本文主要是介绍数据挖掘终篇!一文学习模型融合!从加权融合到stacking, boosting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模型融合:通过融合多个不同的模型,可能提升机器学习的性能。这一方法在各种机器学习比赛中广泛应用, 也是在比赛的攻坚时刻冲刺Top的关键。而融合模型往往又可以从模型结果,模型自身,样本集等不同的角度进行融合。
数据及背景
零基础入门数据挖掘 - 二手车交易价格预测_学习赛_赛题与数据_天池大赛-阿里云天池的赛题与数据(阿里天池-零基础入门数据挖掘)
模型融合
如果你打算买一辆车,你会直接走进第一家4S店,然后在店员的推销下直接把车买了吗?大概率不会,你会先去网站,看看其他人的评价或者一些专业机构在各个维度上对各种车型的对比;也许还会取咨询朋友和同事的意见。最后,做出决策。
模型融合采用的是同样的思想,即多个模型的组合可以改善整体的表现。集成模型是一种能在各种的机器学习任务上提高准确率的强有力技术。
模型融合是比赛后期一个重要的环节,大体来说有如下的类型方式:
1. 简单加权融合:
-
回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
-
分类:投票(Voting);
-
综合:排序融合(Rank averaging),log融合。
2. stacking/blending:
-
构建多层模型,并利用预测结果再拟合预测。
3. boosting/bagging:
-
多树的提升方法,在xgboost,Adaboost,GBDT中已经用到。
平均法(Averaging)
基本思想:对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6。
平均法或加权平均法看似简单,其实后面的高级算法也可以说是基于此而产生的,Bagging或者Boosting都是一种把许多弱分类器这样融合成强分类器的思想。
简单算术平均法:如果公式查看不了,请点击【文章原文】
Averaging方法就多个模型预测的结果进行平均。这种方法既可以用于回归问题,也可以用于对分类问题的概率进行平均。
加权算术平均法:
这种方法是平均法的扩展。考虑不同模型的能力不同,对最终结果的贡献也有差异,需要用权重来表征不同模型的重要性importance。
投票法(voting)
基本思想:假设对于一个二分类问题,有3个基础模型,现在我们可以在这些基学习器的基础上得到一个投票的分类器,把票数最多的类作为我们要预测的类别。
绝对多数投票法:最终结果必须在投票中占一半以上。
相对多数投票法:最终结果在投票中票数最多。
加权投票法:其原理为
硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
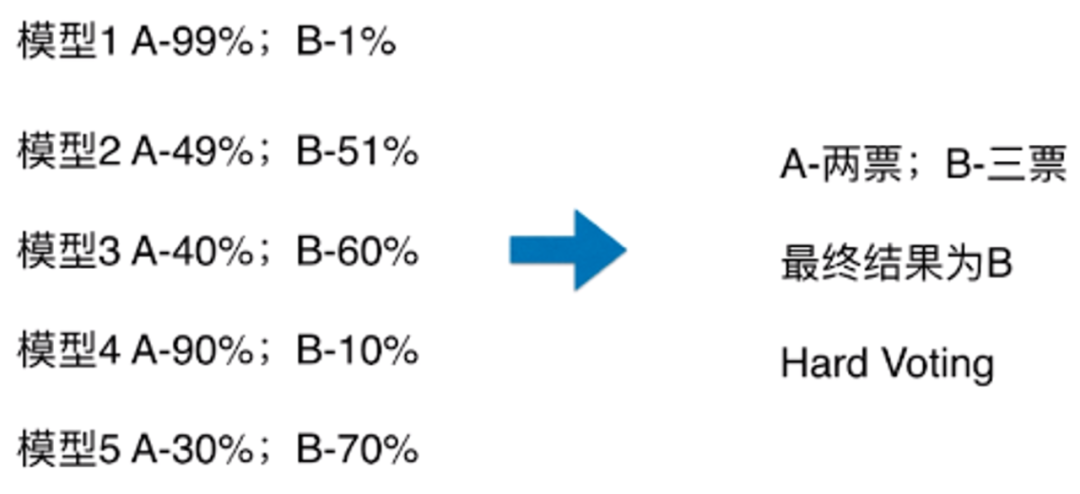
软投票:增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。

from sklearn.tree import DecisionTreeClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import VotingClassifier
model1 = LogisticRegression(random_state=2020)model2 = DecisionTreeClassifier(random_state=2020)model = VotingClassifier(estimators=[('lr', model1), ('dt', model2)], voting='hard')model.fit(x_train, y_train)model.score(x_test, ytest)
<section role="presentation" data-formula="H(\boldsymbol x)=c{arg \max\limitsj\sum{i=1}^Tw_ih_i^j(\boldsymbol x)}
" data-formula-type="block-equation" style="text-align: left;overflow: auto;">
查看本文全部内容,欢迎访问天池技术圈官方地址:数据挖掘终篇!一文学习模型融合!从加权融合到stacking, boosting
这篇关于数据挖掘终篇!一文学习模型融合!从加权融合到stacking, boosting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







