#include <vect
Boosting Bagging Stacking整理
一. 知识点 Bias-Variance Tradeoff bias-variance是分析boosting和bagging的一个重要角度,首先讲解下Bias-Variance Tradeoff. 假设training/test数据集服从相似的分布,即 yi=f(xi)+ϵi, y i = f ( x i ) + ϵ i , y_i = f(x_i) + \epsilo
UVA - 103 Stacking Boxes
题意:n维向量,如果向量A,B每一位上的数A都比B大,则A可以嵌套住B,求最大的嵌套个数,并输出依次是第几个。 思路:构成一个有向图DAG,如果X可以嵌套在Y里,那么X到Y就有一个有向边,最后就是求DAG上的最长路径 #include <iostream>#include <cstdio>#include <cstring>#include <algorithm>using names

深度解析CSS中为什么会有Stacking Context的概念
CSS中的堆叠上下文(Stacking Context)概念是为了管理和控制网页元素的重叠顺序而引入的。堆叠上下文的引入解决了以下几个关键问题: 层次管理: 在网页中,多个元素可能会相互重叠,堆叠上下文定义了这些元素的堆叠顺序。通过明确的规则,浏览器可以决定哪些元素显示在前面,哪些元素在后面。 隔离与控制: 堆叠上下文使得不同的层次独立,可以在不同的上下文中控制元素的层次关系而不影响其他上下
POJ 1988 Cube Stacking (带权并查集)
题目链接:Cube Stacking num数组表示集合个数,under表示比他小的个数即可 代码: #include <stdio.h>#include <string.h>const int N = 30005;int p, a, b, parent[N], under[N], num[N];char q[2];void init() {for (int i = 1; i <
![bzoj3376/poj1988[Usaco2004 Open]Cube Stacking 方块游戏 — 带权并查集](https://img-blog.csdn.net/20161026144241380?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
bzoj3376/poj1988[Usaco2004 Open]Cube Stacking 方块游戏 — 带权并查集
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3376 题目大意: 编号为1到n的n(1≤n≤30000)个方块正放在地上.每个构成一个立方柱. 有P(1≤P≤100000)个指令.指令有两种: 1.移动(M):将包含X的立方柱移动到包含Y的立方柱上. 2.统计(C):统计名含X的立方柱中,在X下方的方块数目. 题解: 带
poj 1988 Cube Stacking (poj 1182 食物链(转))
昨晚上和今一早,做了食物链后,便做了这个题,做的郁闷。刚开始的时候我拿最下面的当根节点,做出来后发现这样会漏情况的。比如:11M 1 10M 2 10M 3 10M 4 10M 5 10M 10 6C 10C 4M 4 8C 3C 4 这组测试数据,在M 4 8 合并后,元素3的下方就会漏掉一个箱子。 后来实在没办法了,上网看了看,大家都是以最上面的为根节点o(╯□╰)o(自己好笨。。。),那样
基于Python的Stacking集成机器学习实践
【翻译自 : Stacking Ensemble Machine Learning With Python】 【说明:Jason Brownlee PhD大神的文章个人很喜欢,所以闲暇时间里会做一点翻译和学习实践的工作,这里是相应工作的实践记录,希望能帮到有需要的人!】 Stacking或Stacked Generalization是一种集成的机器学习算法。

堆叠式神经网络模型stackingKeras【Stacking+Keras】+GUI可视化应用,原理讲解+代码详细实现说明【超强的模型神器,支持自定义】
声明: 本博客中的VIP系列博客内容严禁转载,未经允许不得以任何形式进行传播,违者追究侵权责任! 堆叠式神经网络模型【Stacking+Keras】+GUI可视化应用

集成学习之Stacking
Stacking算法 算法思想 Stacking是一种堆叠模型,分为多个阶段模型,首先是第一阶段模型预测出结果,之后送入第二阶段模型来实现模型的融合,通过减少模型的方差来获得更高的预测精度。 算法步骤 算法步骤下图所示(参考博客) 我们首先将数据集划分为训练集和测试集,假设数量分别为10000和2000,这时我们采用交叉验证的方式,将训练集划分成5份,其中四份用来做真正的训练集,一份用来
Boosting、Bagging和Stacking知识点整理
全是坑,嘤嘤哭泣= = 简述下Boosting的工作原理 Boosting主要干两件事:调整训练样本分布,使先前训练错的样本在后续能够获得更多关注 集成基学习数目 Boosting主要关注降低偏差(即提高拟合能力)描述下Adaboost和权值更新公式 Adaboost算法是“模型为加法模型、损失函数为指数函数、学习算法为前向分布算法”时的二类分类学习方法。 Adaboost有两项内容:


