本文主要是介绍模型融合中的stacking方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文参考了Kaggle机器学习之模型融合(stacking)心得
stacking是用于模型融合的一个大杀器,其基本思想是将多个模型的结果进行融合来提高预测率。,理论介绍有很多,实际的例子比较少,本文将其实例化,并给出详细的代码来说明具体的stacking过程是如何实现的。stacking理论的话可以用下面的两幅图来形象的展示出来。
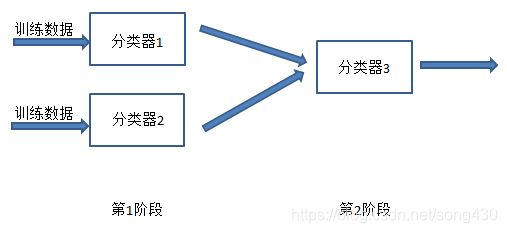
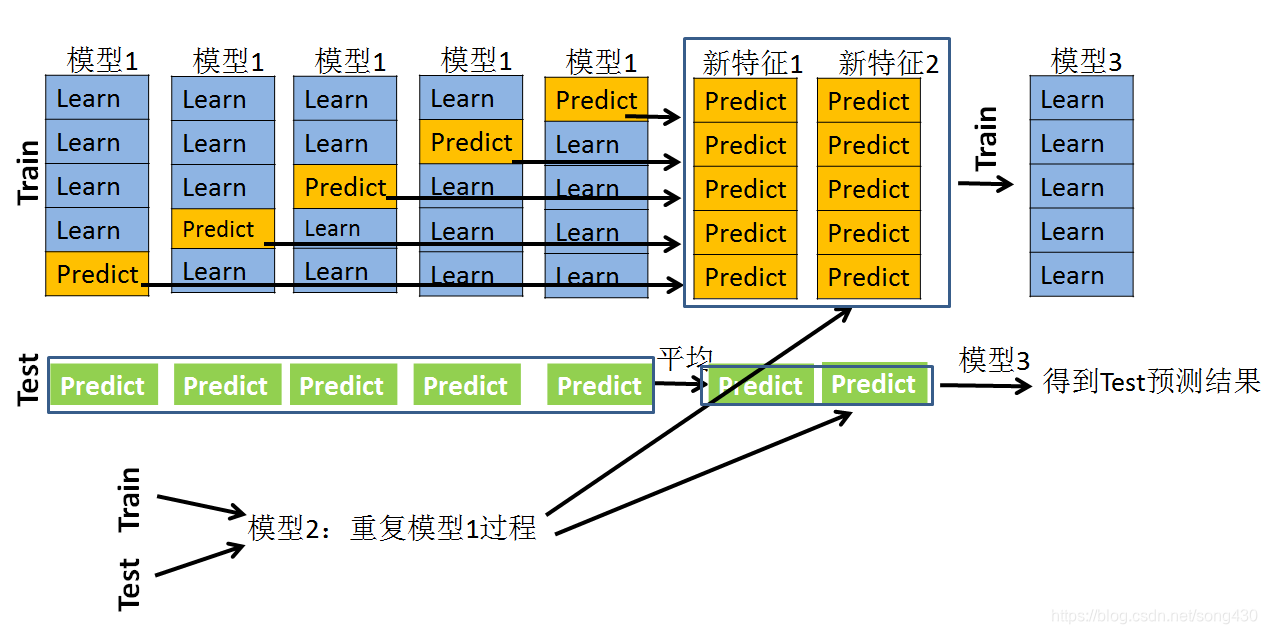
结合上面的图先做一个初步的情景假设,假设采用5折交叉验证:
训练集(Train):训练集是100行,4列(3列特征,1列标签)。
测试集(Test):测试集是30行,3列特征,无标签。
模型1:xgboost。
模型2:lightgbm。
模型3:贝叶斯分类器
第一步
对于模型1来说,先看训练集:
采用5折交叉验证,就是要训练5次并且要预测5次。先把数据分成5份,每一次的训练过程是采用80行做训练,20行做预测,经过5次的训练和预测之后,全部的训练集都已经经过预测了,这时候会产生一个100 × \times × 1的预测值。暂记为P1。
接下来看一看测试集:
在模型1每次经过80个样本的学习后,不光要预测训练集上的20个样本,同时还会预测Test的30个样本,这样,在一次训练过程中,就会产生一个30 × \times × 1的预测向量,在5次的训练过程中,就会产生一个30 × \times × 5的向量矩阵,我们队每一行做一个平均,就得到了30 × \times × 1的向量。暂记为T1。
模型1到此结束。接下来看模型2,模型2是在重复模型1的过程,同样也会产生一个训练集的预测值和测试集的预测值。记为P2和T2。这样的话,(P1,P2)就是一个100 × \times × 2的矩阵,(T1,T2)就是一个30 × \times × 2的矩阵。
第二步
第二步是采用新的模型3。其训练集是什么呢?就是第一步得到的(P1,P2)加上每个样本所对应的标签,如果第一步的模型非常好的话,那么得到的P1或者P2应该是非常接近这个标签的。有人可能就会对测试集用求平均的方式来直接(T1+T2)/2,或者带权重的平均来求得结果,但是一般是不如stacking方法的。
将(P1,P2)作为模型3训练集的特征,经过模型3的学习,然后再对测试集上的(T1,T2)做出预测,一般就能得到较好的结果了。
python实现
模型1采用xgboost,模型2采用lightgbm,模型3用贝叶斯分类器。
xgboost
##### xgb
xgb_params = {'eta': 0.005, 'max_depth': 10, 'subsample': 0.8, 'colsample_bytree': 0.8, 'objective': 'reg:linear', 'eval_metric': 'rmse', 'silent': True, 'nthread': 4}#xgb的参数,可以自己改
folds = KFold(n_splits=5, shuffle=True, random_state=2018)#5折交叉验证
oof_xgb = np.zeros(len(train))#用于存放训练集的预测
predictions_xgb = np.zeros(len(test))#用于存放测试集的预测for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):print("fold n°{}".format(fold_+1))trn_data = xgb.DMatrix(X_train[trn_idx], y_train[trn_idx])#训练集的80%val_data = xgb.DMatrix(X_train[val_idx], y_train[val_idx])#训练集的20%,验证集watchlist = [(trn_data, 'train'), (val_data, 'valid_data')]clf = xgb.train(dtrain=trn_data, num_boost_round=20000, evals=watchlist, early_stopping_rounds=200, verbose_eval=100, params=xgb_params)#80%用于训练过程oof_xgb[val_idx] = clf.predict(xgb.DMatrix(X_train[val_idx]), ntree_limit=clf.best_ntree_limit)#预测20%的验证集predictions_xgb += clf.predict(xgb.DMatrix(X_test), ntree_limit=clf.best_ntree_limit) / folds.n_splits#预测测试集,并且取平均print("CV score: {:<8.8f}".format(mean_squared_error(oof_xgb, target)))这样我们就得到了训练集的预测结果oof_xgb这一列,这一列是作为模型3训练集的第一个特征列,并且得到了测试集的预测结果predictions_xgb。