数据挖掘终篇!一文学习模型融合!从加权融合到stacking, boosting
模型融合:通过融合多个不同的模型,可能提升机器学习的性能。这一方法在各种机器学习比赛中广泛应用, 也是在比赛的攻坚时刻冲刺Top的关键。而融合模型往往又可以从模型结果,模型自身,样本集等不同的角度进行融合。 数据及背景 零基础入门数据挖掘 - 二手车交易价格预测_学习赛_赛题与数据_天池大赛-阿里云天池的赛题与数据(阿里天池-零基础入门数据挖掘) 模型融合 如果你打算买一辆车,你会
![[机器学习]集成学习--Bagging、Boosting、Stacking 与 Blending](https://img-blog.csdnimg.cn/c81b38d7de844f4e94c667ec04ccc98f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA56ev5p6B5ZCR5LiK55qE5aKo6bG85LuU,size_15,color_FFFFFF,t_70,g_se,x_16)
[机器学习]集成学习--Bagging、Boosting、Stacking 与 Blending
一 集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。 如何产生“好而不同”的个体学习器,是集成学习研究的核心。 集成学习的思路是通过合并多个模型来提升机器学习性能,这种方法相较于当个单个模型通常能够获得更好的预测结果。这也是集成学习在众多高水平的比赛如奈飞比赛,KDD和Kaggle,被首先推荐使用的原因。 一般来说集成学习可以分为三大类:
模型融合中的stacking方法
本文参考了Kaggle机器学习之模型融合(stacking)心得 stacking是用于模型融合的一个大杀器,其基本思想是将多个模型的结果进行融合来提高预测率。,理论介绍有很多,实际的例子比较少,本文将其实例化,并给出详细的代码来说明具体的stacking过程是如何实现的。stacking理论的话可以用下面的两幅图来形象的展示出来。 结合上面的图先做一个初步的情景假设,假设采用5折交叉验证:
noi.openjudge 2406:Card Stacking
http://noi.openjudge.cn/ch0304/2406/ 描述 Bessie is playing a card game with her N-1 (2 <= N <= 100) cow friends using a deck with K (N <= K <= 100,000; K is a multiple of N) cards. The deck contains
集成学习(Bagging、Boosting、Stacking)
组合多个学习器:集成方法(ensemble method) 或 元算法(meta-algorithm)。 不同算法的集成(集成个体应“好而不同”)同一算法在不同设置的集成数据集不同部分分配给不同分类器之后的集成 集成学习中需要有效地生成多样性大的个体学习器,需要多样性增强: 对 数据样本 进行扰动(敏感:决策树、神经网络; 不敏感:线性学习器、支持向量机、朴素贝叶斯、k近邻)对 输入属性

模型竞赛大杀器-(stacking)融合模型
一套弱系统能变成一个强系统吗? 当你处在一个复杂的分类问题面前时,金融市场通常会出现这种情况,在搜索解决方案时可能会出现不同的方法。 虽然这些方法可以估计分类,但有时候它们都不比其他分类好。 在这种情况下,合理的选择是将它们全部保留下来,然后通过整合这些部分来创建最终系统。 这种多样化的方法是最方便的做法之一:在几个系统之间划分决定,以避免把所有的鸡蛋放在一个篮子里。 一旦我对这种情况
Boosting Bagging Stacking Mapping 区别
Boosting: Boosting 是一种集成学习技术,其中多个机器学习模型(通常是决策树)被顺序训练。每个后续模型都关注先前模型所犯的错误,对错误分类的数据点给予更多权重。这样,Boosting 就会结合这些弱模型的预测来创建一个强预测模型。流行的 boosting 算法包括 AdaBoost、Gradient Boosting 和 XGBoost。 Bagging: Bagging 是 B