lightgbm
lightgbm和xgboost相似,在此把代码写一下。
##### lgb
param = {'num_leaves': 120,'min_data_in_leaf': 30, 'objective':'regression','max_depth': -1,'learning_rate': 0.01,"min_child_samples": 30,"boosting": "gbdt","feature_fraction": 0.9,"bagging_freq": 1,"bagging_fraction": 0.9 ,"bagging_seed": 11,"metric": 'mse',"lambda_l1": 0.1,"verbosity": -1}#模型参数,可以修改
folds = KFold(n_splits=5, shuffle=True, random_state=2018)#5折交叉验证
oof_lgb = np.zeros(len(train))#存放训练集的预测结果
predictions_lgb = np.zeros(len(test))#存放测试集的预测结果for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):print("fold n°{}".format(fold_+1))trn_data = lgb.Dataset(X_train[trn_idx], y_train[trn_idx])#80%的训练集用于训练val_data = lgb.Dataset(X_train[val_idx], y_train[val_idx])#20%的训练集做验证集num_round = 10000clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=200, early_stopping_rounds = 100)#训练过程oof_lgb[val_idx] = clf.predict(X_train[val_idx], num_iteration=clf.best_iteration)#对验证集得到预测结果predictions_lgb += clf.predict(X_test, num_iteration=clf.best_iteration) / folds.n_splits#对测试集5次取平均值print("CV score: {:<8.8f}".format(mean_squared_error(oof_lgb, target)))
这样我们得到了模型3训练集的又一个特征oof_lgb,还有测试集的又一个特征predictions_lgb 。
贝叶斯分类器
# 将lgb和xgb的结果进行stacking(叠加)
train_stack = np.vstack([oof_lgb,oof_xgb]).transpose()#训练集2列特征
test_stack = np.vstack([predictions_lgb, predictions_xgb]).transpose()#测试集2列特征
#贝叶斯分类器也使用交叉验证的方法,5折,重复2次,主要是避免过拟合
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2018)
oof_stack = np.zeros(train_stack.shape[0])#存放训练集中验证集的预测结果
predictions = np.zeros(test_stack.shape[0])#存放测试集的预测结果#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack,target)):#target就是每一行样本的标签值print("fold {}".format(fold_))trn_data, trn_y = train_stack[trn_idx], target.iloc[trn_idx].values#划分训练集的80%val_data, val_y = train_stack[val_idx], target.iloc[val_idx].values#划分训练集的20%做验证集clf_3 = BayesianRidge()clf_3.fit(trn_data, trn_y)#贝叶斯训练过程,sklearn中的。oof_stack[val_idx] = clf_3.predict(val_data)#对验证集有一个预测,用于后面计算模型的偏差predictions += clf_3.predict(test_stack) / 10#对测试集的预测,除以10是因为5折交叉验证重复了2次mean_squared_error(target.values, oof_stack)#计算出模型在训练集上的均方误差
print("CV score: {:<8.8f}".format(mean_squared_error(target.values, oof_stack)))
这篇关于模型融合中的stacking方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



